
JavaScript 正则入门
JavaScript 正则入门

什么是正则?
JavaScript 内置对象,使用正则表达式(RegExp)可以进行强大的模式匹配、文本检索以及替换功能。
作用
- 验证指定数据格式是否符合要求
- 聊天表情
- 数据采集
- ...
创建正则表达式的方式
通过直接量的形式创建正则表达式:
var re = /\d/g;
通过构造函数创建正则表达式:
var re = new RegExp('\\d', 'g')
使用构造函数的方式创建正则表达式需要进行转义。
基础应用
最简单的正则表达式就是需要匹配的内容设置到正则当中去,例如:
var str = 'abc123hello456world';
// 假设需要使用的正则
var re = /hello/;
// 通过str中的match方法来实现匹配
console.log(str.match(re)); // ['hello']
在正则当中,大小写同样是敏感的,如果需要不区分大小写,则需要使用修饰符i。
例如:
var str = 'abc123HELLO456world'; // 字符串中的hello已经变为大写
// 设置需要使用的正则
var re = /hello/i; // 在正则的后面添加上需要使用的修饰符
// 直接进行匹配
str.match(re); // ['HELLO']
常用的修饰符:
- i 大小写不敏感
- g 全局匹配,查找所有匹配而非在第一个匹配后停止
- m 执行多行匹配
示例:
var str = 'abc123';
var re = /\d/; // \d 表示数字
str.match(re); // [1]
上面的代码中,正则表达式只匹配到了第一个数字就结束了,如果想要匹配全部的数字,可以使用g修饰符。
正则可以改写为如下:
var re = /\d/g;
m 修饰符可以进行多行匹配,例如:
var str = 'abc\n123\n456';
var re = /^\d+/gm;
str.match(re); // ['123', '456']
在上面的代码中,用到了^这个符号,在正则中,这个符号表示正则的开始,$表示正则的结束。
例如:
var str = '123abc\n456';
var re = /^\d/gm;
str.match(re);// ['1', '4']
上面代码中,正则匹配的是以数字开头的字符,并且全局匹配和多行匹配,在上面的字符串中,第一行是123abc,开头的数字是1,第二行是456,开头的数字是4.
量词
在正则中,想要表示匹配的数量,可以通过下面的两种形式:
-
通过特殊的符号表示数量次数
+匹配一次到多次?匹配零次到一次*匹配0次到任意次
-
通过
{m,n}来设置数量次数
首先,先来看下不使用量词和使用量词的区别。
示例:
var str = 'abc123cb231'; // 创建一个字符串,其中包括字母和数字
var re = /\d/g; // 全局匹配数字
str.match(re); // [ "1", "2", "3", "2", "3", "1" ]
上面的示例中,\d匹配数字,g是全局匹配,二者配合匹配到了字符串中的全部数字,但是所有的数字全被拆开了。
如果想要把数字整组的表示,就可以使用量词了。
示例:
var str = 'abc123cb231'; // 创建一个字符串,其中包括字母和数字
var re = /\d+/g; // 全局匹配数字
str.match(re); // [ "123", "231" ]
使用{m,n}的这种写法,可以设置最少和最多的匹配次数。
示例:
var str = 'abc123cb231'; // 创建一个字符串,其中包括字母和数字
var re = /\d{1,2}/g; // 全局匹配数字 一次性最少匹配1次最多匹配2次
str.match(re); // [ "12", "3", "23", "1" ]
原子
在正则当中,一个字符即为一个原子。
示例:
var re = /a/; // 此时正则会匹配字符串中的字母a,此时可以说a 就是一个原子
在正则中,单独使用\d也是属于匹配一个原子。
示例:
var str = 'abc123';
var re = /\d/;
str.match(re);//['1']
一个原子对应着一个字符串内容,上述的正则中如果想要匹配字符串中的所有数字,就可以使用三个\d,每一个\d代表一个数字字符。
示例:
var re = /\d\d\d/;
当然,上述的写法很明显是不太理想的,可以通过量词来修饰原子,例如上面示例中字符串的数字一共有三位,就可以设置量词来进行修饰。
示例:
var re = /\d{3}/;
选择修饰符
在正则中,可以通过选择修饰符|来表示或者的关系。
示例:
var str1 = 'abc';
var str2 = 'adc';
var re = /abc|adc/;
str1.match(re); // ['abc']
str2.match(re); // ['adc']
上面的正则表达式中,通过|选择修饰符表示了一个或者的关系,即匹配abc或者匹配adc。
除了使用|来表示或者以外,还可以通过[]来表示或者的关系。
示例:
var re1 = /a[bd]c/; // 表示匹配abc 或者adc
var re2 = /a[b,d]c/; // 表示匹配abc 或者a,c 或者 adc
需要注意的是,[]除了表示或者,还可以表示一个范围。
示例:
var re = /a[0-9]/; // 表示匹配a0 - a9
如果在[]的里面加入一个^则表示除了的意思。
示例:
var re = /a[^bd]c/; // a和c之间匹配除了bd的其他内容
模式单元
在正则中,可以通过()来表示模式单元,模式单元的作用如下:
- 改变优先级
- 将多个原子视为一个原子
- 将匹配的内容暂存在内存当中
- 可以通过`(?:原子)的形式来取消暂存内存
通过模式单元调整优先级非常类似于数学当中的操作。
示例:
var re = /abcd|efg/; // 匹配的内容是abcd 或者 efg
// 使用模式单元更改优先级
var re = /abc(d|e)fg/; // 匹配abcdfg 或者 abcefg
下面的示例中是通过模式单元将多个原子视为一个原子。
示例:
var re = /hello/; // 此时这个正则匹配的是hello
// 如果需要匹配1-3次的hello,就需要使用模式单元
var re = /(hello){1,3}/; // 此时通过模式单元将hello视为一个原子。
除了上述的两个功能以外,模式单元还有另外一个功能,就是将匹配的内容暂存到内存当中。
示例:
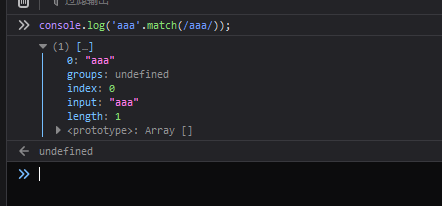
// 不使用模式单元进行匹配
console.log('aaa'.match(/aaa/));
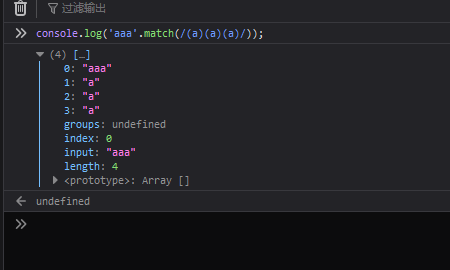
// 使用模式单元将正则原子包裹
console.log('aaa'.match(/(a)(a)(a)/));
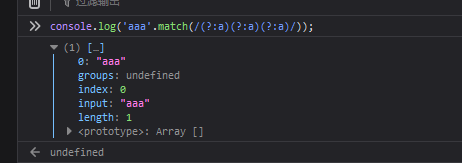
可以使用?:不让模式单元将字符存在内存中。
示例:
console.log('aaa'.match(/(?:a)(?:a)(?:a)/));
字符类
在上面的很多案例中,都用到了\d,其实这个\d属于字符类,常用的字符类如下:
.匹配除了\n之外的所有字符\d匹配所有的数字\D匹配所有的非数字\s匹配所有空白字符包括\r \t等\S匹配所有的可见字符\w匹配数字字母下划线\W匹配除了数字字母下划线其他字符\b匹配单词边界\B匹配非单词边界
下面以\b单词边界为例。
示例:
var str = 'hello,world!How are you ?';
var re = /\b[a-zA-Z]+\b/g;
str.match(re); // [ "hello", "world", "How", "are", "you" ]
字符直接量
如果需要通过正则匹配一些特殊的字符,可以使用下面的内容。
- \0 查找 NUL 字符。
- \n 查找换行符。
- \f 查找换页符。
- \r 查找回车符。
- \t 查找制表符。
- \v 查找垂直制表符。
- \xdd 查找以十六进制数 dd 规定的拉丁字符。 \x01 等价于 \n
- \uxxxx 查找以十六进制数 xxxx 规定的 Unicode 字符。 [\u2E80-\u9FFF]
示例:
var str = 'hello\nworld';
var re = /\n/g;
str.replace(re, '--');//hello--world
字符串边界
在写正则进行匹配的时候,需要确认字符串在何处开始,何处结束,正则中可以通过^表示匹配字符的开始,通过$表示匹配字符的结束。
贪婪模式
正则当中的贪婪模式是由量词引起的,简单的说就是正则默认情况下会在保证匹配成功的前提下尽可能多的去匹配。
示例:
var str = 'abcdefg123';
var re = /[a-zA-Z]+/;
str.replace(re, '*'); // "*123"
在上面代码中,通过正则去匹配字符串中的字母,并且通过replace方法将字母变成*,量词使用了+,这个时候对于正则来说,匹配1次或者n次都属于匹配成功,但是正则在匹配的时候尽可能的匹配了最多次,并且替换成了*。这种情况也就是属于贪婪模式。
也就是说,正则在默认状态下是属于贪婪模式的。
而想要避免贪婪模式,需要根据需求调整量词的使用。
例如有的时候需要尽可能少的匹配,就可以直接在量词的后面添加?或者直接使用匹配次数较少的量词。
示例:
var str = 'abcdefg123';
var re = /[a-zA-Z]{1,3}?/;
str.replace(re, '*'); // "*bcdefg123"
和正则配合的方法
在js的String对象中,有一些方法可以和正则进行配合使用,常用的如下:
- match
- search
- replace
而RegExp对象中也有常用的一些方法:
- test
- exec

 浙公网安备 33010602011771号
浙公网安备 33010602011771号