软工实践寒假作业 2/2
| 这个作业属于哪个课程 | 2020春|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2)作业要求 |
| 这个作业的目标 | 学习python语法,熟悉软件工程开发流程及文档编写,熟悉git操作 |
| 作业正文 | [本博客] |
| 其他参考文献 | 博客园、CSDN、Python文档 |
一、github仓库地址
二、PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 250 | 200 |
| Analysis | 需求分析 (包括学习新技术) | 480 | 480 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 400 | 500 |
| Code Review | 代码复审 | 30 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | 40 | 50 |
| Test Repor | 测试报告 | 30 | 20 |
| Size Measurement | 计算工作量 | 10 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 5 |
| 合计 | 1490 | 1540 |
三、解题思路
1、解析命令行参数
python利用sys导入argv数组,并做读取与字符串解析
2、解析日志文件并将数据存储到统一管理的数据中心
通过日志的几种形式来写一段匹配的函数,并操作对应省份的数据
3、文件操作
获取数据类的字典,转换为字符串,并输出至对应文件
四、设计实现
1、功能流程图
1、总体流程
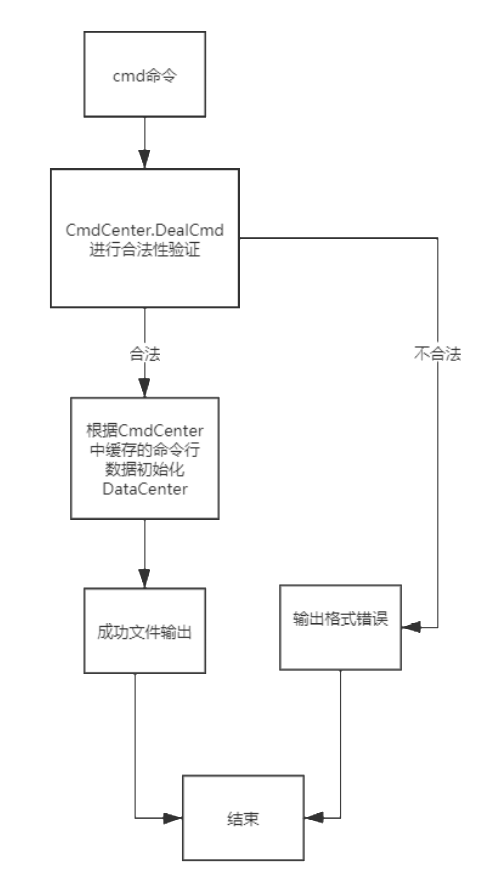
2、CMD流程
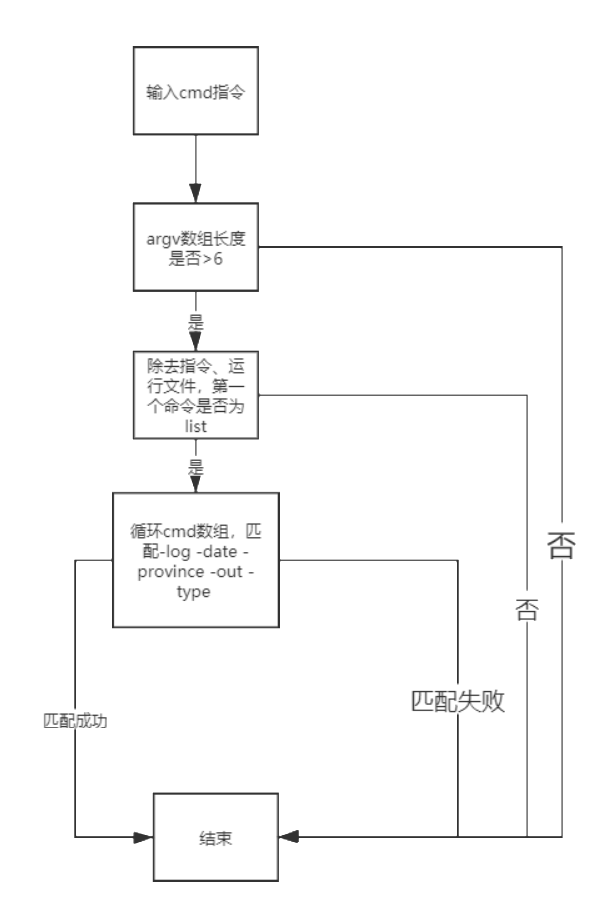
3、数据操作流程

五、代码说明
代码结构
1、核心类
- CmdCenter:用于处理CMd指令,并将命令的数据存下来
class CmdCenter: LogPath = "" OutPath = "" Date = "" Types = [] Provinces = [] def __init__(self): pass def DealCmd(self, argvs): if len(argvs) < 6: return False if argvs[1] != "list": return False checkCount = 0 for i in range(2, len(argvs)-1): if argvs[i] == "-log": checkCount += 1 CmdCenter.LogPath = argvs[i+1] if argvs[i] == "-out": checkCount += 1 CmdCenter.OutPath = argvs[i + 1] if argvs[i] == "-date": CmdCenter.Date = argvs[i+1] if argvs[i] == "-type": for k in range(i+1,len(argvs-1)): if argvs[k][0] == '-': break else: CmdCenter.Types.append(argvs[k]) if argvs[i] == "-province": for k in range(i+1,len(argvs-1)): if argvs[k][0] == '-': break else: CmdCenter.Provinces.append(argvs[k]) if checkCount < 2: return False else: return True - DataCenter:得到cmd的数据后,处理相应的文件夹,将日志数据存到内存的字典中
# 处理所有数据 def DealAllData(self): allFile = os.listdir(self.__private_path) for nowFile in allFile: nowDateStr = nowFile[:-8] nowDate = str2date(nowDateStr) diffDate = self.__private_date - nowDate if diffDate.total_seconds()>0: self.DealFileData(nowFile) # 用于处理一天的数据 def DealFileData(self, fileName): filePath = self.__private_path + "/" + fileName obj = open(filePath, mode='r') fileContent = getFileContent(filePath) allStr = fileContent.split('\n') for str in allStr: self.DealOneLineData(str) obj.close() pass # 处理一行数据 def DealOneLineData(self, lineContent): if isIgnoreLine(lineContent): return words = lineContent.split(" ") if len(words) > 4: province_1 = words[0] if province_1 not in self.__private_allData: obj = ProvinceData() self.__private_allData.setdefault(province_1, obj) province_2 = words[3] if province_2 not in self.__private_allData: obj = ProvinceData() self.__private_allData.setdefault(province_2, obj) count = int(content2Eng(words[len(words) - 1])) if words[1] == "感染患者": self.__private_allData[province_1].__dict__['InfectionCount'] -= count self.__private_allData[province_2].__dict__['InfectionCount'] += count if words[2] == "疑似患者": self.__private_allData[province_1].__dict__['UncertainCount'] -= count self.__private_allData[province_2].__dict__['UncertainCount'] += count else: province_1 = words[0] if province_1 not in self.__private_allData: obj = ProvinceData() self.__private_allData.setdefault(province_1, obj) count = int(content2Eng(words[len(words) - 1])) if words[1] == "死亡": self.__private_allData[province_1].__dict__['DieCount'] += count if words[1] == "治愈": self.__private_allData[province_1].__dict__['CureCount'] += count self.__private_allData[province_1].__dict__['InfectionCount'] -= count if words[1] == "新增": if words[2] == "感染患者": self.__private_allData[province_1].__dict__['InfectionCount'] += count if words[2] == "疑似患者": self.__private_allData[province_1].__dict__['UncertainCount'] += count if words[1] == "疑似患者": self.__private_allData[province_1].__dict__['UncertainCount'] -= count self.__private_allData[province_1].__dict__['InfectionCount'] += count if words[1] == "排除": self.__private_allData[province_1].UncertainCount -= count # 输出数据 def OutputStatistic(self, types, provinces): output = "" if len(types) == 0: types.append("ip") types.append("sp") types.append("cure") types.append("dead") if "全国" in provinces: output += self.CountryInfo() if len(provinces) == 0: provinces = self.__private_allData.keys() output += self.CountryInfo() for province in provinces: if province in self.__private_allData: output += province + " " for nowType in types: # 感染 if nowType == "ip": output += "感染患者" output += str(self.__private_allData[province].__dict__['InfectionCount']) output += "人" # 疑似 if nowType == "sp": output += "疑似患者" output += str(self.__private_allData[province].__dict__['UncertainCount']) output += "人" # 治愈 if nowType == "cure": output += "治愈" output += str(self.__private_allData[province].__dict__['CureCount']) output += "人" # 死亡 if nowType == "dead": output += "死亡" output += str(self.__private_allData[province].__dict__['DieCount']) output += "人" output += " " output += "\n" output += "// 该文档并非真实数据,仅供测试使用" return output - ProvinceData:用于存储各个省份的数据
2、辅助函数
- isIgnoreLine 是否为注释文件
- str2date 字符串转日期
- getFileContent 读取文件中数据
- content2Eng 去除中文
六、单元测试
测试用例
- 仅-log和-out
![]()
![]()
- 无效的-date 参数
![]()
- 多个province
![]()
![]()
- 多个type
![]()
![]()
- -date -type组合查询
![]()
![]()
- -date -province组合查询
![]()
![]()
- -province -type 组合查询
![]()
![]()
- -date -type -province组合查询
![]()
![]()















七、单元测试覆盖率优化和性能测试
利用工具coverage,pytest
(前段时间摸鱼太多,导致后面来不及学了。。单元测试还没来得及看
八、代码规范
九、心路历程
本来想用java做的,想了想...之前想学一学python,干脆趁机学一下python吧。于是花了一天的时间学了下python的基础语法.然后发现,python的类写的很神奇。私有变量竟然是用字典来调用的.然后不带修饰符定义数据成员就是静态数据..不过总的来说,python拿来做这些小工具,还是挺方便的。
总来的说,这次学了PyCharm操作、Python的基本语法、Python的面向对象、文件操作、字符串处理等技术,但是对python还是很不熟悉,对python的进程、lambda、反射等一些高级特性还没涉及到。另外,前段时间摸鱼太多,导致后面来不及学了。。单元测试还没来得及看
十、推荐仓库
pyTest
单元测试插件,html测试报告生成
Pythonic HTML Parsing for Humans
神经网络库 keras
flask

 浙公网安备 33010602011771号
浙公网安备 33010602011771号