

pandas DataFrame apply()函数(2)
上一篇pandas DataFrame apply()函数(1)说了如何通过apply函数对DataFrame进行转换,得到一个新的DataFrame.
这篇介绍DataFrame apply()函数的另一个用法,得到一个新的pandas Series:
apply()中的函数接收的参数为一行(列),把一行(列)通过计算,返回一个值,最后返回一个Series:
下图展示了把DataFrame的各列转换成一个数,最后返回成一个Series:
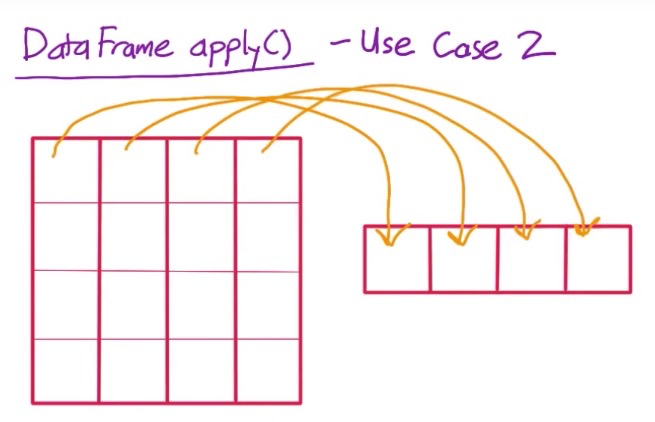
举个栗子:

import numpy as np import pandas as pd df = pd.DataFrame({ 'a': [4, 5, 3, 1, 2], 'b': [20, 10, 40, 50, 30], 'c': [25, 20, 5, 15, 10] })
# 对整个DataFrame应用np.mean()函数,取各列的平均值,返回一个包含了各列平均值的Series print df.apply(np.mean) # 结果: a 3.0 b 30.0 c 15.0 dtype: float64
# 对整个DataFrame应用np.max()函数,取各列的最大值,返回一个包含了各列最大值的Series
print df.apply(np.max)
# 结果: a 5 b 50 c 25 dtype: int64
如果想要返回各列中第二大的数字组成的Series:
def get_second_largest(se): sorted_se = se.sort_values(ascending=False) return sorted_se.iloc[1] def second_largest(df): return df.apply(get_second_largest) print(second_largest(df))
a 4 b 40 c 20 dtype: int64


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2014-07-29 angular学习笔记(二十三)-$http(1)-api