

决策树
关键字:熵、Gini系数CART、信息增益ID3、信息增益率C4.5、 决策树剪枝、随机森林
决策树(decision tree)是一种基本的分类与回归方法
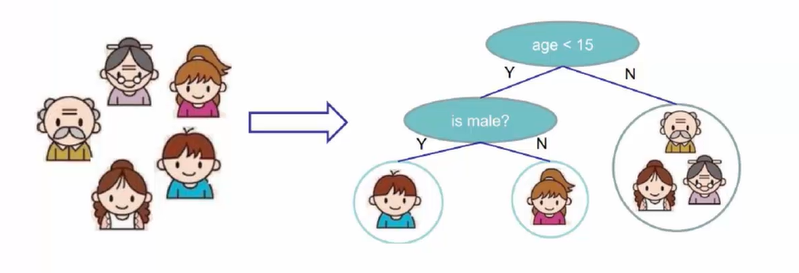
根节点 age<15,非叶子节点 is male,叶子节点娃娃头(结果值),分支( Y ,N)
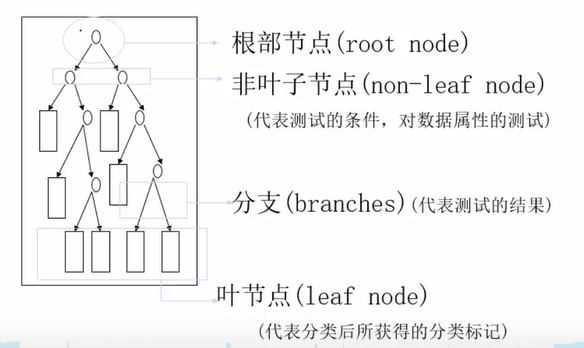
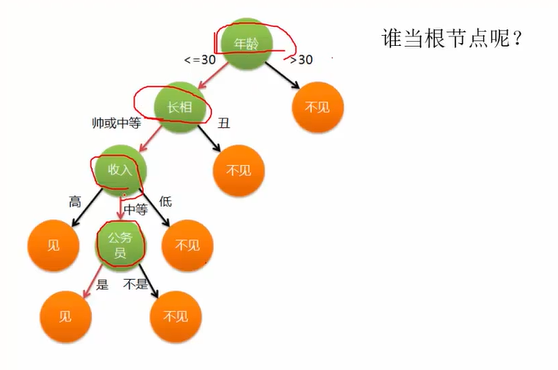
如何利用数据构造一个决策树?各个节点应该用哪一个特征和怎样排列?
根据熵的大小(混乱程度:越大越混乱)
熵定义为信息的期望值。在信息论与概率统计中,熵是表示随机变量不确定性的度量。如果待分类的事务可能划分在多个分类之中,则符号xi的信息定义为
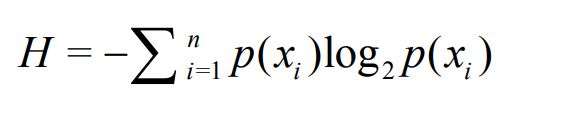
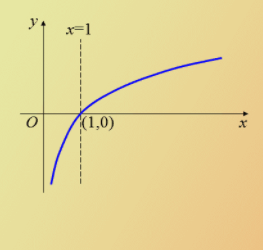
p(xi):xi 发生的概率(0,1),p(xi)越小,发生的概率小,熵越大,反之熵越小。
根据Gini系数(原理跟熵一样,Pk 发生的概率)
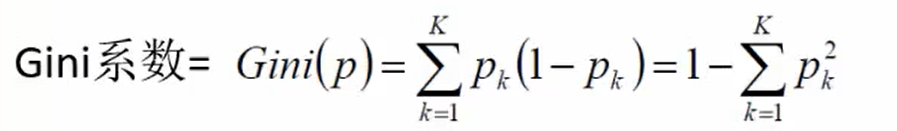
得到高度最矮的决策树

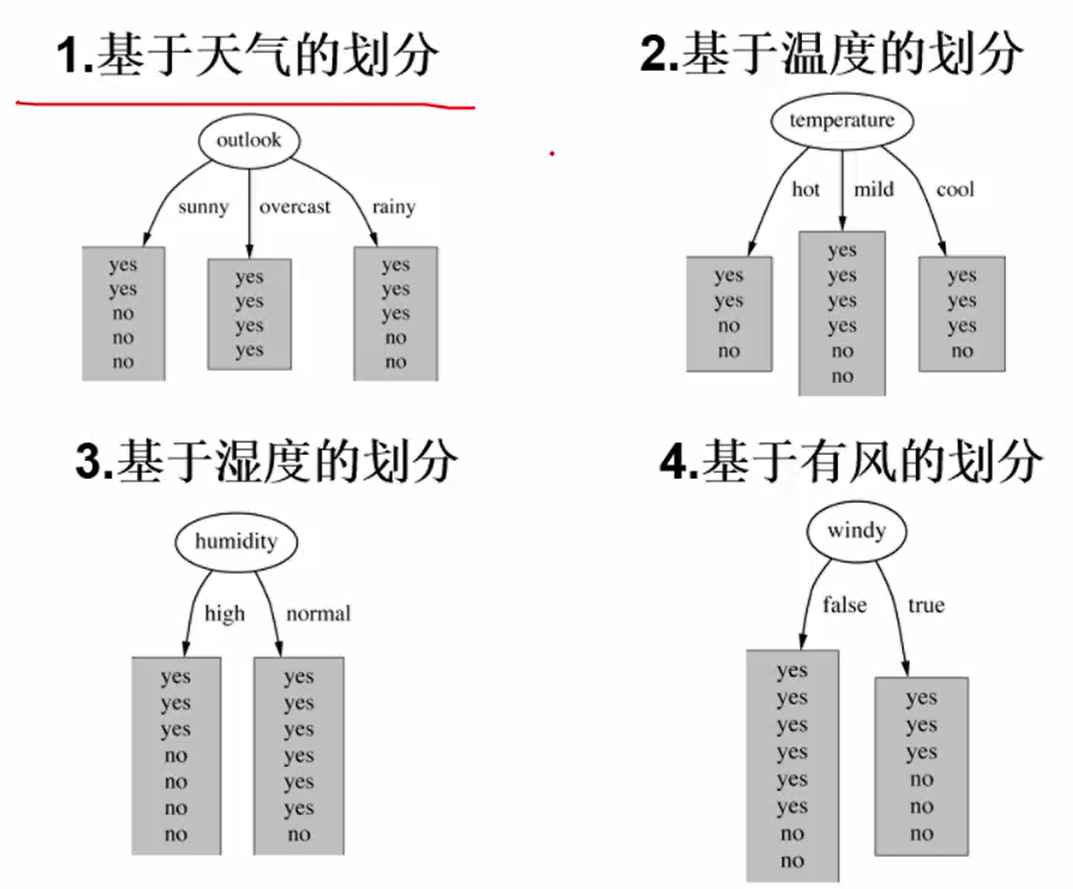

信息增益(越大越好)
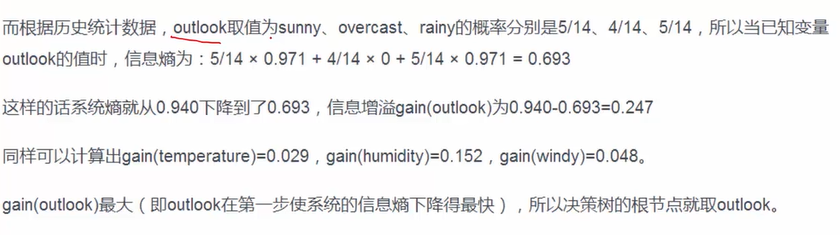

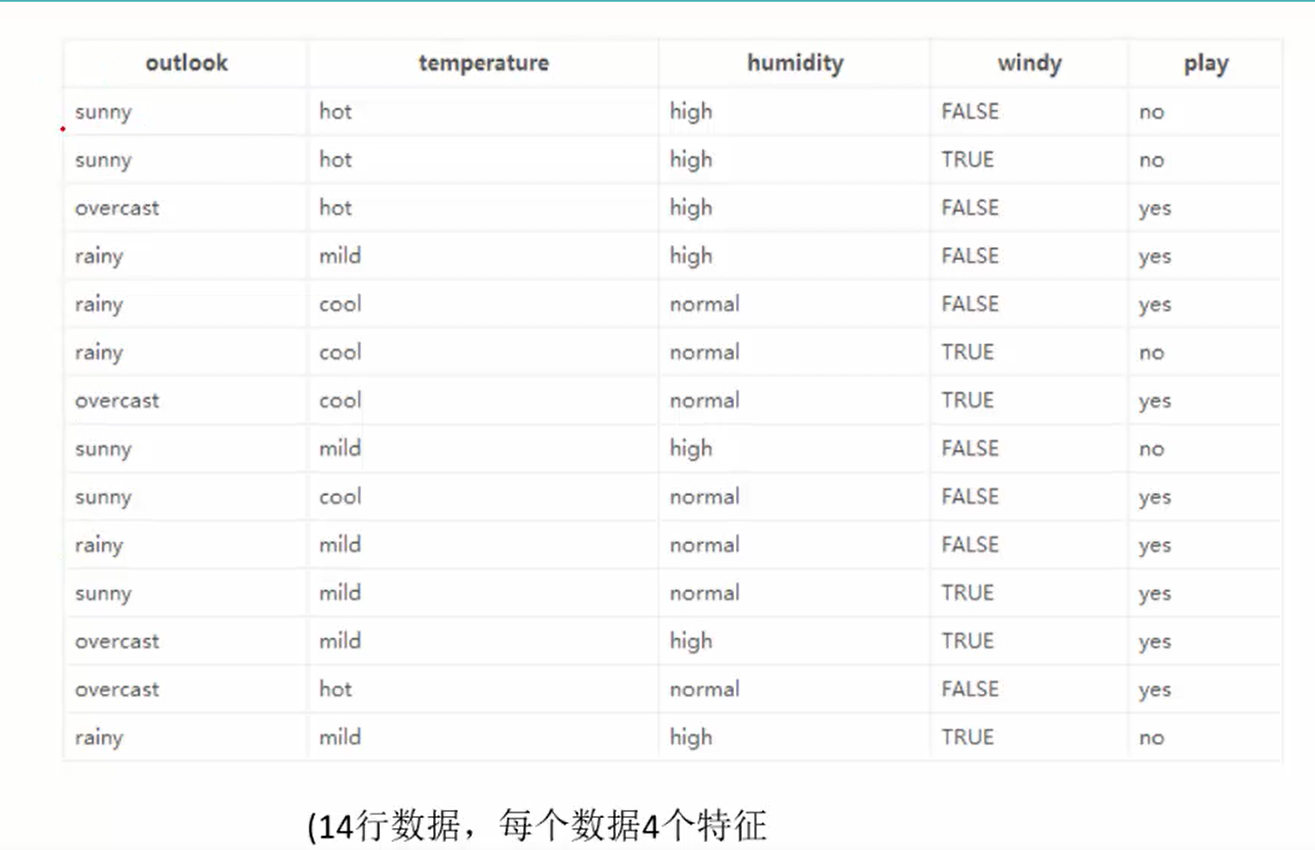
类似table 2的一张表里面,筛选出outlook=sunny的全部词条,分别再次计算(类似递归)

信息增益缺点:数据的有些特征对最终结果并没有直接影响,但是信息增益在计算的时候缺将其包含在内,这就引起了最终数据的偏差(比如序号1-N)
对应信息增益缺点:信息增益率=信息增益/自身熵值
如何判断这个决策树的好坏:评价函数

t是每一个叶子节点,H(t)熵值,Nt 当前叶子节点的权重值(叶子节点里面包含多少个类别) 【评价函数越小越好】

连续值:比如说age<=30, 划分离散值 5-10,11-15,16-20,21-25,26-30 等等分支

决策树剪枝:
不剪枝的话可能会出现过拟合,在训练集上可能达到100%的效果,树比较高,分支多(考虑每一个样本),在预测样本上效果就不是很好。
预剪枝:在构建决策树的时候,计划提前停止,比如深度D,定义D>4 的时候就结束构造决策树;或者一个节点当前样本数量min_samples<30就停止这个节点往下的分裂延伸
后剪枝:决策树构建后,再进行裁剪(用到下面的公式)

α是权重 (越大的话修剪越多,叶子节点数越少) C(T)是上面提到过的评价函数 T_leaf(叶子节点个数)
随机森林
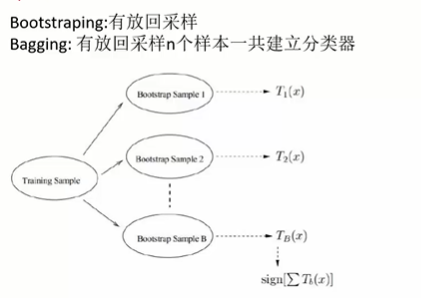
有放回采样:数据【1,2,3,4】 -> 采样1 1 3 3 4 2 3 4 。
行成不同的N棵树,分别投喂同样的test数据,将结果取众数输出
随机:
1.数据选择随机:有放回采样,指定随机的采样比例,只选择所有样本中的一部分(几率过滤噪点)
2.关于特征随机:可能有些特征表达效果很差,通过随机有的能过滤掉这些差特征,选择一定比例的特征(无放回)
https://www.cnblogs.com/wj-1314/p/9428494.html


· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决
· 提示词工程——AI应用必不可少的技术