虚拟内存分段
进程的地址空间布局:分段
Linux的虚拟地址空间采用“分段+分页”结合的方式实现。先看分段,之后再介绍分页。
分段是将内存划分成各个段落(Segment),每个段落的长度可以不同,且虚拟地址空间中未使用的空间不会映射到物理内存中,所以操作系统不会为这段空间分配物理内存。这样的话,内核为刚创建的进程分配的物理内存可以很小,随着进程运行不断使用内存,内核再为进程按需分配物理内存。也就是说,尽管地址空间的范围和物理内存大小一样,但不会将全部空间映射到物理内存。
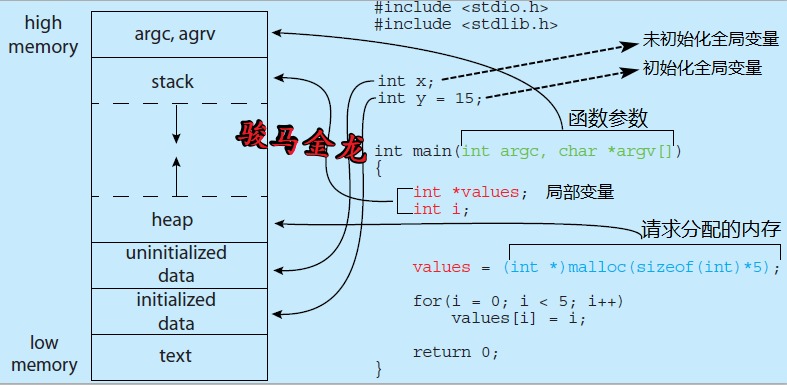
对于Linux进程的虚拟地址空间来说,它的内存布局如下图。

虚拟空间分了如下几个段:
- 文本段(Text):也称为代码段。进程启动时会将程序的代码加载到物理内存中,文本段映射到这片物理内存。
- 初始化数据:包含程序显式初始化的全局变量和静态变量,这些数据是在程序真正运行前就已经确定的数据,所以可以提前加载到内存保存好。
- 未初始化数据(BSS):未初始化的全局变量和静态变量,这些变量的值是在程序真正运行起来并为其赋值后才能确定的,所以程序加载之初,只需要记录它的内存地址和所需大小。出于历史原因,这段空间也称为BSS段。
- 栈(Stack):是一个可以动态增长和收缩的内存段落,由栈帧(Stack Frames)组成,进程每调用一次函数,都将为该函数分配一个栈帧,栈帧中保存了该函数的局部变量、参数值和返回值。注意,编译器会将函数参数放入寄存器来优化程序,只有寄存器放不下的参数才使用栈帧来保存。
- 堆(Heap):程序运行时,变量的值以及动态请求分配的内存都在这个内存段落中。
- 内核段(Kernel):这部分是操作系统内核运行时所占用内存在各进程虚拟地址空间中的映射。所有进程都有,且映射地址相同,因为都映射到内核使用的内存。这段内存只有内核能访问,用户进程无法访问到该段落。
从上面的描述大概也能推测出,除了堆内存外,其它段落空间都是自动填充分配的,用户无法控制这些内存的使用。而堆内存段是用户能使用的自由内存区,绝大多数程序的用户数据都丢在这里面,算是一个大杂烩空间。
例如,下图中是一段C代码和内存布局之间的对应关系。
提示:其它语言的内存布局
上面的布局C程序的内存布局,也是Linux下进程的内存布局。其它语言(比如CPython)编写的程序运行起来后,只要是在Linux下运行,其进程的布局也会如此。只不过这些语言的程序中,全局变量、局部变量等可能和C的布局不一样,这和各语言的底层设计有关。比如C编写的某动态语言,它不要求指定变量的数据类型,那么在加载到内存的时候自然不知道该变量类型所需的空间大小,当它转换成C后(尽管不会真的转换成C代码),这个变量只能丢进堆内存作为动态数据。
使用分段的好处就是“各段自扫门前雪”,虽然在地址空间中每个分段的地址都是连续的,但实际上,每个分段映射到物理内存地址时是独立的,段与段之间可以不连续。这是因为CPU为每个段都使用一对(即两个)特殊的寄存器:基址寄存器和界限寄存器。

而界限寄存器中的值用来表示该段在物理内存中的大小,即已为该段分配了多少内存。当准备用虚拟地址加基址计算物理地址时,需要先根据界限寄存器中的值检查将要访问的物理内存地址是否超出了这个段的范围。如果超出了,则表示访问了不属于该段的内存,也即内存的越界访问,而用户进程是没有权限访问其它进程或未分配内存的地址的,这时会收到一个SIGSEGV(segmentation violation)信号并提示:Segmentation Fault,即段错误或段异常。收到这个信号后默认情况下会终止该进程,因为它访问了非法地址,但是可以设置该信号的信号处理程序,从而做出其它处理。
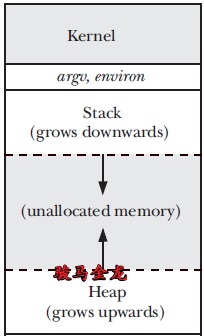
例如,下图中的进程访问了Kernel段或者unallocated memory部分的内存,都会报错。Kernel段除了内核进程,任何用户进程都无法访问,典型的地址是用户进程想要访问0x0地址时,而该地址属于Kernel,所以报错。而unallocated memory是还未分配的内存,界限寄存器会保护该段无法访问。
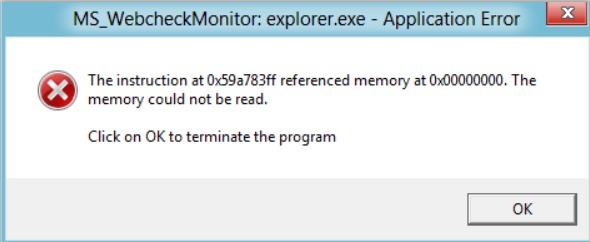
再例如,C数组的越界访问时也会出现该问题。下图直观地显示了在Windows中同样的内存越界错误。
也就是说,基址寄存器是用来转换地址的,界限寄存器是用来保护进程不越界访问内存的。CPU借助基址寄存器和界限寄存器管理并提供地址翻译和内存保护的功能,通常称为内存管理单元(Memory Management Unit,MMU)。
最后再说明一点,内存地址翻译的任务既可以由操作系统来做,也可以由硬件CPU来做。但如果完全由操作系统来完成,就需要频繁地陷入到内核态,这样效率会非常低。所以,这项任务交给CPU硬件来完成,操作系统只需在必要的时候介入,比如分配内存、回收内存等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号