
Apache Kudu: Hadoop生态系统的新成员实现对快速数据的快速分析
A new addition to the open source Apache Hadoop ecosystem, Apache Kudu completes Hadoop’s storage layer to enable fast analytics on fast data.
开源Apache Hadoop生态系统的新成员,Apache Kudu完善了Hadoop的存储层,以实现对快速数据的快速分析。
Kudu 是 Cloudera 开源的结构化数据的开源存储引擎,是 Apache Hadoop 生态圈的新成员之一,支持低延迟随机访问以及高效的分析访问模式。 Kudu使用水平分区分发数据,并使用 Raft 复制每个分区,提供较低的平均恢复时间和较低的尾部延迟。 Kudu 是在 Hadoop生态系统的环境中设计的,并通过诸如Cloudera Impala ,Apache Spark 和 MapReduce 等工具支持多种访问模式。
Kudu是一种新的存储系统,从头开始设计和实施,以填补HDFS等高吞吐量顺序存取存储系统与HBase或Cassandra等低延迟随机存取系统之间的这种差距。
虽然这些现有系统在某些情况下仍然具有优势,但Kudu提供了一种替代方案,可以大大简化许多常见工作负载的架构。 特别是,Kudu为行级插入,更新和删除提供了一个简单的API,同时提供类似于Parquet的表扫描。
本文主要对 Kudu 的背景以及架构进行简单介绍。
1、背景
1.1、功能上的空白
Hadoop 生态系统有很多组件, 每一个组件有不同的功能。 在现实场景中, 用户往往需要同时部署很多 Hadoop 工具来解决同一个问题, 这种架构称为 混合架构 (hybrid architecture)。 比如,用户需要利用 Hbase 的快速插入、 快读 random access 的特性来导入数据, HBase 也允许用户对数据进行修改, HBase 对于大量小规模查询也非常迅速。同时, 用户使用 HDFS/Parquet + Impala/Hive 来对超大的数据集进行查询分析, 对于这类场景, Parquet 这种列式存储文件格式具有极大的优势。
很多公司都部署了 HDFS/Parquet + HBase 混合架构,然而这种架构较为复杂,维护上也十分困难。首先,用户需要使用Flume 或 Kafka 等数据Ingest工具将数据导入HBase,用户可能会在HBase上对数据做一些修改,然后每隔一段时间将数据从HBase 导入到 Parquet 文件,作为一个新的partition 放在 HDFS 上,最后使用Impala 等计算引擎进行查询,最终生成报表。

这样一条工具链繁琐而复杂,而且还存在很多问题,比如:
1、如何处理某一过程失败?
2、从HBase将数据导出到文件,频率多少比较合适?
3、当生产报表时,最近的数据如何体现在查询结果上?
4、维护集群时,如何保证关键任务不失败?
5、Parquet 是 immutable 的,因此当HBase 中数据变更时,往往需要人工干预同步
这个时候,用户就希望能够有一种优雅的存储解决方案,来应付不同类型的工作流程,并保持高性能的计算能力。Cloudera 很早就意识到这个问题,在2012年开始计划开发Kudu这个存储系统,在2015年发布并开源。Kudu 是对HDFS 和 HBase 功能上的补充,能提供快速的分析和实时计算能力,并且充分利用CPU 和 I/O 资源,支持数据源的修改,支持简单的、可扩展的数据模型。
1.2、新硬件设备的发展
RAM的技术发展非常快,它变得越来越便宜,容量也越来越大。Cloudera的客户数据显示,他们的客户所部署的服务器,2012年每个节点仅有32GB RAM,现如今增长到每个节点有128GB或256GB RAM。存储设备上更新也非常快,在很多普通服务器中部署SSD也是屡见不鲜。HBase、HDFS、以及其他的Hadoop工具都在不断自我完善,从而适应硬件上的升级换代。然而,从根本上,HDFS基于03年GFS,HBase基于05年BigTable,在当时系统瓶颈主要取决于底层磁盘速度。当磁盘速度较慢时,CPU利用率不足的根本原因是磁盘速度导致的瓶颈,当磁盘速度提高了之后,CPU利用率提高,这时候CPU往往成为系统的瓶颈。HBase、HDFS由于年代久远,已经很难从基本架构上进行修改,而Kudu是基于全新的设计,因此可以更充分地利用RAM、I/O资源,并优化CPU利用率。我们可以理解为,Kudu相比与以往的系统,CPU使用降低了,I/O的使用提高了,RAM的利用更充分了。
2、简介
Kudu设计之初,是为了解决一下问题:
1、对数据扫描(scan)和随机访问(random access)同时具有高性能,简化用户复杂的混合架构
2、高CPU效率,使用户购买的先进处理器的的花费得到最大回报
3、高IO性能,充分利用先进存储介质
4、支持数据的原地更新,避免额外的数据处理、数据移动
5、支持跨数据中心replication
Kudu的很多特性跟HBase很像,它支持索引键的查询和修改。Cloudera曾经想过基于Hbase进行修改,然而结论是对HBase的改动非常大,Kudu的数据模型和磁盘存储都与Hbase不同。HBase本身成功的适用于大量的其它场景,因此修改HBase很可能吃力不讨好。最后Cloudera决定开发一个全新的存储系统。
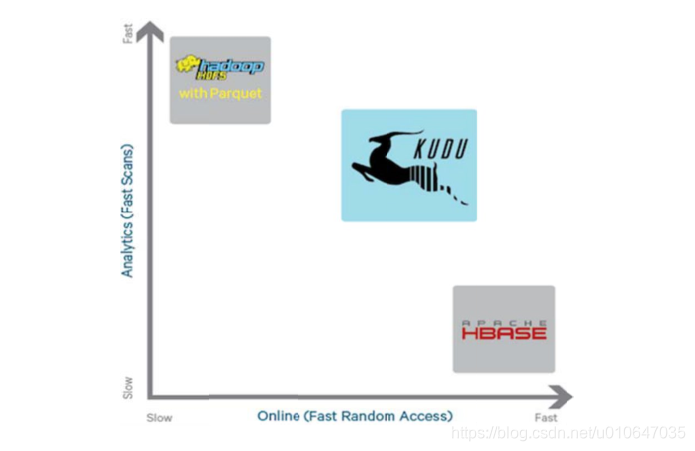
Kudu的定位是提供”fast analytics on fast data”,也就是在快速更新的数据上进行快速的查询。它定位OLAP和少量的OLTP工作流,如果有大量的random accesses,官方建议还是使用HBase最为合适。
3、架构与设计
3.1、基本框架
Kudu是用于存储结构化(structured)的表(Table)。表有预定义的带类型的列(Columns),每张表有一个主键(primary key)。主键带有唯一性(uniqueness)限制,可作为索引用来支持快速的random access。
类似于BigTable,Kudu的表是由很多数据子集构成的,表被水平拆分成多个Tablets. Kudu用以每个tablet为一个单元来实现数据的durability。Tablet有多个副本,同时在多个节点上进行持久化。
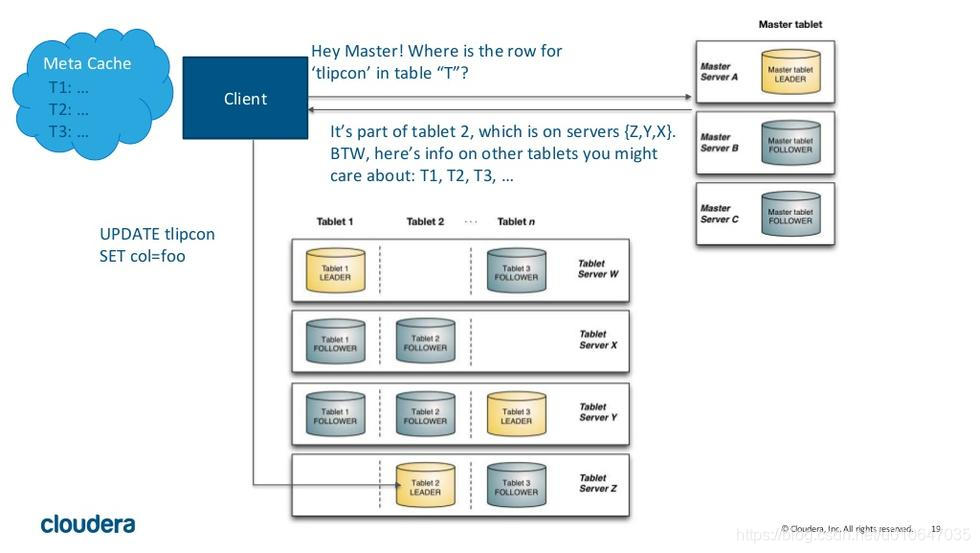
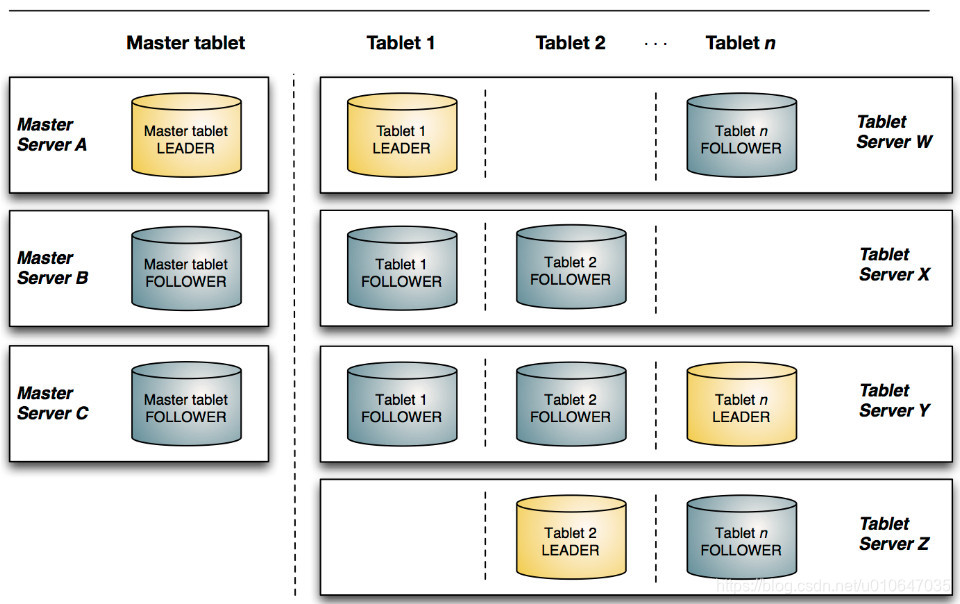
Kudu有两种类型的组件,Master Server和Tablet Server。Master负责管理元数据。这些元数据包括talbet的基本信息,位置信息。Master还作为负载均衡服务器,监听Tablet Server的健康状态。对于副本数过低的Tablet,Master会在起replication任务来提高其副本数。Master的所有信息都在内存中cache,因此速度非常快。每次查询都在百毫秒级别。Kudu支持多个Master,不过只有一个active Master,其余只是作为灾备,不提供服务。
Tablet Server上存了10~100个Tablets,每个Tablet有3(或5)个副本存放在不同的Tablet Server上,每个Tablet同时只有一个leader副本,这个副本对用户提供修改操作,然后将修改结果同步给follower。Follower只提供读服务,不提供修改服务。副本之间使用raft协议来实现High Availability,当leader所在的节点发生故障时,followers会重新选举leader。根据官方的数据,其MTTR约为5秒,对client端几乎没有影响。Raft协议的另一个作用是实现Consistency。Client对leader的修改操作,需要同步到N/2+1个节点上,该操作才算成功。
Kudu 采用了类似 log-structured 存储系统的方式,增删改操作都放在内存中的 buffer ,然后才 merge 到持久化的列式存储中。 Kudu 还是用了 WALs 来对内存中的 buffer 进行灾备。
3.2、列式存储
持久化的列式存储存储,与 HBase 完全不同,而是使用了类似 Parquet 的方式,同一个列在磁盘上是作为一个连续的块进行存放的。例如,图中左边是 twitter 保存推文的一张表,而图中的右边表示了表在磁盘中的的存储方式,也就是将同一个列放在一起存放。这样做的第一个好处是,对于一些聚合和 join 语句,我们可以尽可能地减少磁盘的访问。例如,我们要用户名为 newsycbot
的推文数量,使用查询语句:
SELECT COUNT(*) FROM tweets WHERE user_name = ‘newsycbot’
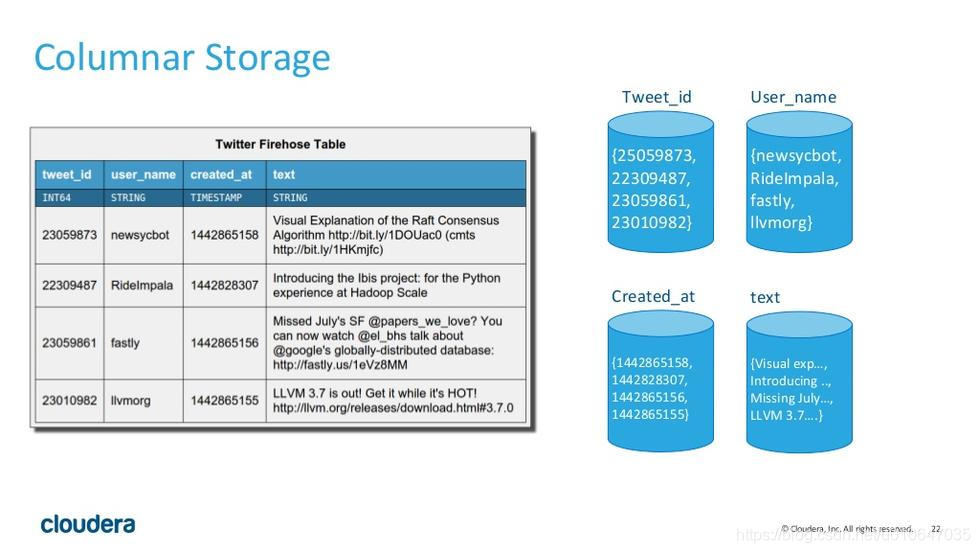
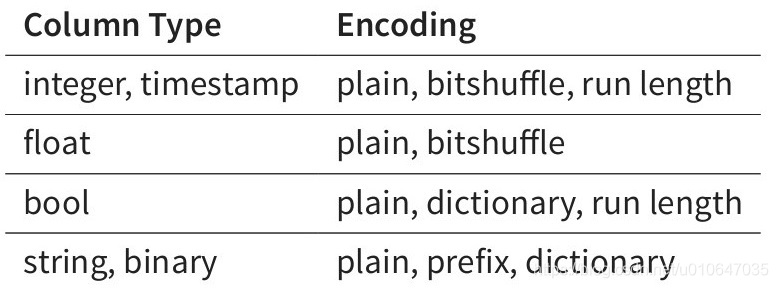
我们只需要查询 User_name 这个 block 即可。同一个列的数据是集中的,而且是相同格式的, Kudu 可以对数据进行编码,例如字典编码,行长编码, bitshuffle 等。通过这种方式可以很大的减少数据在磁盘上的大小,提高吞吐率。除此之外,用户可以选择使用通用的压缩格式对数据进行压缩,如 LZ4, gzip, 或 bzip2 。这是可选的,用户可以根据业务场景,在数据大小和 CPU 效率上进行权衡。这一部分的实现上, Kudu 很大部分借鉴了 Parquet 的代码。
HBase 支持 snappy 存储,然而因为它的 LSM 的数据存储方式,使得它很难对数据进行特殊编码,这也是 Kudu 声称具有很快的 scan 速度的一个很重要的原因。不过,因为列式编码后的数据很难再进行修改,因此当这写数据写入磁盘后,是不可变的,这部分数据称之为 base 数据。 Kudu 用 MVCC (多版本并发控制)来实现数据的删改功能。更新、删除操作需要记录到特殊的数据结构里,保存在内存中的 DeltaMemStore 或磁盘上的 DeltaFIle 里面。 DeltaMemStore 是 B-Tree 实现的,因此速度快,而且可修改。磁盘上的 DeltaFIle 是二进制的列式的块,和 base 数据一样都是不可修改的。因此当数据频繁删改的时候,磁盘上会有大量的 DeltaFiles 文件, Kudu 借鉴了 Hbase 的方式,会定期对这些文件进行合并。
3.3、对外接口
Kudu 提供 C++ 、 JAVA API 、Python API,可以进行单条或批量的数据读写, schema 的创建修改。除此之外, Kudu 还将与 hadoop 生态圈的其它工具进行整合。目前, kudu 对 Impala 支持较为完善,支持用 Impala 进行创建表、删改数据等大部分操作。 Kudu 还实现了 KuduTableInputFormat 和 KuduTableOutputFormat ,从而支持 Mapreduce 的读写操作。同时支持数据的 locality 和 spark 的集成。
Kudu提供了与如下系统的集成:
MapReduce: 提供针对Kudu用户表的Input以及Output任务对接。
Spark: 提供与Spark SQL以及DataFrames的对接。
Impala: Kudu自身未提供Shell以及SQL Parser,它的SQL能力源自与Impala的集成。在这些集成中,能够很好的感知Kudu表数据的本地性信息,能够充分利用Kudu所提供的过滤器对查询进行优化,同时,Impala本身的DDL/DML语法针对Kudu也做了一些扩展
3.4、Kudu的底层数据模型
Kudu的底层数据文件的存储,没有采用HDFS这样的较高抽象层次的分布式文件系统,而是自行开发了一套可基于Table/Tablet/Replica视图级别的底层存储系统。这套实现基于如下的几个设计目标:
1、可提供快速的列式查询。
2、可支持快速的随机更新
3、可提供更为稳定的查询性能保障。
为了实现如上目标,Kudu参考了一种类似于Fractured Mirrors的混合列存储架构。Tablet在底层被进一步细分成了一个称之为RowSets的单元
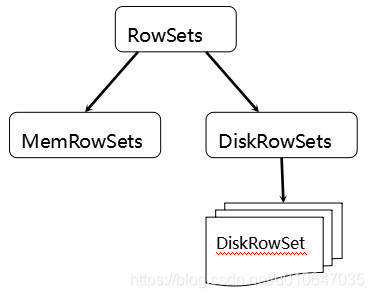
MemRowSets 可以理解成HBase中的MemStore,DiskRowSets可理解成HBase中的HFile。
MemRowSets中的数据按照行试图进行存储,数据结构为B-Tree。MemRowSets中的数据被Flush到磁盘之后,形成DiskRowSets。 DisRowSets中的数据,按照32MB大小为单位,按序划分为一个个的DiskRowSet。
DiskRowSet中的数据按照Column进行组织,与Parquet类似。这是Kudu可支持一些分析性查询的基础。每一个Column的数据被存储在一个相邻的数据区域,而这个数据区域进一步被细分成一个个的小的Page单元,与HBase File中的Block类似,对每一个Column Page可采用一些Encoding算法,以及一些通用的Compression算法。
既然可对Column Page可采用Encoding以及Compression算法,那么,对单条记录的更改就会比较困难了。
前面提到了Kudu可支持单条记录级别的更新/删除,是如何做到的呢?
与HBase类似,是通过增加一条新的记录来描述这次更新/删除操作的。一个DiskRowSet包含两部分数据:基础数据(Base Data),以及变更数据(Delta Stores)。更新/删除操作所生成的数据记录,被保存在变更数据部分。
图源自Kudu的源工程文件
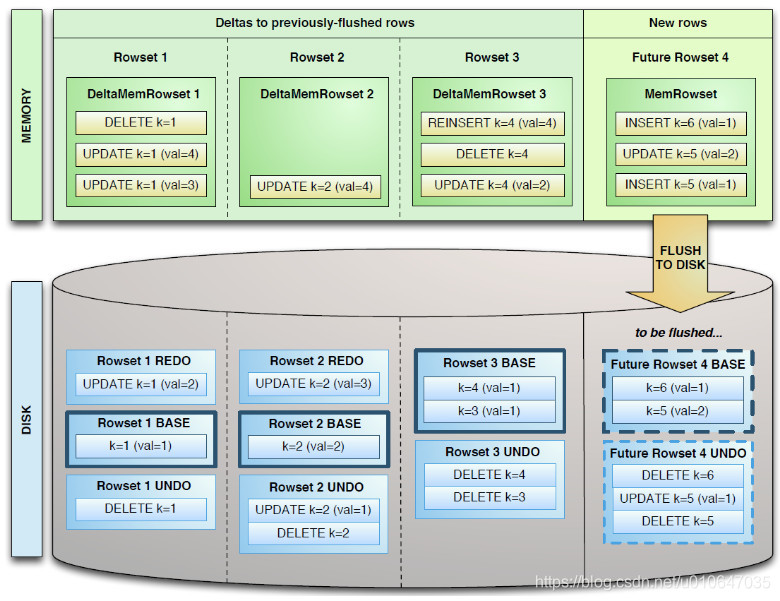
从上图来看,Delta数据部分应该包含REDO与UNDO两部分,这里的REDO与UNDO与关系型数据库中的REDO与UNDO日志类似(在关系型数据库中,REDO日志记录了更新后的数据,可以用来恢复尚未写入Data File的已成功事务更新的数据。 而UNDO日志用来记录事务更新之前的数据,可以用来在事务失败时进行回滚),但也存在一些细节上的差异:
REDO Delta Files包含了Base Data自上一次被Flush/Compaction之后的变更值。
REDO Delta Files按照Timestamp顺序排列,UNDO Delta Files包含了Base Data自上一次Flush/Compaction之前的变更值。这样才可以保障基于一个旧Timestamp的查询能够看到一个一致性视图。
UNDO按照Timestamp倒序排列。
3.5、Kudu 数据读写流程
3.5.1、Kudu 数据写流程
Kudu不允许用户数据的Primary Key重复,因此,在Tablet内部写入数据之前,需要先从已有的数据中检查当前新写入的数据的Primary Key是否已经存在,尽管在DiskRowSets中增加了BloomFilter来提升这种判断的效率,但可以预见,Kudu的这种设计将会明显增大写入的时延。
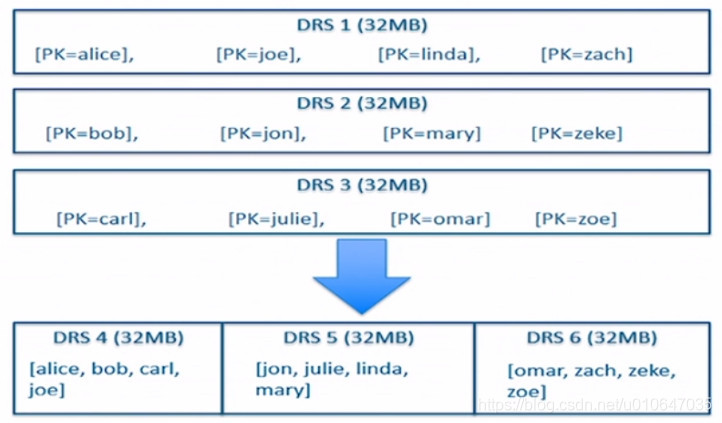
数据一开始先存放于MemRowSets中,待大小超出一定的阈值之后,再Flush成DiskRowSets。随着Flush次数的不断增加,生成的DiskRowSets也会不断的增多,在Kudu内部也存在一个Compaction流程,这样可以将已经存在的多个 Primary Key 交集的DiskRowSets重新排序而生成一个新的DiskRowSets。如下图所示:
3.5.2、Kudu 数据读流程
读数据的流程,既要考虑存在于内存中的MemRowSets,又要读取位于磁盘中的一个或多个DiskRowSets,在Scanner的高层抽象中,应该与HBase类似。
重点说一些细节的优化点:
1、通过Scan的范围,与每一个DiskRowSets中的Primary Key Range进行对比,可以首先过滤掉一些不必要参与此次Scan的DiskRowSets。
2、Delta Store部分,针对记录级别的更改,记录了Base Data中对应原始数据的Offset。这样,在判断一条记录是否存在更改的记录时,将会更加的快速。
3、由于DiskRowSets的底层文件是按照列组织的,基于一些列的条件进行过滤查询时,可以优先过滤掉一些不必要的Primary Keys。Kudu并不会在一开始读取的时候就将一行数据的所有列读取出来,而是先读取与过滤条件相关的列,通过将这些列与查询条件匹配之后,再来决定是否去读取符合条件的行中的其它的列信息。这样可以节省一些磁盘IO。这就是Kudu所提供的Lazy Materialization特性。
##### 3.6、Raft模型
Kudu的多副本之间的数据共识协议采用了Raft协议,Raft是比Paxos更容易理解且更简单的一种一致性协议。
关于Raft的更多信息,请参考:https://raft.github.io/
4、Kudu 与 HBase 区别
Tablet与HBase中的Region大致相似,但存在如下一些明显的区别点:
Tablet包含两种分区策略,一种是基于Hash Partition方式,在这种分区方式下用户数据可较均匀的分布在各个Tablet中,但原来的数据排序特点已被打乱。
另外一种是基于Range Partition方式,数据将按照用户数据指定的有序的Primary Key Columns的组合String的顺序进行分区。而HBase中仅仅提供了一种按用户数据RowKey的Range Partition方式。
一个Tablet可以被部署到了多个Tablet Server中。
在HBase最初的架构中,一个Region只能被部署在一个RegionServer中,它的数据多副本交由HDFS来保障。从1.0版本开始,HBase有了Region Replica(HBASE-10070)特性,该特性允许将一个Region部署在多个RegionServer中来提升读取的可用性,但多Region副本之间的数据却不是实时同步的。
Kudu的数据多副本机制
HBase的数据多副本机制
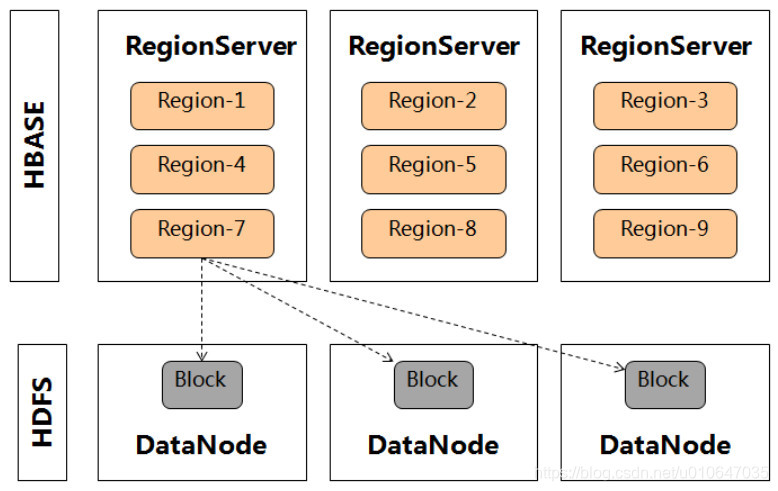
1、Kudu的数据分区方式相对多样化,而HBase较单一。
2、Kudu的Tablet自身具备多副本机制,而HBase的Region依赖于底层HDFS的多副本机制。
3、Kudu底层直接采用本地文件系统, 而HBase依赖于HDFS。
4、Kudu的底层文件格式采用了类似于Parquet的列式存储格式,而HBase的底层HFile文件却是按行来组织的。
5、Kudu关于底层的Flush任务以及Compaction任务,能够结合忙时或者闲时进行自动的调整。HBase还尚不具备这种调度能力。
6、Kudu的Compaction无Minor/Major的区分,限制每一次Compaction的IO总量在128MB大小,因此,并不存在长久执行的Compaction任务。 Compaction是按需进行的,例如,如果所有的写入都是顺序写入,则将不会触发Compaction。
7、Kudu的设计,既兼顾了分析型的查询能力,又兼顾了随机读写能力,这样,势必也会付出一些代价。 例如,写入数据时关于Primary Key唯一性的限制,就要求写入前要检查对应的Primary Key是否已经存在,这样势必会增大写入的时延。而底层尽管采用了类似于Parquet的列式文件设计,但与HBase类似的冗长的读取路径,也会对分析性的查询带来一些影响。另外,这种设计在整行读取时,也会付出较高的代价。
5、Kudu的适用场景
5.1、具有近实时可用性的流输入
数据分析中的一个共同挑战是新数据快速且持续地到达,并且需要几乎实时地提供相同的数据以进行读取,扫描和更新。 Kudu提供快速插入和更新的强大组合,以及高效的柱状扫描,以在单个存储层上实现实时分析用例。
5.2、具有各种访问模式的时间序列应用程序
时间序列模式是根据数据点发生的时间组织和键入数据点的模式。 这对于调查指标随时间的性能或尝试根据过去的数据预测未来行为非常有用。 例如,时间序列客户数据既可用于存储购买点击流历史记录,也可用于预测未来购买或供客户支持代表使用。 虽然这些不同类型的分析正在发生,但插入和突变也可能单独和大量发生,并且可立即用于读取工作负载。 Kudu可以以可扩展且高效的方式同时处理所有这些访问模式。
由于多种原因,Kudu非常适合时间序列工作负载。 由于Kudu支持基于散列的分区,结合其对复合行密钥的原生支持,可以很容易地设置跨多个服务器的表,而不存在使用范围分区时常见的“热点”风险。 Kudu的柱状存储引擎在这种情况下也很有用,因为许多时间序列工作负载只读取几列,而不是整行。
过去,您可能需要使用多个数据存储来处理不同的数据访问模式。 这种做法增加了应用程序和操作的复杂性,并使数据重复,使所需的存储量翻倍(或更差)。 Kudu可以本地高效地处理所有这些访问模式,而无需将工作卸载到其他数据存储。
5.3、预测建模
数据科学家经常从大量数据开发预测性学习模型。 当学习发生或建模的情况发生变化时,可能需要经常更新或修改模型和数据。 此外,科学家可能想要改变模型中的一个或多个因素,看看随着时间的推移会发生什么。 更新存储在HDFS中的文件中的大量数据是资源密集型的,因为每个文件都需要完全重写。 在Kudu,更新几乎是实时发生的。 科学家可以调整值,重新运行查询,并在几秒或几分钟内刷新图表,而不是几小时或几天。 此外,批处理或增量算法可以随时跨数据运行,并具有接近实时的结果。
5.4、将Kudu中的数据与遗留系统相结合
公司从多个来源生成数据并将其存储在各种系统和格式中。 例如,您的一些数据可能存储在Kudu中,一些存储在传统的RDBMS中,一些存储在HDFS中的文件中。 您可以使用Impala访问和查询所有这些源和格式,而无需更改旧系统。
6、Spark 与 Kudu 集成已知问题和限制
- 尽管Kudu Spark 2.x集成与Java 7兼容,但Spark 2.2+ 以后在运行时需要Java 8。Spark 2.2 是Kudu 1.5.0 的默认依赖版本。
- 当注册为临时表时,名称必须为包含大写或非ascii字符
- 包含大写或非ascii字符的列名的Kudu表不能与SparkSQL一起使用。 可以在Kudu中重命名列以解决此问题。
- <>和OR谓词不会被推送到Kudu,而是由Spark任务评估。
- 只有具有后缀通配符的LIKE谓词被推送到Kudu,这意味着LIKE“FOO%”会被推,但LIKE“FOO%BAR”则不会。
- Kudu不支持Spark SQL支持的每种类型。 例如,不支持日期和复杂类型。
- Kudu表只能在SparkSQL中注册为临时表。 使用HiveContext可能无法查询Kudu表。
7、性能测试
7.1、Kudu 与 Parquet 对比
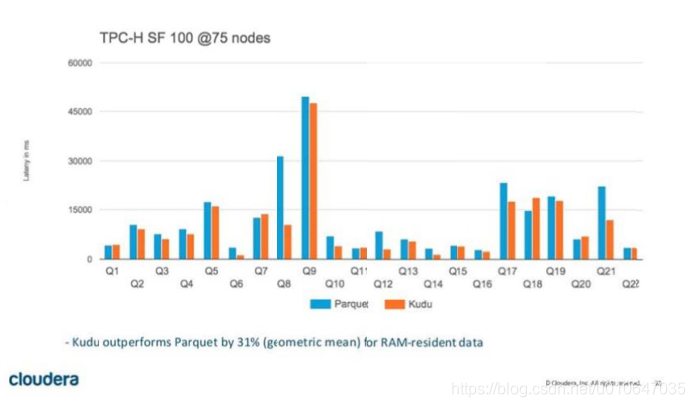
图是官方给出的用 Impala 跑 TPC-H 的测试,对比 Parquet 和 Kudu 的计算速度。从图中我们可以发现, Kudu 的速度和 parquet 的速度差距不大,甚至有些 Query 比 parquet 还快。然而,由于这些数据都是在内存缓存过的,因此该测试结果不具备参考价值。
7.2、Kudu 与 Hbase 对比
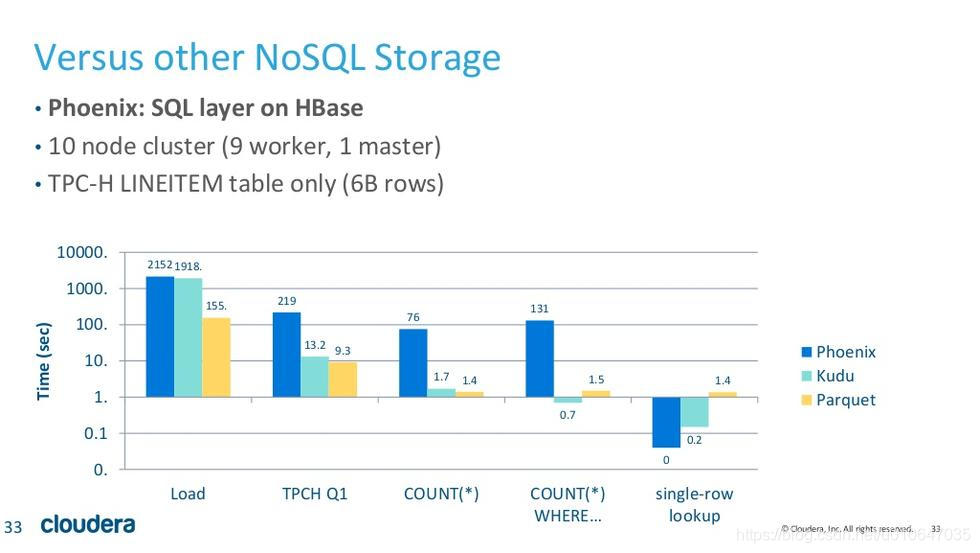
图是官方给出的另一组测试结果,从图中我们可以看出,在 scan 和 range 查询上, kudu 和 parquet 比 HBase 快很多,而 random access 则比 HBase 稍慢。然而数据集只有 60 亿行数据,所以很可能这些数据也是可以全部缓存在内存的。对于从内存查询,除了 random access 比 HBase 慢之外, kudu 的速度基本要优于 HBase
7.3. 超大数据集的查询性能
Kudu 的定位不是 in-memory database 。因为它希望 HDFS/Parquet 这种存储,因此大量的数据都是存储在磁盘上。如果我们想要拿它代替 HDFS/Parquet + HBase ,那么超大数据集的查询性能就至关重要,这也是 Kudu 的最初目的。然而,官方没有给出这方面的相关数据。
Kudu 参考资料
Documentation:官方文档永远是学习开源项目的最好去处。
Paper:Kudu的论文可以帮助您深入了解Kudu的设计思想。
Raft协议:Kudu的一致性协议使用了Raft协议,了解Raft协议可以帮助您更好地了解Kudu及其他分布式开源系统。

