Tutorial 06_MapReduce实例WordCount
实验步骤
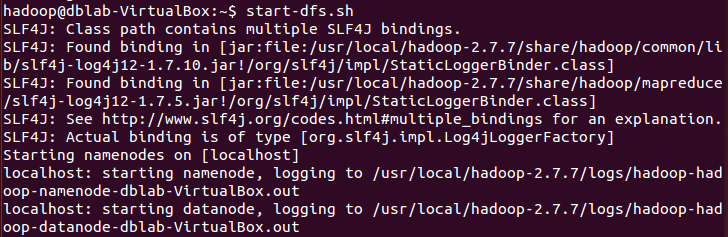
1.切换目录到/apps/hadoop/sbin下,启动hadoop。
2.在linux上,创建一个目录/data/mapreduce1。
- mkdir -p /data/mapreduce1
3.切换到/data/mapreduce1目录下,自行建立文本文件buyer_favorite1。
依然在/data/mapreduce1目录下,使用wget命令,从
网络下载hadoop2lib.tar.gz,下载项目用到的依赖包。
将hadoop2lib.tar.gz解压到当前目录下。
- tar -xzvf hadoop2lib.tar.gz
4.将linux本地/data/mapreduce1/buyer_favorite1,上传到HDFS上的/mymapreduce1/in目录下。若HDFS目录不存在,需提前创建。
- hadoop fs -mkdir -p /mymapreduce1/in
- hadoop fs -put /data/mapreduce1/buyer_favorite1 /mymapreduce1/in
5.打开Eclipse,新建Java Project项目。
并将项目名设置为mapreduce1。
6.在项目名mapreduce1下,新建package包。
并将包命名为mapreduce 。
7.在创建的包mapreduce下,新建类。
并将类命名为WordCount。

8.添加项目所需依赖的jar包,右键单击项目名,新建一个目录hadoop2lib,用于存放项目所需的jar包。
将linux上/data/mapreduce1目录下,hadoop2lib目录中的jar包,全部拷贝到eclipse中,mapreduce1项目的hadoop2lib目录下。
选中hadoop2lib目录下所有的jar包,单击右键,选择Build Path=>Add to Build Path
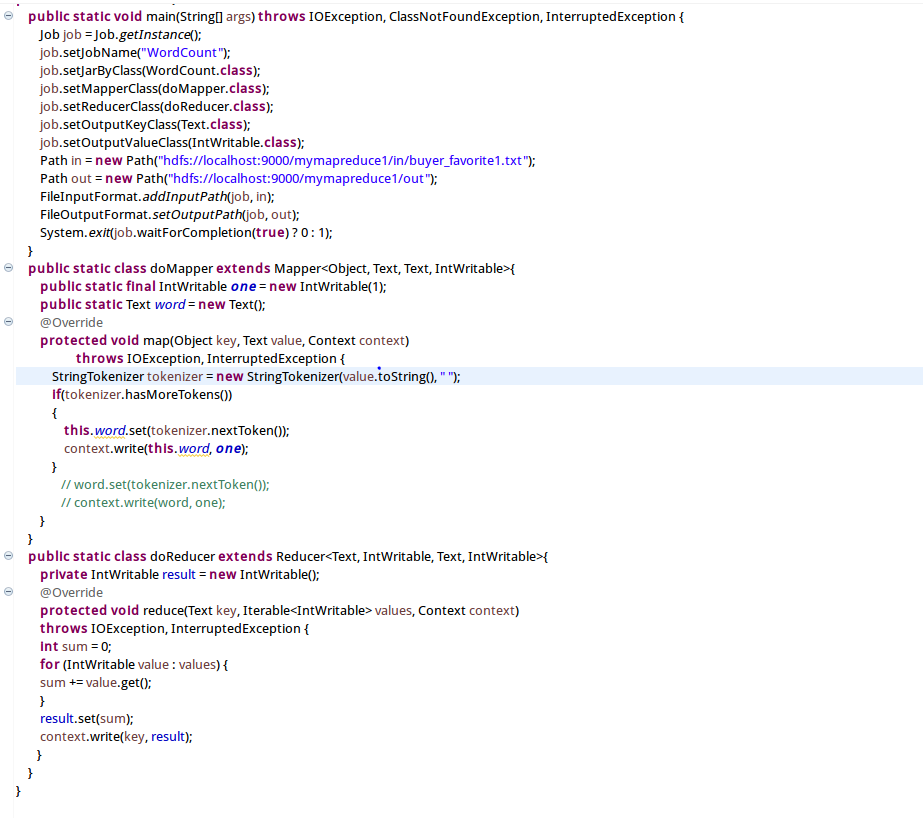
9.编写Java代码,并描述其设计思路。
下图描述了该mapreduce的执行过程
大致思路是将hdfs上的文本作为输入,MapReduce通过InputFormat会将文本进行切片处理,并将每行的首字母相对于文本文件的首地址的偏移量作为输入键值对的key,文本内容作为输入键值对的value,经过在map函数处理,输出中间结果<word,1>的形式,并在reduce函数中完成对每个单词的词频统计。整个程序代码主要包括两部分:Mapper部分和Reducer部分。
Mapper代码

在map函数里有三个参数,前面两个Object key,Text value就是输入的key和value,第三个参数Context context是可以记录输入的key和value。例如context.write(word,one);此外context还会记录map运算的状态。map阶段采用Hadoop的默认的作业输入方式,把输入的value用StringTokenizer()方法截取出的买家id字段设置为key,设置value为1,然后直接输出<key,value>。
Reducer代码

map输出的<key,value>先要经过shuffle过程把相同key值的所有value聚集起来形成<key,values>后交给reduce端。reduce端接收到<key,values>之后,将输入的key直接复制给输出的key,用for循环遍历values并求和,求和结果就是key值代表的单词出现的总次,将其设置为value,直接输出<key,value>。
完整代码
10.在WordCount类文件中,单击右键=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中。

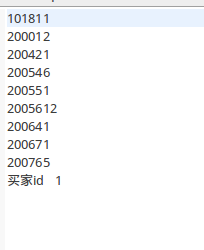
11.待执行完毕后,打开终端或使用hadoop eclipse插件,查看hdfs上,程序输出的实验结果。
- hadoop fs -ls /mymapreduce1/out
- hadoop fs -cat /mymapreduce1/out/part-r-00000