
链表
1.链表基本概念:
(1).结点(Node)组成;
(2).数据域:存储数据元素本身;
(3).指针域:存储邻接元素存储地址(位置);
(4).链接方式:
①单链表:每个结点只有一个指针域;
②双向链表:每个结点有两个指针域;
③循环链表:是一个首尾相连的链表。
2.链表使用场景:
问题:存储一个班的同学成绩(人数不确定),该如何存储?
解决方法1:定义尽可能长的数组:
优点:
(1).无需为表示结点的逻辑关系增加空间;
(2).可以随机取出表中任何元素。
缺点:
(1).插入或删除平均需要移动一半的结点;
(2).顺序表要求连续的空间。
解决方法2:利用链表来存:
过程:定义头结点,为数据域和指针域,数据域存储当前成绩,指针域存储下一个数据的地址,每加入一个成绩就追加结点。
优点:
(1).可以不占用连续的内存空间,其占用的内存空间可以不连续;
(2).插入和删除元素不需要移动其他元素,只需要改变指针域。
缺点:
(1).不可以随机取出表中元素;
(2).删除和插入等操作如果指针域改变错误,会丢失后面全部元素。
3.链表的基本操作:(※注意:以下全为不带头结点链表)
(1).追加元素(add/insert):
①插在头结点的位置: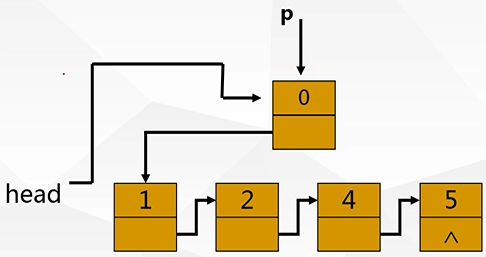
p->next=head;
head=p;
②插在中间位置:
d->next=p->next;
p->next=d;
(2).删除元素(delpos/deldata):
①删除头结点: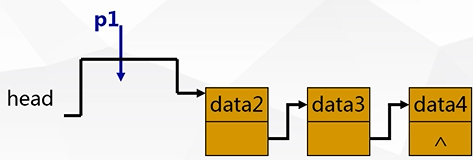
p1=head;
head=head->next;
delete p1;
②删除不是头结点: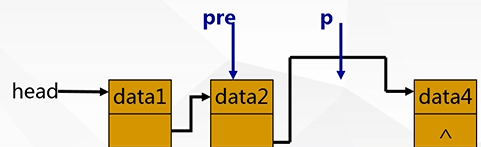
per->next=p->next;
delete p;
(3).遍历链表(display):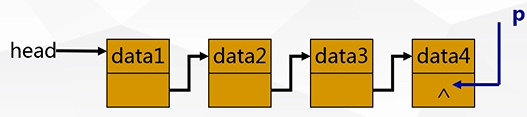
p=head;cout<
p=p->next;cout<
p=p->next;//p=NULL(遍历终止条件)
4.双向链表链表的基本操作:(※注意:以下全为不带头结点链表)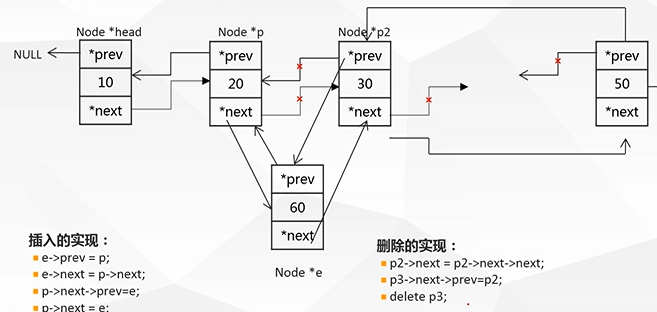
(1).插入元素:
e->prev=p;
e->next=p->next;
p->next->prev=e;
p->next=e;
(2).删除元素:
p2->next=p2->next->next;
p3->next->prev=p2;
delete p3;
5.链式栈基本操作:
(1).入栈: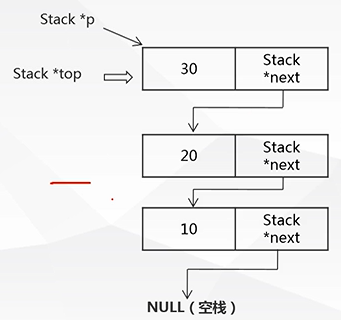
p->next=top;
top=p;
(2).出栈: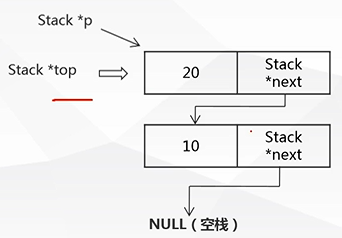
p=top;
p=p->next;
delete top;
top=p;
6.链式队列基本操作:
(1).入队: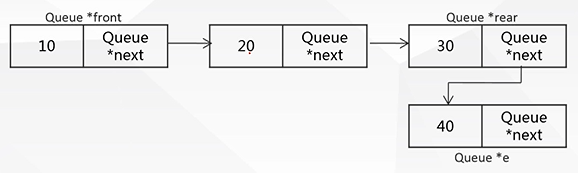
rear->next=e;
rear=e;
(2).出队: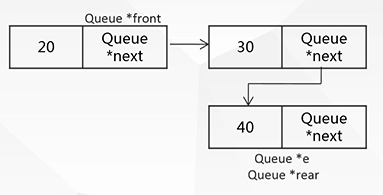
t=front;
front=front->next;
if(front==NULL) rear=NULL;
delete t;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· .NET10 - 预览版1新功能体验(一)