Socket与内核调用深度分析
一、socket api和系统调用关系
1.为什么有核心态和用户态
在Linux中程序运行在两个状态,内核态和用户态。在逻辑上,两个空间相互隔离,因此用户程序不能够访问内核数据,也无法直接调用内核函数。因此当用户因为某项工作必须要使用到某个内核函数时,就要用到系统调用。在Linux系统中,系统调用是用户空间访问内核空间的唯一途径
2.什么是系统调用
从上一个问题的解释中,我们可以看到系统调用是用户访问系统内核的唯一方式,通俗的将,系统调用就是一种特殊的接口。通过这个接口,用户可以访问到内核空间。
可以看出,系统调用只是用户进程进入内核的接口层,但其本省并不是内核函数。
进入内核后,不同的系统调用号会找到各自对应的内核函数,这些内核函数被称为系统调用的“服务例程”。
3.API是什么
API-Application Programming interface,用户程序接口。通常意义上说的API并不像他的名字一样高大上。API说白了就是一些给定的服务,跟内核没有必然的联系。提供应用程序与开发人员基于某软件或者硬件的访问一组例程的能力,而无需了解其内部工作细节
4.API和系统调用有什么区别
API是函数的定义,规定了某个函数的功能,和内核无直接关系。
系统调用是通过中断向内核发出请求,实现内核提供的某些服务。
5.特殊情况
某些API所提供的功能会涉及到与内核空间进行交互。那么,这类API内部会封装系统调用。而不涉及与内核进行交互的API则不会封装系统调用。也就是说,API和系统调用并没有严格的一一对应关系,一个API可能恰好只对应一个系统调用,比如read()系统调用和read();一个API也可能由多个系统调用实现;有时候,一个API的功能可能并不需要内核提供的服务,那么此时这个API也就不需要任何的系统调用,比如abs()。另外,一个系统调用可能还被多个API内部调用。
对于编程者来说,系统调用和API都是一组函数,并无什么两样,二者关注的都是函数名、参数类型及返回值的含义;但是事实上,系统调用的实现是在内核完成的,API则是在函数库中实现的
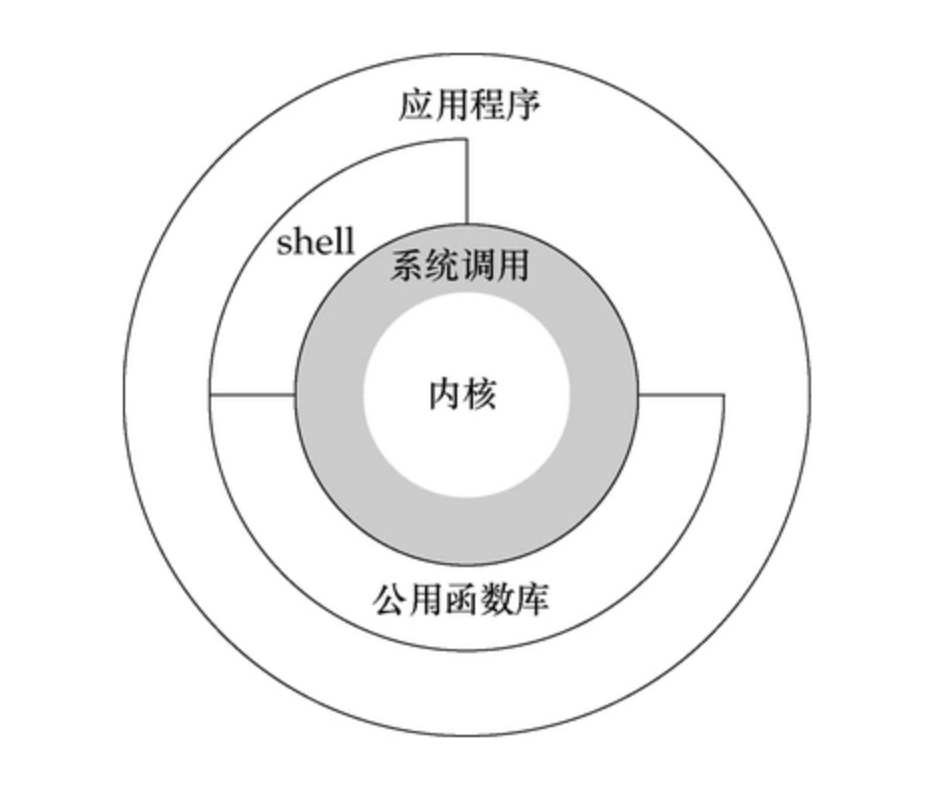
6.图解
我们可以用下面这个图来概括它们之间的关系
二.用户态到核心态的转换
用户态切换到内核态的3种方式
系统调用: 这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断。
异常: 当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
外围设备的中断: 当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。
三.Socket创建过程分析
在用户进程中,socket(int domain, int type, int protocol) 函数用于创建socket并返回一个与socket关联的fd,该函数实际执行的是系统调用 sys_socketcall,sys_socketcall几乎是用户进程socket所有操作函数的入口:
/** sys_socketcall (linux/syscalls.h)*/ asmlinkage long sys_socketcall(int call, unsigned long __user *args);
sys_socketcall 实际调用的是 SYSCALL_DEFINE2:
/** SYSCALL_DEFINE2 (net/socket.c)*/ SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args) { unsigned long a[AUDITSC_ARGS]; unsigned long a0, a1; int err; unsigned int len; // 省略... a0 = a[0]; a1 = a[1]; switch (call) { case SYS_SOCKET: // 与 socket(int domain, int type, int protocol) 对应,创建socket err = sys_socket(a0, a1, a[2]); break; case SYS_BIND: err = sys_bind(a0, (struct sockaddr __user *)a1, a[2]); break; case SYS_CONNECT: err = sys_connect(a0, (struct sockaddr __user *)a1, a[2]); break; // 省略... }
在 SYSCALL_DEFINE2 函数中,通过判断call指令,来统一处理 socket 相关函数的事务,对于socket(…)函数,实际处理是在 sys_socket 中,也是一个系统调用,对应的是 SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol):
/** SYSCALL_DEFINE3 net/socket.c*/ SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol) { int retval; struct socket *sock; int flags; // SOCK_TYPE_MASK: 0xF; SOCK_STREAM等socket类型位于type字段的低4位 // 将flag设置为除socket基本类型之外的值 flags = type & ~SOCK_TYPE_MASK; // 如果flags中有除SOCK_CLOEXEC或者SOCK_NONBLOCK之外的其他参数,则返回EINVAL if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK)) return -EINVAL; // 取type中的后4位,即sock_type,socket基本类型定义 type &= SOCK_TYPE_MASK; // 如果设置了SOCK_NONBLOCK,则不论SOCK_NONBLOCK定义是否与O_NONBLOCK相同, // 均将flags中的SOCK_NONBLOCK复位,将O_NONBLOCK置位 if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK)) flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK; // 创建socket结构,(重点分析) retval = sock_create(family, type, protocol, &sock); if (retval < 0) goto out; if (retval == 0) sockev_notify(SOCKEV_SOCKET, sock); // 将socket结构映射为文件描述符retval并返回,(重点分析) retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK)); if (retval < 0) goto out_release; out: return retval; out_release: sock_release(sock); return retval; }
SYSCALL_DEFINE3 中主要判断了设置的socket类型type,如果设置了除基本sock_type,SOCK_CLOEXEC和SOCK_NONBLOCK之外的其他参数,则直接返回;同时调用 sock_create 创建 socket 结构,使用 sock_map_fd 将socket 结构映射为文件描述符并返回。在分析 sock_create 之前,先看看socket结构体:
/** socket结构体 (linux/net.h)*/ struct socket { socket_state state; // 连接状态:SS_CONNECTING, SS_CONNECTED 等 short type; // 类型:SOCK_STREAM, SOCK_DGRAM 等 unsigned long flags; // 标志位:SOCK_ASYNC_NOSPACE(发送队列是否已满)等 struct socket_wq __rcu *wq; // 等待队列 struct file *file; // 该socket结构体对应VFS中的file指针 struct sock *sk; // socket网络层表示,真正处理网络协议的地方 const struct proto_ops *ops; // socket操作函数集:bind, connect, accept 等 };
socket结构体中定义了socket的基本状态,类型,标志,等待队列,文件指针,操作函数集等,利用 sock 结构,将 socket 操作与真正处理网络协议相关的事务分离。
回到 sock_create 继续看socket创建过程,sock_create 实际调用的是 __sock_create:
/** __sock_create (net/socket.c)*/ int __sock_create(struct net *net, int family, int type, int protocol, struct socket **res, int kern) { int err; struct socket *sock; const struct net_proto_family *pf; // 检查是否是支持的地址族,即检查协议 if (family < 0 || family >= NPROTO) return -EAFNOSUPPORT; // 检查是否是支持的socket类型 if (type < 0 || type >= SOCK_MAX) return -EINVAL; // 省略... // 检查权限,并考虑协议集、类型、协议,以及 socket 是在内核中创建还是在用户空间中创建 // 可以参考:https://www.ibm.com/developerworks/cn/linux/l-selinux/ err = security_socket_create(family, type, protocol, kern); if (err) return err; // 分配socket结构,这其中创建了socket和关联的inode (重点分析) sock = sock_alloc(); if (!sock) { net_warn_ratelimited("socket: no more sockets\n"); return -ENFILE; /* Not exactly a match, but its the closest posix thing */ } sock->type = type; // 省略... }
__socket_create 检查了地址族协议和socket类型,同时,调用 security_socket_create 检查创建socket的权限(如:创建不同类型不同地址族socket的SELinux权限也会不同)。接着,来看看 sock_alloc:
/** sock_alloc (net/socket.c)*/ static struct socket *sock_alloc(void) { struct inode *inode; struct socket *sock; // 在已挂载的sockfs文件系统的super_block上分配一个inode inode = new_inode_pseudo(sock_mnt->mnt_sb); if (!inode) return NULL; // 获取inode对应socket_alloc中的socket结构指针 sock = SOCKET_I(inode); inode->i_ino = get_next_ino(); inode->i_mode = S_IFSOCK | S_IRWXUGO; inode->i_uid = current_fsuid(); inode->i_gid = current_fsgid(); // 将inode的操作函数指针指向 sockfs_inode_ops 函数地址 inode->i_op = &sockfs_inode_ops; this_cpu_add(sockets_in_use, 1); return sock; }
new_inode_pseudo 函数实际调用的是 alloc_inode(struct super_block *sb) 函数:
/** alloc_inode (fs/inode.c)*/ static struct inode *alloc_inode(struct super_block *sb) { struct inode *inode; // 如果文件系统的超级块已经指定了alloc_inode的函数,则调用已经定义的函数去分配inode // 对于sockfs,已经将alloc_inode指向sock_alloc_inode函数指针 if (sb->s_op->alloc_inode) inode = sb->s_op->alloc_inode(sb); else // 否则在公用的 inode_cache slab缓存上分配inode inode = kmem_cache_alloc(inode_cachep, GFP_KERNEL); if (!inode) return NULL; // 编译优化,提高执行效率,inode_init_always正常返回0 if (unlikely(inode_init_always(sb, inode))) { if (inode->i_sb->s_op->destroy_inode) inode->i_sb->s_op->destroy_inode(inode); else kmem_cache_free(inode_cachep, inode); return NULL; } return inode; }
四.跟踪分析Linux/Socket系统调用
我们首先在 sys_socketcall 处建立断点
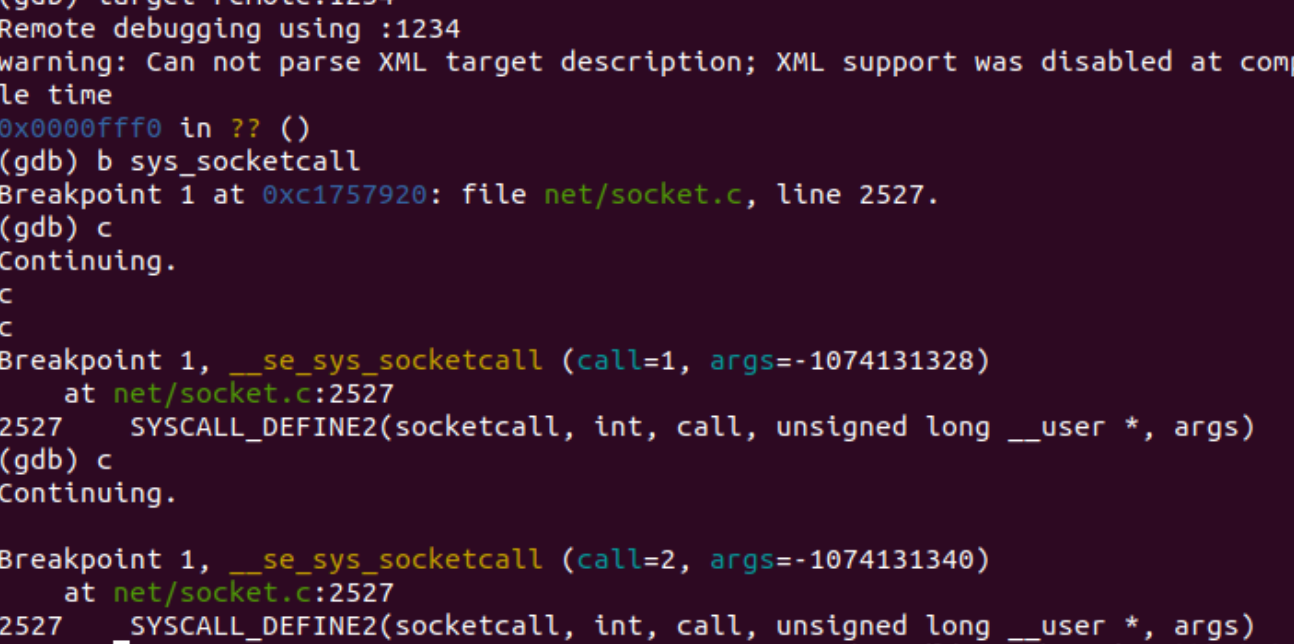
捕获到sys_socketcall,对应的内核处理函数为SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)
在net/socket.c中查看SYSCALL_DEFINE2相关的源代码如下:
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args) { unsigned long a[AUDITSC_ARGS]; unsigned long a0, a1; int err; unsigned int len; if (call < 1 || call > SYS_SENDMMSG) return -EINVAL; call = array_index_nospec(call, SYS_SENDMMSG + 1); len = nargs[call]; if (len > sizeof(a)) return -EINVAL; /* copy_from_user should be SMP safe. */ if (copy_from_user(a, args, len)) return -EFAULT; err = audit_socketcall(nargs[call] / sizeof(unsigned long), a); if (err) return err; a0 = a[0]; a1 = a[1]; switch (call) { case SYS_SOCKET: err = __sys_socket(a0, a1, a[2]); break; case SYS_BIND: err = __sys_bind(a0, (struct sockaddr __user *)a1, a[2]); break; case SYS_CONNECT: err = __sys_connect(a0, (struct sockaddr __user *)a1, a[2]); break; case SYS_LISTEN: err = __sys_listen(a0, a1); break; case SYS_ACCEPT: err = __sys_accept4(a0, (struct sockaddr __user *)a1, (int __user *)a[2], 0); break; case SYS_GETSOCKNAME: err = __sys_getsockname(a0, (struct sockaddr __user *)a1, (int __user *)a[2]); break; case SYS_GETPEERNAME: err = __sys_getpeername(a0, (struct sockaddr __user *)a1, (int __user *)a[2]); break; case SYS_SOCKETPAIR: err = __sys_socketpair(a0, a1, a[2], (int __user *)a[3]); break; case SYS_SEND: err = __sys_sendto(a0, (void __user *)a1, a[2], a[3], NULL, 0); break; case SYS_SENDTO: err = __sys_sendto(a0, (void __user *)a1, a[2], a[3], (struct sockaddr __user *)a[4], a[5]); break; case SYS_RECV: err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3], NULL, NULL); break; case SYS_RECVFROM: err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3], (struct sockaddr __user *)a[4], (int __user *)a[5]); break; case SYS_SHUTDOWN: err = __sys_shutdown(a0, a1); break; case SYS_SETSOCKOPT: err = __sys_setsockopt(a0, a1, a[2], (char __user *)a[3], a[4]); break; case SYS_GETSOCKOPT: err = __sys_getsockopt(a0, a1, a[2], (char __user *)a[3], (int __user *)a[4]); break; case SYS_SENDMSG: err = __sys_sendmsg(a0, (struct user_msghdr __user *)a1, a[2], true); break; case SYS_SENDMMSG: err = __sys_sendmmsg(a0, (struct mmsghdr __user *)a1, a[2], a[3], true); break; case SYS_RECVMSG: err = __sys_recvmsg(a0, (struct user_msghdr __user *)a1, a[2], true); break; case SYS_RECVMMSG: if (IS_ENABLED(CONFIG_64BIT) || !IS_ENABLED(CONFIG_64BIT_TIME)) err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1, a[2], a[3], (struct __kernel_timespec __user *)a[4], NULL); else err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1, a[2], a[3], NULL, (struct old_timespec32 __user *)a[4]); break; case SYS_ACCEPT4: err = __sys_accept4(a0, (struct sockaddr __user *)a1, (int __user *)a[2], a[3]); break; default: err = -EINVAL; break; } return err; }
SYSCALL_DEFINE2根据不同的call来进入不同的分支,从而调用不同的内核处理函数,如__sys_bind, __sys_listen等等内核处理函数。
在SYSCALL_DEFINE2调用的与socket相关的函数们都打上断点,再进行调试
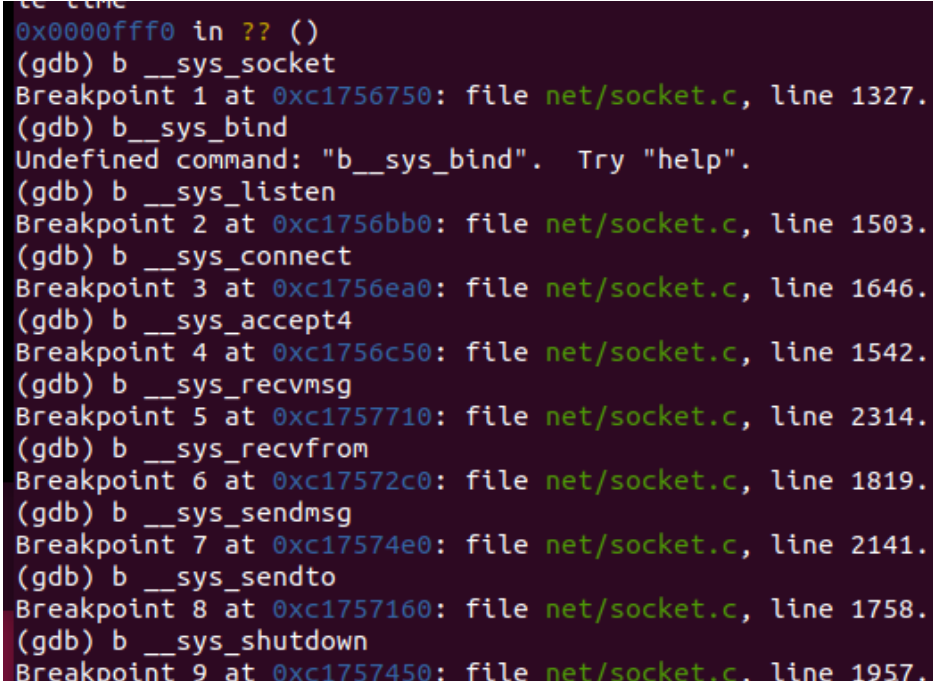
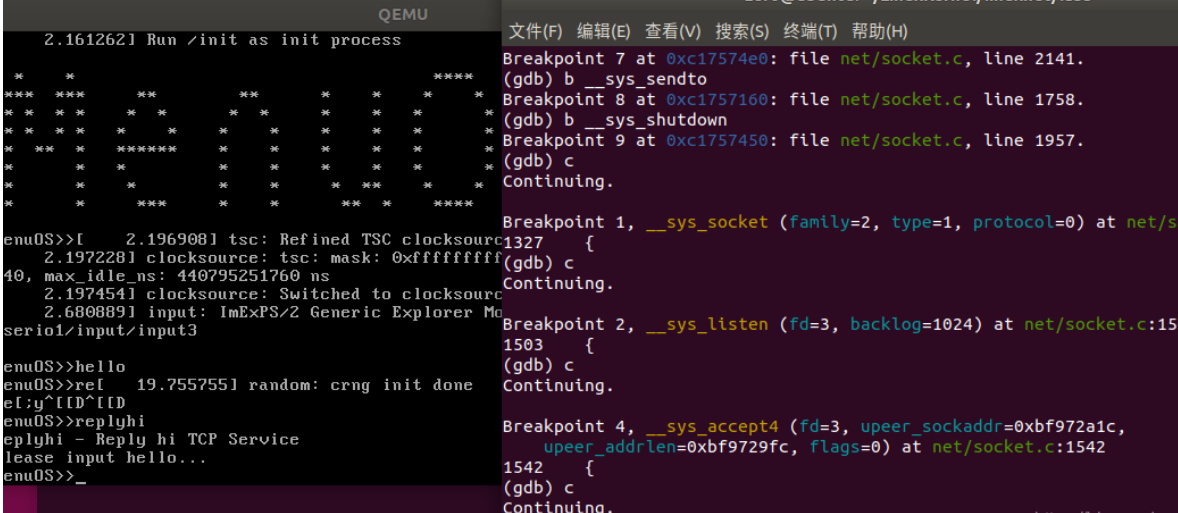
在Qemu中输入replyhi,发现gdb捕获到以上断点,一直到sys_accept4函数停止。说明此时服务器处于阻塞状态,一直在等待客户端连接,在Qemu中输入hello,同样捕获断点,可以看到客户端发起连接,发送接收数据,整个过程与TCP socket通信流程完全相同,至此,整个追踪过程结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号