
阅读之数据库分库部署
数据库分库分表后如何部署上线
停机部署法
大致思路就是,挂一个公告,半夜停机升级,然后半夜把服务停了,跑数据迁移程序,进行数据迁移。
步骤如下:
(1)出一个公告,比如“今晚00:00~6:00进行停机维护,暂停服务”
(2)写一个迁移程序,读db-old数据库,通过中间件写入新库db-new1和db-new2,具体如下图所示
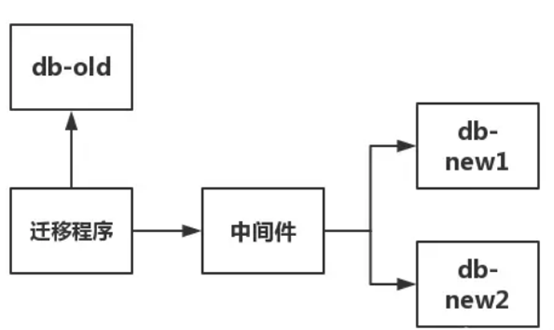
(3)校验迁移前后一致性,没问题就切该部分业务到新库。
顺便科普一下,这个中间件。现在流行的分库分表的中间件有两种,一种是proxy形式的,例如mycat,是需要额外部署一台服务器的。还有一种是client形式的,例如当当出的Sharding-JDBC,就是一个jar包,使用起来十分轻便。我个人偏向Sharding-JDBC,这种方式,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。
双写部署法(一)
这个就是不停机部署法,这里我需要先引进两个概念:历史数据和增量数据。
假设,我们是对一张叫做test_tb的表进行拆分,因为你要进行双写,系统里头和test_tb表有关的业务之前必定会加入一段双写代码,同时往老库和新库中写,然后进行部署,那么
历史数据:在该次部署前,数据库表test_tb的有关数据,我们称之为历史数据。
增量数据:在该次部署后,数据库表test_tb的新产生的数据,我们称之为增量数据。
然后迁移流程如下
(1)先计算你要迁移的那张表的max(主键)。在迁移过程中,只迁移db-old中test_tb表里,主键小等于该max(主键)的值,也就是所谓的历史数据。
这里有特殊情况,如果你的表用的是uuid,没法求出max(主键),那就以创建时间作为划分历史数据和增量数据的依据。如果你的表用的是uuid,又没有创建时间这个字段,我相信机智的你,一定有办法区分出历史数据和增量数据。
(2)在代码中,与test_tb有关的业务,多加一条往消息队列中发消息的代码,将操作的sql发送到消息队列中,至于消息体如何组装,大家自行考虑。需要注意的是,只发写请求的sql,只发写请求的sql,只发写请求的sql。重要的事情说三遍!
原因有二:
(1)只有写请求的sql对恢复数据才有用。
(2)系统中,绝大部分的业务需求是读请求,写请求比较少。
注意了,在这个阶段,我们不消费消息队列里的数据。我们只发写请求,消息队列的消息堆积情况不会太严重!
(3)系统上线。另外,写一段迁移程序,迁移db-old中test_tb表里,主键小于该max(主键)的数据,也就是所谓的历史数据。
上面步骤(1)~步骤(3)的过程如下
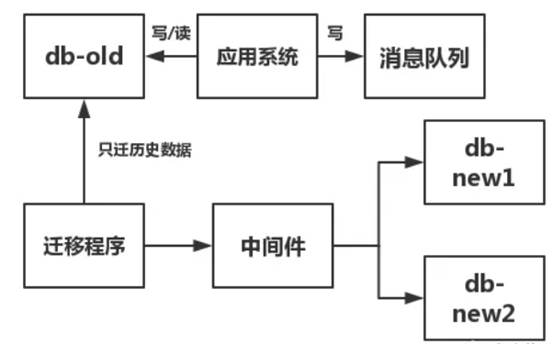
等到db-old中的历史数据迁移完毕,则开始迁移增量数据,也就是在消息队列里的数据。
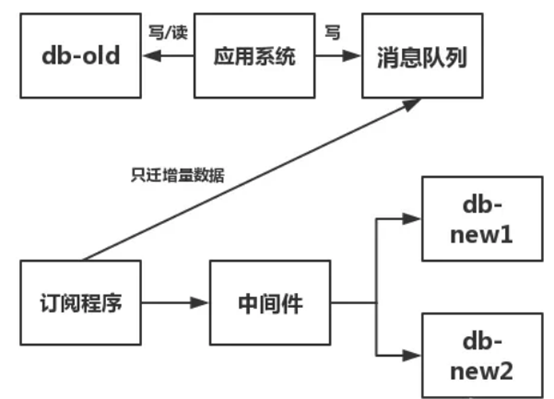
(4)将迁移程序下线,写一段订阅程序订阅消息队列中的数据
(5)订阅程序将订阅到到数据,通过中间件写入新库
(6)新老库一致性验证,去除代码中的双写代码,将涉及到test_tb表的读写操作,指向新库。
上面步骤(4)~步骤(6)的过程如下
这里我们对delete操作和update操作做分析,因为只有这两个操作才会造成历史数据变动,insert进去的数据都是属于增量数据。
(1)对db-old中test_tb表的历史数据发出delete操作,数据还未删除,就被迁移程序给迁走了。此时delete操作在消息队列里还有记录,后期订阅程序订阅到该delete操作,可以进行删除。
(2)对db-old中test_tb表的历史数据发出delete操作,数据已经删除,迁移程序迁不走该行数据。此时delete操作在消息队列里还有记录,后期订阅程序订阅到该delete操作,再执行一次delete,并不会对一致性有影响。
对update的操作类似,不赘述。
怎么验数据一致性
(1)先验数量是否一致,因为验数量比较快。
至于验具体的字段,有两种方法:
(2.1)有一种方法是,只验关键性的几个字段是否一致。
(2.2)还有一种是 ,一次取50条(不一定50条,具体自己定,我只是举例),然后像拼字符串一样,拼在一起。用md5进行加密,得到一串数值。新库一样如法炮制,也得到一串数值,比较两串数值是否一致。如果一致,继续比较下50条数据。如果发现不一致,用二分法确定不一致的数据在0-25条,还是26条-50条。以此类推,找出不一致的数据,进行记录即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号