

深度学习-神经网络(思想)
机器学习中,人工选择数据(数据获取)、提取特征(特征工程)、选择算法(建立模型)、得到结果(评估应用)
深度学习解决了机器学习中特征工程的问题
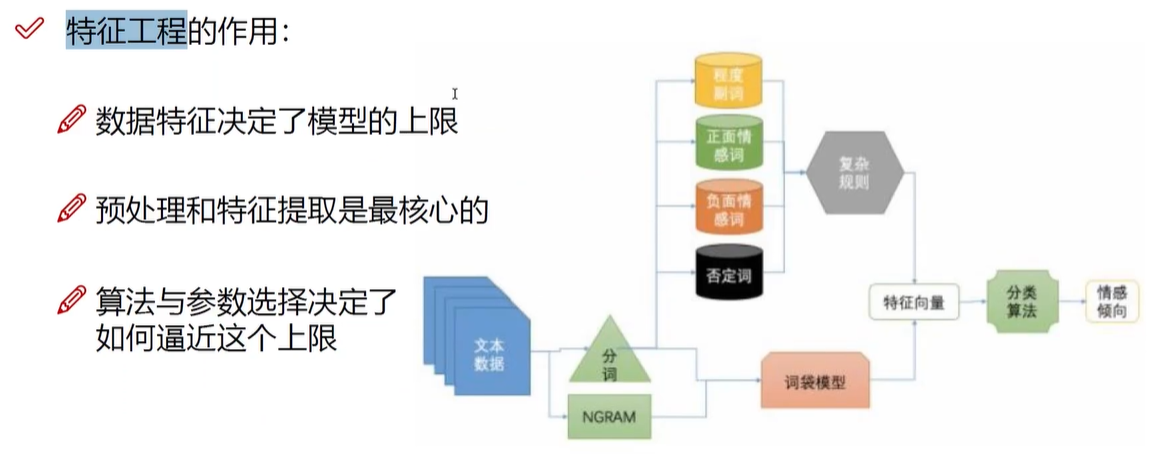
怎样去选取特征,比如面对图像数据、文本数据的时候怎么办
深度学习能自动学习到目标什么特征是最合适的
深度学习应用:90%计算机视觉(人脸识别),对移动端支持相对较差(计算量太大)
医学领域,变脸,黑白片转彩色,分辨率重构,
12 年ALEX 第一名 领先第二名10+% ,后开始发展

深度学习,根据原来的(图像)数据,可以经过变换(倾斜,高斯模糊,变形等)生成新的数据
神经网络是个黑盒子(但是学习需要了解其中的各步骤细节)

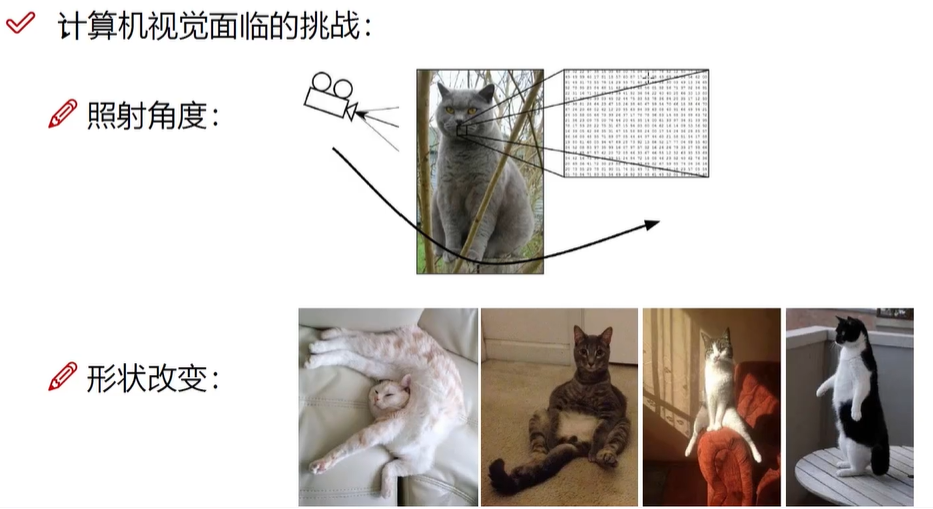

之前有遮蔽的例子后,下次遇到就能学习识别
深度学习与之前的套路都一样,都属于机器学习

动物图形库CIFAR-10
KNN来分类图片,相似的是整体方面的,聚焦于全体

神经网络基础
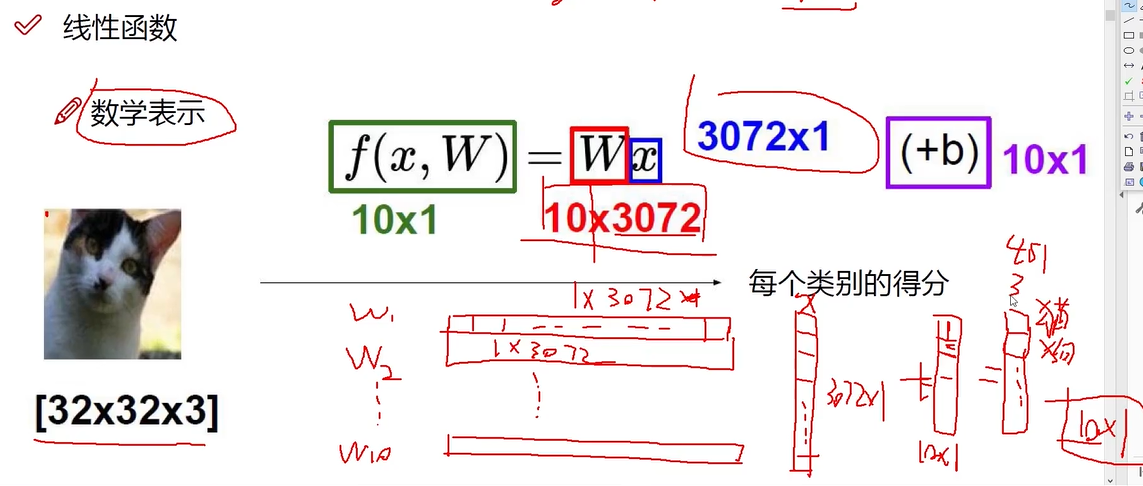
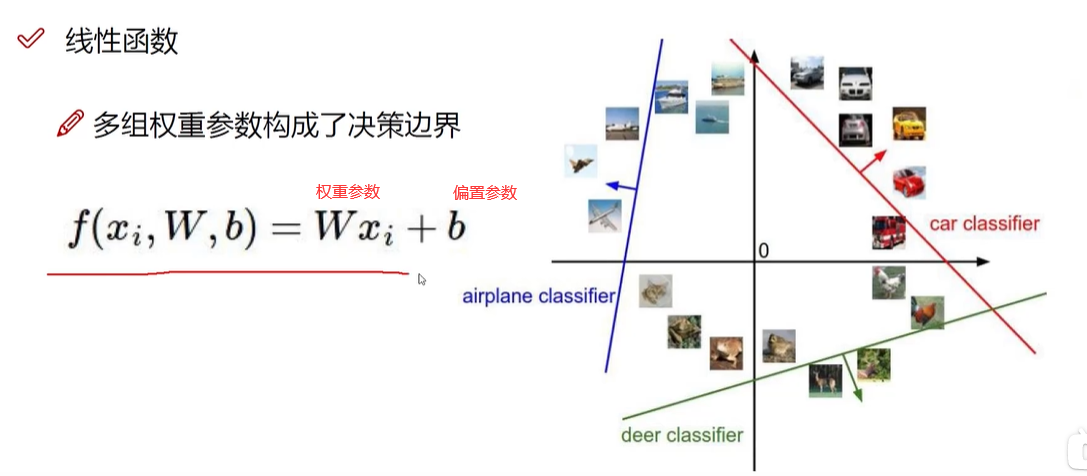
线性函数(得分函数)
某个图片属于某个类别的得分值(属于猫、狗、等的得分值)
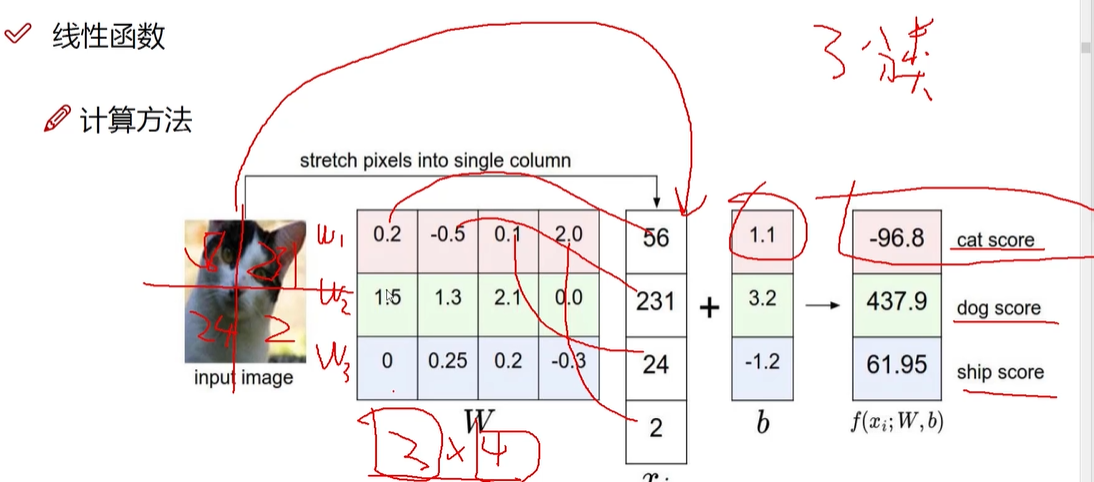
背景像素点(低)与决定性的像素点(高)权重是不同的
W权重参数:对结果决定性影响 ; 类别W1 W2 W3
b偏置参数:微调作用 (10个不同数值的b) 各自类别各自微调
先提供一个随机的W矩阵,然后根据样本进行优化,逐渐得到合适恰当的W矩阵(也是神经网络主要做的内容)


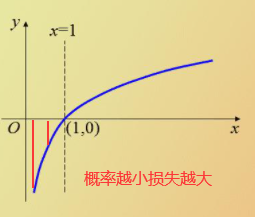
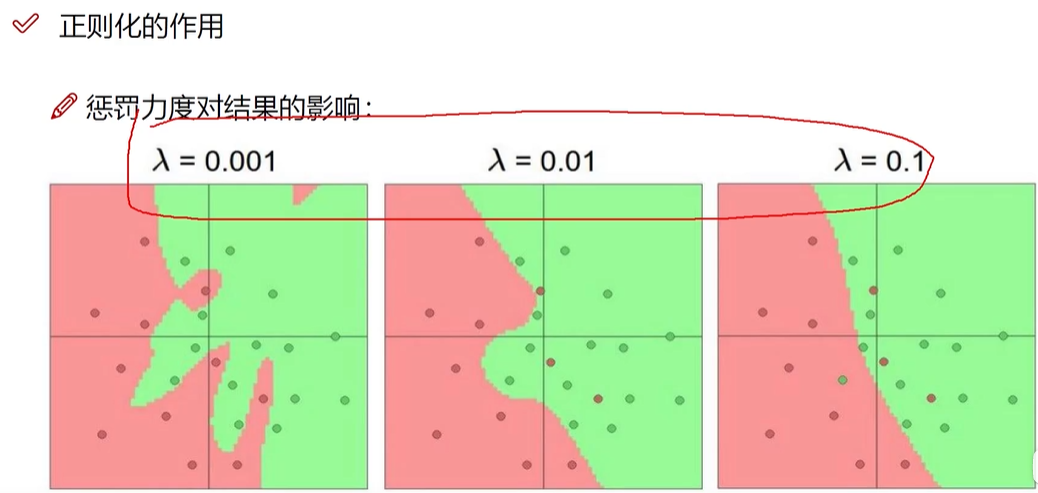
数据在损失函数中得到的损失data_oss ,正则化惩罚项λ(w1^2+w2^2+w3^2+...)只考虑权重参数 ,λ(惩罚系数) 比较大的时候不希望过拟合,没有过多的突兀处,小的时候则相反。
神经网络过于强大,容易出现过拟合,要压制一些


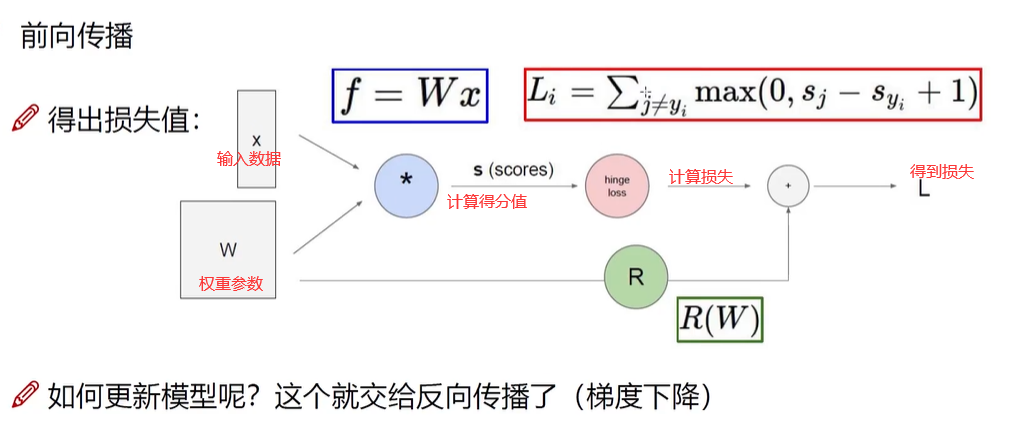
蓝色框 得分函数 W权数参数 f 得分值 ,Li计算损失 ,然后再加上Rw(正则化惩罚项)
x输入数据 W权数参数 计算得分值 Li计算损失 ,然后再加上Rw 得到损失值
之前是一个W来做,神经网络是用多个W来做
不是一次变换就得到损失值L,而是经过多次变换,比如要识别一只猫,第一次特征重视的地方是猫的身体,而降低背景的权重,表示为XW1,然后在猫的身体部分再识别重要的某个特征(头部),表示为(XW1)W2,然后识别其头部的某个特征(胡须)表示为(XW1W2)W3,就这样一层层得出最终的损失值L
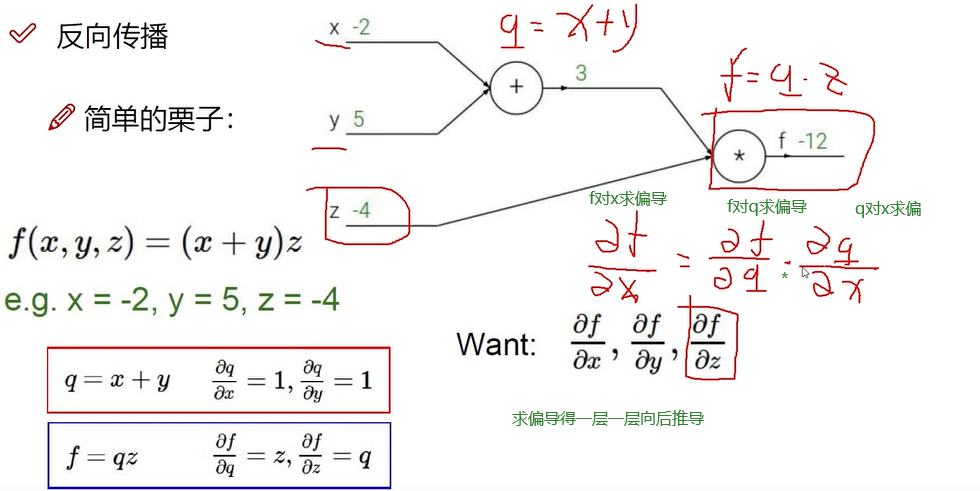
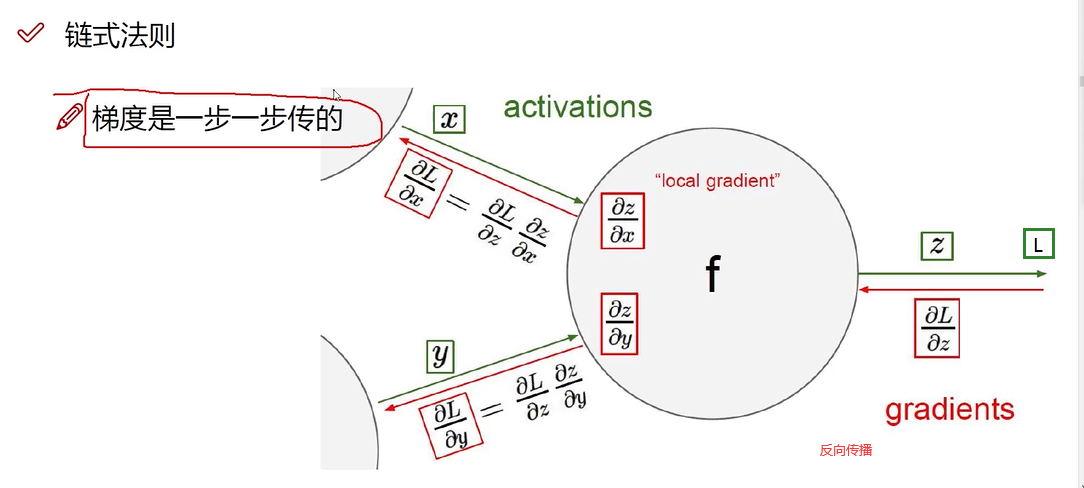
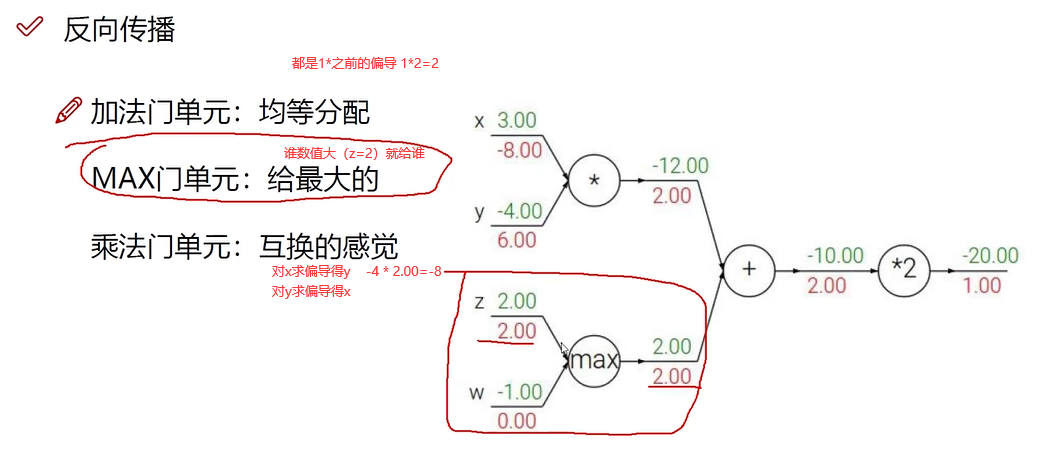
求某个对象偏导,就是求其对结果的影响
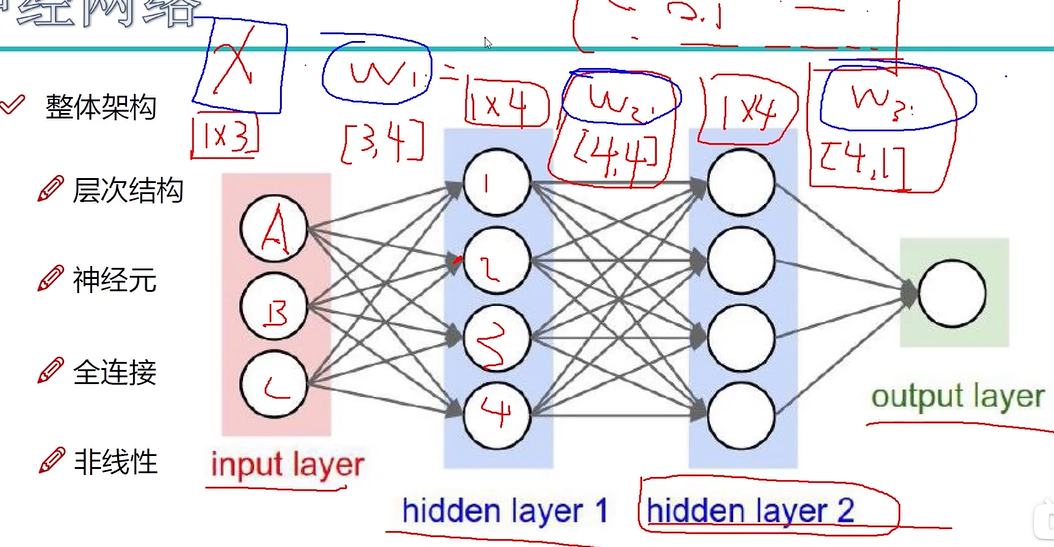
A,年龄 B,身高 C,体重
第二层,经过(权重参数)计算(x1*0.1+x2*0.6+x3*0.9),在计算机眼里是更好的特征,每个特征根之前的全部特征都有联系
1个样本3个特征
神经网络结果好坏,就是看w1,w2,w3 选择的好坏
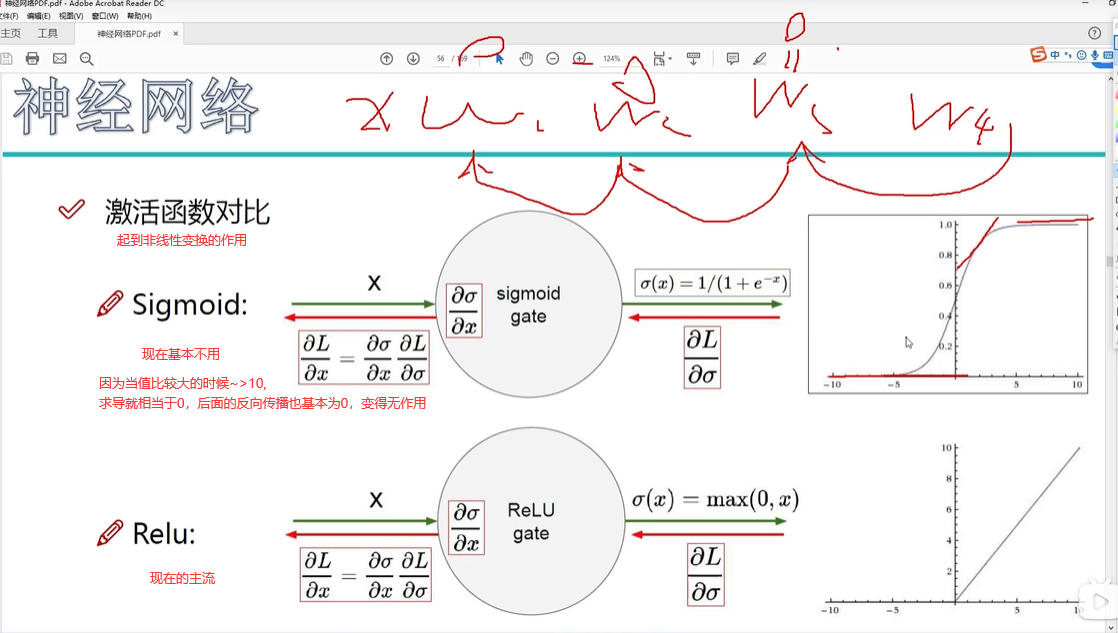
非线性:是指每次X和W组合之后,进行非线性的变换,比如Sigmoid函数,max(0,x),只要不是线性的就行
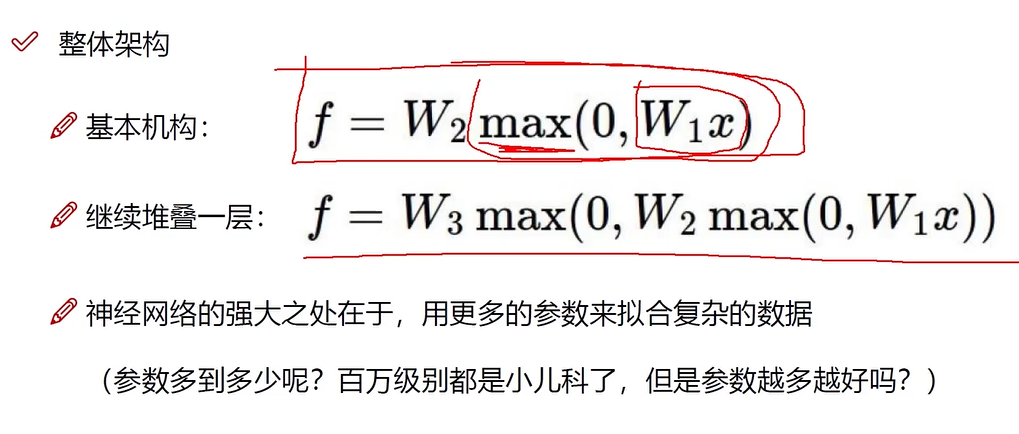
神经元个数越多,越拟合数据(容易产生过拟合)
一个神经元: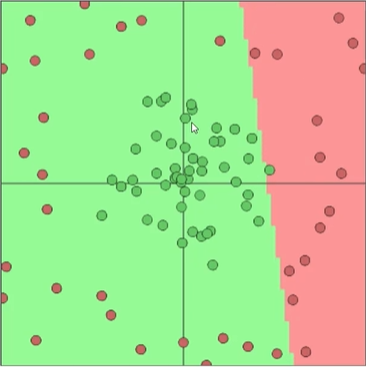
两个神经元: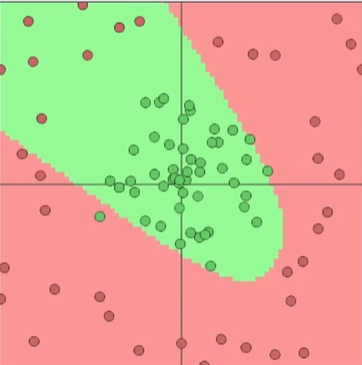
三个神经元: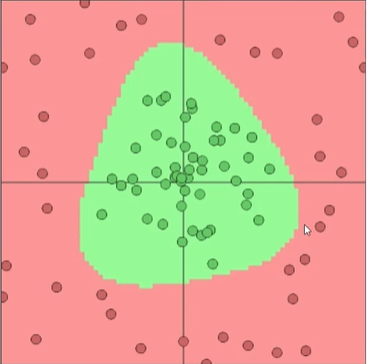
数量3个就可以得到一个比较好的模型,目的是更好的作用于预测
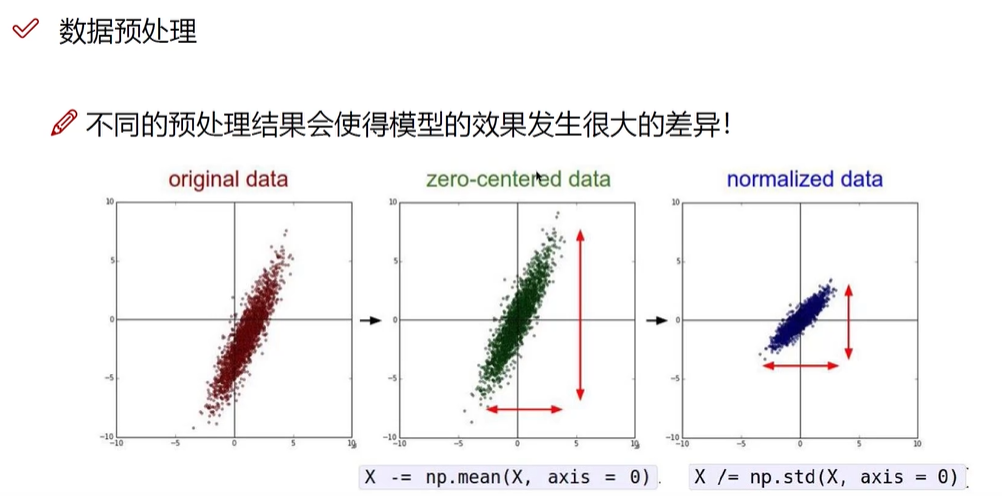
1.中心化(实际坐标值-平均值)
2.各个维度放缩(除以标准差)

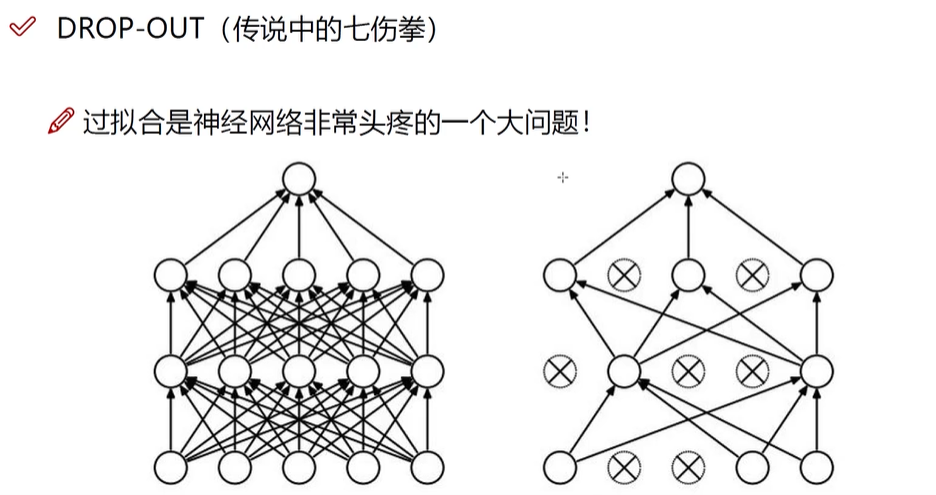
训练阶段用这个DROP-OUT,每次迭代每一层随机选择一部分(x%)使用,(用来避免神经网络过于强大,减少其过拟合风险)
测试阶段用完全体(左图)


· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决
· 提示词工程——AI应用必不可少的技术