
源码阅读(5):Java中主要的List结构——Stack集合
================
(接上文《源码阅读(4):Java中主要的List结构——ArrayList集合(下)》)
5.java.util.Stack结构解析
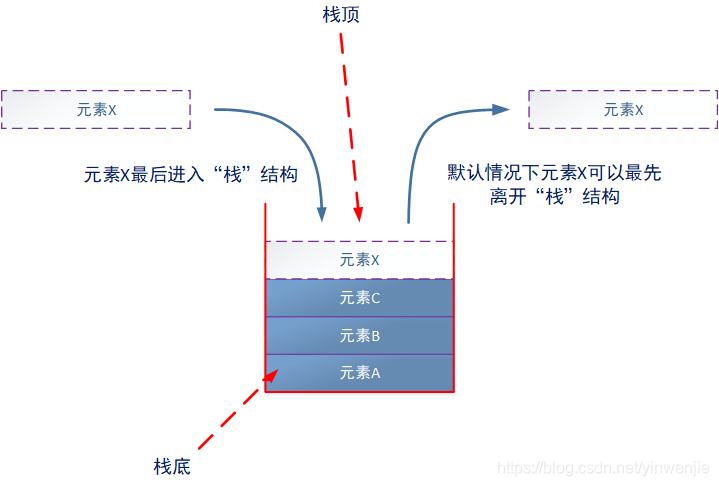
所谓“栈”结构,就是能使集合中的元素具有后进先出(LIFO)操作特性的集合结构,如下图所示:
从最初的的JDK版本开始,就使用java.util.Stack类在程序中实现“栈”结构的操作。下图是java.util.Stack类的主要继承结构,从下图可以看出java.util.Stack类就是继承于java.util.Vector类。也就是说Stack容器除了具有Vector容器的所有操作特性外,还具有作为“栈”结构能够进行的操作功能。例如Stack容器同样有线程安全操作特性(虽然性能不是最好的);Stack容器的扩容同样也是扩容成当前容量的一倍;Stack容器同样也没有对容器的序列化和反序列化做特殊优化……
请注意java.util.Stack类在JDK 1.6+版本后就不再推荐使用的,本文也只是出于学习JDK设计思路、演进思路的目的,才会花篇幅介绍java.util.Stack这个类。在实际工作中,如果需要在无需保证线程安全型的场景下使用“栈”数据结构,那么官方推荐使用的是java.util.ArrayDeque这个类;如果需要在保证线程安全的场景下使用“栈”数据结构,则推荐使用java.util.concurrent.LinkedBlockingDeque这个类,关于这些类本专题在后文都会进行详细说明。
由于Stack类继承Vector类的原因,Stack类的代码真心不多。除去注释外,JDK1.8中Stack类的全部代码如下所示:
public class Stack<E> extends Vector<E> {
/**
* Creates an empty Stack.
*/
public Stack() {
}
public E push(E item) {
addElement(item);
return item;
}
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
public boolean empty() {
return size() == 0;
}
public synchronized int search(Object o) {
int i = lastIndexOf(o);
if (i >= 0) {
return size() - i;
}
return -1;
}
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = 1224463164541339165L;
}
下面本文就对以上这些扩充的重要方法进行详细介绍
5.1. pop方法和peek方法
pop方法将从“栈”结构的顶部移除元素,并将这个元素返回给调用者。peek方法同样会将“栈”结构顶部元素返回给调用者,但并不会从“栈”结构顶部移除这个元素。以下代码片段示意:
/**
* Removes the object at the top of this stack and returns that object as the value of this function.
* @return The object at the top of this stack (the last item of the <tt>Vector</tt> object).
* @throws EmptyStackException if this stack is empty.
*/
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
// 这句话很关键,从数组的尾部移除元数
removeElementAt(len - 1);
return obj;
}
/**
* Looks at the object at the top of this stack without removing it from the stack.
* @return the object at the top of this stack (the last item of the <tt>Vector</tt> object).
* @throws EmptyStackException if this stack is empty.
*/
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
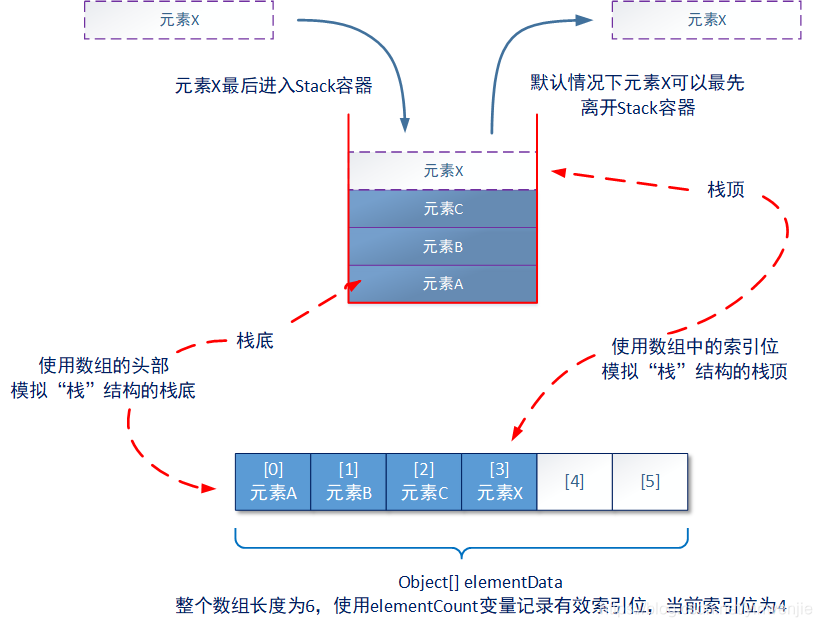
从以上代码片段可以看出,Stack容器内部结构依然是一个数组,程序使用数组的尾部模拟“栈”结构的栈顶,使用数组的头部模拟“栈”结构的栈底。下图是数组和“栈”结构的转换示意图:
5.2. push方法
/**
* Pushes an item onto the top of this stack. This has exactly the same effect as: addElement(item)
* @param item the item to be pushed onto this stack.
* @return the <code>item</code> argument.
* @see java.util.Vector#addElement
*/
public E push(E item) {
addElement(item);
return item;
}
push方法将传入的元素放置在“栈”结构的顶部,使其作为新的“栈顶”元素。注意:由于Stack类使用elementData数组的elementCount索引位模拟“栈顶”位置,所以这个方法的实际操作就是调用Vector类中的addElement(item)方法,在elementCount索引位代表的数组“尾部”添加一个新元素。
5.3. 不建议在实际工作中使用Stack、Vector
Stack和Vector这两个集合存在继承关系,他们在很早的JDK版本中就存在了,其核心设计思想、实现的功能、稳定性都没有任何问题,但本文并不建议读者在实际工作中使用它们。这个主要原因是Stack、Vector的所有主要功能特性都已经被更好的选择所替换了:
-
Stack、Vector虽然是线程安全的,但是它们在线程安全场景下的操作性能又不是最好的——核心原因是因为synchronized关键字总体来说是Java中一种悲观锁的实现(后文会着重讲)思路。同样的数据结构特性下、同样的线程安全性场景下可以由更好的实现类LinkedBlockingDeque、CopyOnWriteArrayList进行替换
-
Stack、Vector也并没有针对序列化/反序列化进行任何的优化。为什么要进行特定优化呢?这个原因在前文已经做了解释——对elementData数组中elementCount索引位以后的空元素进行序列化/反序列操作没有任何意义,只会徒劳消耗性能。而对应的ArrayDeque、ArrayList这两个都对序列化/反序列化操作进行了优化。
-
Stack、Vector本质结构都是一个数组,是数组就存在容量达到上限情况下的扩容操作,但是扩容规则又不是最灵活的——每次将当前容量增大一倍的扩容方式,当容量较小时这种扩容方式的适应性还好;但如果在本身容量基数就较大的情况下(例如5千万),一次性扩充过大的容量容易造成不必要的浪费,JVM也必将耗费更多资源为新的、更大的数组寻找连续的存储空间。而后者所描述的较大容量基数的场景下,ArrayList提供的按照50%(实际上的 50% + 1)的标准进行扩容的方式显得更加灵活。
====================
(接下文《源码阅读(6):Java中主要的List结构——LinkedList集合》)

