
5:Echarts数据可视化-多条曲线、多个子图、TreeMap类似盒图、树形图、热力图、词云
〇、目标
本次实验主要基于Echarts的Python库实现高维数据、网络和层次化数据、时空数据和文本数据的可视化,掌握可视化的操作流程和相关库的使用。
一、绘制平行坐标系
平行坐标是信息可视化的一种重要技术。为了克服传统的笛卡尔直角坐标系 难以表达三维以上数据的问题, 平行坐标将高维数据的各个变量用一系列相互平行的坐标轴表示, 变量值对应轴上位置。 为了反映变化趋势和各个变量间相互关系,将描述不同变量的各点连接成折线。
平行坐标因形式的紧凑型和表达的高效性,被广泛使用,但是每个点需要多个像素,数据量大,容易产生视觉混淆。
1、启动Python编辑工具IDLE
双击桌面IDLE图标启动编辑器。

2、新建Python文件
在导航栏中选择File->New File 新建Python文件。
3、编写Python程序
在弹出的新窗口中编写代码如下:
from pyecharts import options as opts from pyecharts.charts import Page, Parallel def parallel_base() -> Parallel: dataBJ = [[1,55,9,56,0.46,18,6,"4"], [2,25,11,21,0.65,34,9,"5"], [3,56,7,63,0.3,14,5,"4"], [4,33,7,29,0.33,16,6,"5"], [5,42,24,44,0.76,40,16,"5"], [6,82,58,90,1.77,68,33,"4"], [7,74,49,77,1.46,48,27,"4"], [8,78,55,80,1.29,59,29,"4"], [9,267,216,280,4.8,108,64,"1"], [10,185,127,216,2.52,61,27,"2"], [11,39,19,38,0.57,31,15,"5"], [12,41,11,40,0.43,21,7,"5"], [13,64,38,74,1.04,46,22,"4"], [14,108,79,120,1.7,75,41,"3"], [15,108,63,116,1.48,44,26,"3"], [16,33,6,29,0.34,13,5,"5"], [17,94,66,110,1.54,62,31,"4"], [18,186,142,192,3.88,93,79,"2"], [19,57,31,54,0.96,32,14,"4"], [20,22,8,17,0.48,23,10,"5"], [21,39,15,36,0.61,29,13,"5"], [22,94,69,114,2.08,73,39,"4"], [23,99,73,110,2.43,76,48,"4"], [24,31,12,30,0.5,32,16,"5"], [25,42,27,43,1,53,22,"5"], [26,154,117,157,3.05,92,58,"2"], [27,234,185,230,4.09,123,69,"1"], [28,160,120,186,2.77,91,50,"2"], [29,134,96,165,2.76,83,41,"3"], [30,52,24,60,1.03,50,21,"4"], [31,46,5,49,0.28,10,6,"5"]]; dataGZ = [[1,26,37,27,1.163,27,13,"5"], [2,85,62,71,1.195,60,8,"4"], [3,78,38,74,1.363,37,7,"4"], [4,21,21,36,0.634,40,9,"5"], [5,41,42,46,0.915,81,13,"5"], [6,56,52,69,1.067,92,16,"4"], [7,64,30,28,0.924,51,2,"4"], [8,55,48,74,1.236,75,26,"4"], [9,76,85,113,1.237,114,27,"4"], [10,91,81,104,1.041,56,40,"4"], [11,84,39,60,0.964,25,11,"4"], [12,64,51,101,0.862,58,23,"4"], [13,70,69,120,1.198,65,36,"4"], [14,77,105,178,2.549,64,16,"4"], [15,109,68,87,0.996,74,29,"3"], [16,73,68,97,0.905,51,34,"4"], [17,54,27,47,0.592,53,12,"4"], [18,51,61,97,0.811,65,19,"4"], [19,91,71,121,1.374,43,18,"4"], [20,73,102,182,2.787,44,19,"4"], [21,73,50,76,0.717,31,20,"4"], [22,84,94,140,2.238,68,18,"4"], [23,93,77,104,1.165,53,7,"4"], [24,99,130,227,3.97,55,15,"4"], [25,146,84,139,1.094,40,17,"3"], [26,113,108,137,1.481,48,15,"3"], [27,81,48,62,1.619,26,3,"4"], [28,56,48,68,1.336,37,9,"4"], [29,82,92,174,3.29,0,13,"4"], [30,106,116,188,3.628,101,16,"3"], [31,118,50,0,1.383,76,11,"3"]]; dataSH = [[1,91,45,125,0.82,34,23,"4"], [2,65,27,78,0.86,45,29,"4"], [3,83,60,84,1.09,73,27,"4"], [4,109,81,121,1.28,68,51,"3"], [5,106,77,114,1.07,55,51,"3"], [6,109,81,121,1.28,68,51,"3"], [7,106,77,114,1.07,55,51,"3"], [8,89,65,78,0.86,51,26,"4"], [9,53,33,47,0.64,50,17,"4"], [10,80,55,80,1.01,75,24,"4"], [11,117,81,124,1.03,45,24,"3"], [12,99,71,142,1.1,62,42,"4"], [13,95,69,130,1.28,74,50,"4"], [14,116,87,131,1.47,84,40,"3"], [15,108,80,121,1.3,85,37,"3"], [16,134,83,167,1.16,57,43,"3"], [17,79,43,107,1.05,59,37,"4"], [18,71,46,89,0.86,64,25,"4"], [19,97,71,113,1.17,88,31,"4"], [20,84,57,91,0.85,55,31,"4"], [21,87,63,101,0.9,56,41,"4"], [22,104,77,119,1.09,73,48,"3"], [23,87,62,100,1,72,28,"4"], [24,168,128,172,1.49,97,56,"2"], [25,65,45,51,0.74,39,17,"4"], [26,39,24,38,0.61,47,17,"5"], [27,39,24,39,0.59,50,19,"5"], [28,93,68,96,1.05,79,29,"4"], [29,188,143,197,1.66,99,51,"2"], [30,174,131,174,1.55,108,50,"2"], [31,187,143,201,1.39,89,53,"2"]]; c = ( Parallel() .add_schema( [ {"dim": 0, "name": "date"}, {"dim": 1, "name": "5QI"}, {"dim": 2, "name": "PM2.5"}, {"dim": 3, "name": "PM10"}, {"dim": 4, "name": "3O"}, {"dim": 5, "name": "NO2"}, {"dim": 6, "name": "SO2"}, {"dim": 7, "name": "Level"} ] ) .add("BJ", dataBJ) .add("SH", dataSH) .add("GZ", dataGZ) .set_global_opts(title_opts=opts.TitleOpts(title="Parallel")) ) return c c = parallel_base() c.render("/home/user/Desktop/parallel.html")
4、保存Python文件
在导航栏中选择File->Save,选择一个文件夹,为文件命名后保存文件。
5、执行Python代码
在菜单栏选择Run->Run Module 执行代码。
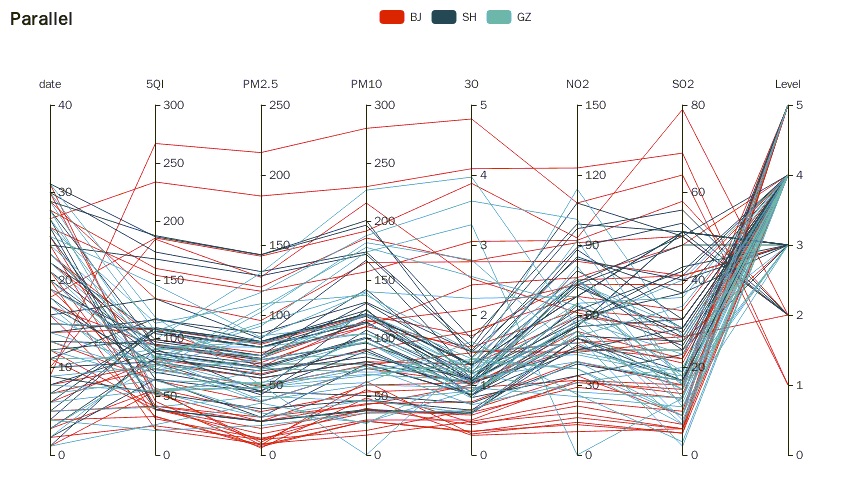
6、观察生成图像
代码执行完毕之后,会在桌面上生成一个名为parallel.html的文件,双击文件图标即可在浏览器中观察结果。实验结果如下图:

二、绘制散点图矩阵
散点图矩阵是双变量散点图在多变量情况下的拓展,展现了各个维度两两之间的数据关系。在矩阵中,每一行、每一列均代表一个维度,行与列的维度次序相同。格点中是相应行、列维度所组成的双变量散点图。其中上、下三角矩阵相互对称,可仅展示其中一个三角矩阵以节省显示空间。
1、启动编辑器并新建文件
双击桌面IDLE图标启动IDLE,并在菜单栏选择File->New File 新建Python文件。


2、编写Python程序
编写实验代码如下:
import matplotlib.pyplot as plt rawData=[[55,9,56,0.46,18,6,"good", "BJ"], [25,11,21,0.65,34,9,"verygood", "BJ"], [56,7,63,0.3,14,5,"good", "BJ"], [33,7,29,0.33,16,6,"verygood", "BJ"], [42,24,44,0.76,40,16,"verygood", "BJ"], [82,58,90,1.77,68,33,"good", "BJ"], [74,49,77,1.46,48,27,"good", "BJ"], [78,55,80,1.29,59,29,"good", "BJ"], [267,216,280,4.8,108,64,"severe", "BJ"], [185,127,216,2.52,61,27,"middle", "BJ"], [39,19,38,0.57,31,15,"verygood", "BJ"], [41,11,40,0.43,21,7,"verygood", "BJ"], [64,38,74,1.04,46,22,"good", "BJ"], [108,79,120,1.7,75,41,"light", "BJ"], [108,63,116,1.48,44,26,"light", "BJ"], [33,6,29,0.34,13,5,"verygood", "BJ"], [94,66,110,1.54,62,31,"good", "BJ"], [186,142,192,3.88,93,79,"middle", "BJ"], [57,31,54,0.96,32,14,"good", "BJ"], [22,8,17,0.48,23,10,"verygood", "BJ"], [39,15,36,0.61,29,13,"verygood", "BJ"], [94,69,114,2.08,73,39,"good", "BJ"], [99,73,110,2.43,76,48,"good", "BJ"], [31,12,30,0.5,32,16,"verygood", "BJ"], [42,27,43,1,53,22,"verygood", "BJ"], [154,117,157,3.05,92,58,"middle", "BJ"], [234,185,230,4.09,123,69,"severe", "BJ"], [160,120,186,2.77,91,50,"middle", "BJ"], [134,96,165,2.76,83,41,"light", "BJ"], [52,24,60,1.03,50,21,"good", "BJ"], [46,5,49,0.28,10,6,"verygood", "BJ"], [26,37,27,1.163,27,13,"verygood", "GZ"], [85,62,71,1.195,60,8,"good", "GZ"], [78,38,74,1.363,37,7,"good", "GZ"], [21,21,36,0.634,40,9,"verygood", "GZ"], [41,42,46,0.915,81,13,"verygood", "GZ"], [56,52,69,1.067,92,16,"good", "GZ"], [64,30,28,0.924,51,2,"good", "GZ"], [55,48,74,1.236,75,26,"good", "GZ"], [76,85,113,1.237,114,27,"good", "GZ"], [91,81,104,1.041,56,40,"good", "GZ"], [84,39,60,0.964,25,11,"good", "GZ"], [64,51,101,0.862,58,23,"good", "GZ"], [70,69,120,1.198,65,36,"good", "GZ"], [77,105,178,2.549,64,16,"good", "GZ"], [109,68,87,0.996,74,29,"light", "GZ"], [73,68,97,0.905,51,34,"good", "GZ"], [54,27,47,0.592,53,12,"good", "GZ"], [51,61,97,0.811,65,19,"good", "GZ"], [91,71,121,1.374,43,18,"good", "GZ"], [73,102,182,2.787,44,19,"good", "GZ"], [73,50,76,0.717,31,20,"good", "GZ"], [84,94,140,2.238,68,18,"good", "GZ"], [93,77,104,1.165,53,7,"good", "GZ"], [99,130,227,3.97,55,15,"good", "GZ"], [146,84,139,1.094,40,17,"light", "GZ"], [113,108,137,1.481,48,15,"light", "GZ"], [81,48,62,1.619,26,3,"good", "GZ"], [56,48,68,1.336,37,9,"good", "GZ"], [82,92,174,3.29,0,13,"good", "GZ"], [106,116,188,3.628,101,16,"light", "GZ"], [118,50,0,1.383,76,11,"light", "GZ"], [91,45,125,0.82,34,23,"good", "SH"], [65,27,78,0.86,45,29,"good", "SH"], [83,60,84,1.09,73,27,"good", "SH"], [109,81,121,1.28,68,51,"light", "SH"], [106,77,114,1.07,55,51,"light", "SH"], [109,81,121,1.28,68,51,"light", "SH"], [106,77,114,1.07,55,51,"light", "SH"], [89,65,78,0.86,51,26,"good", "SH"], [53,33,47,0.64,50,17,"good", "SH"], [80,55,80,1.01,75,24,"good", "SH"], [117,81,124,1.03,45,24,"light", "SH"], [99,71,142,1.1,62,42,"good", "SH"], [95,69,130,1.28,74,50,"good", "SH"], [116,87,131,1.47,84,40,"light", "SH"], [108,80,121,1.3,85,37,"light", "SH"], [134,83,167,1.16,57,43,"light", "SH"], [79,43,107,1.05,59,37,"good", "SH"], [71,46,89,0.86,64,25,"good", "SH"], [97,71,113,1.17,88,31,"good", "SH"], [84,57,91,0.85,55,31,"good", "SH"], [87,63,101,0.9,56,41,"good", "SH"], [104,77,119,1.09,73,48,"light", "SH"], [87,62,100,1,72,28,"good", "SH"], [168,128,172,1.49,97,56,"middle", "SH"], [65,45,51,0.74,39,17,"good", "SH"], [39,24,38,0.61,47,17,"verygood", "SH"], [39,24,39,0.59,50,19,"verygood", "SH"], [93,68,96,1.05,79,29,"good", "SH"], [188,143,197,1.66,99,51,"middle", "SH"], [174,131,174,1.55,108,50,"middle", "SH"], [187,143,201,1.39,89,53,"middle", "SH"]]; print(rawData[0:30]) print(rawData[31:62]) print(rawData[63:]) fig = plt.figure() for i in range(6): for j in range(6): if(j<=i): continue subfig=fig.add_subplot(5,5,i*5+j) subfig.scatter([x[i] for x in rawData[0:30]],[x[j] for x in rawData[0:30]],s=5,c='red') subfig.scatter([x[i] for x in rawData[31:62]],[x[j] for x in rawData[31:62]],s=5,c='green') subfig.scatter([x[i] for x in rawData[63:]],[x[j] for x in rawData[63:]],s=5,c='blue') plt.savefig("/home/user/Desktop/scatter.png") plt.show()
3、保存并执行程序
程序编写完成后,选择菜单栏File->Save 命名并保存文件。保存文件后,选择菜单栏Run->Run Module 执行程序。
4、观察实验结果
代码执行完毕后,会自动显示出实验结果,具体结果如下图,同时会在桌面上产生相对于的png图片
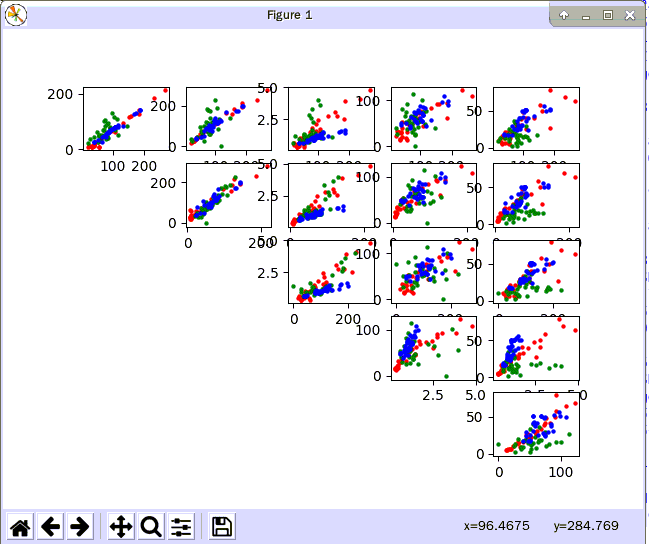
三、绘制TreeMap
TreeMap是一种基于二维空间填充的可视化方法,与传统的层次结构数据可视化方法相比,可以提高屏幕显示空间的利用率,充分利用显示空间的每一个象素,更适合对大型的层次结构数据进行可视化,例如树状的目录结构。
1、启动IDLE编辑器并新建文件
双击桌面IDLE图标启动编辑器,并选择菜单栏File->New File新建文件。


2、编写Python程序
在新建的文件窗口中编写代码如下:
import json import os from pyecharts import options as opts from pyecharts.charts import Page, TreeMap def treemap_base() -> TreeMap: with open("/home/user/Data/disk.tree.json","r") as tree_f: data = json.load(tree_f) c = ( TreeMap() .add("present data", data) .set_global_opts(title_opts=opts.TitleOpts(title="TreeMap")) ) return c c = treemap_base() c.render("/home/user/Desktop/treemap.html")
3、保存并执行代码
选择File->Save保存程序。
保存完成后,选择Run->Run Module执行代码

4、观察实验结果
代码执行结束后,会在桌面生成treemap.html文件,双击文件即可在浏览器中观察结果。
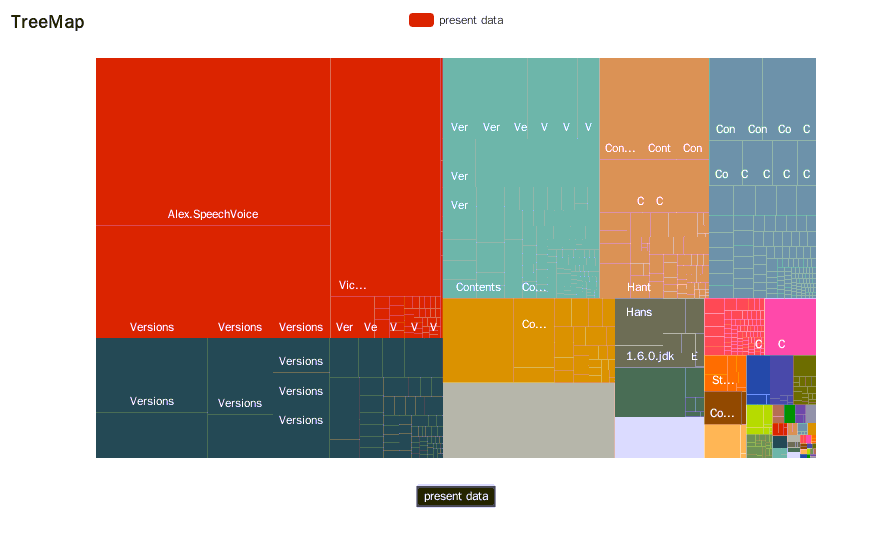
四、绘制树形图
树形图直接将节点之间的父子关系映射到视觉元素中,采用树状结构对层次结构数据进行可视化也是一种非常有效的手段。
1、启动编辑器
新建文件双击桌面IDLE图标,并选择File->New File新建文件

2、编写Python程序
在新建的文件窗口中编辑代码如下:
import json import os from pyecharts import options as opts from pyecharts.charts import Page, Tree def tree_lr() -> Tree: with open("/home/user/Data/flare.json") as f: j = json.load(f) c = ( Tree() .add("", [j], collapse_interval=2) .set_global_opts(title_opts=opts.TitleOpts(title="Tree")) ) return c c = tree_lr() c.render("/home/user/Desktop/tree.html")
3、保存并执行程序
选择File->Save 保存文件
选择Run->Run Module执行代码。

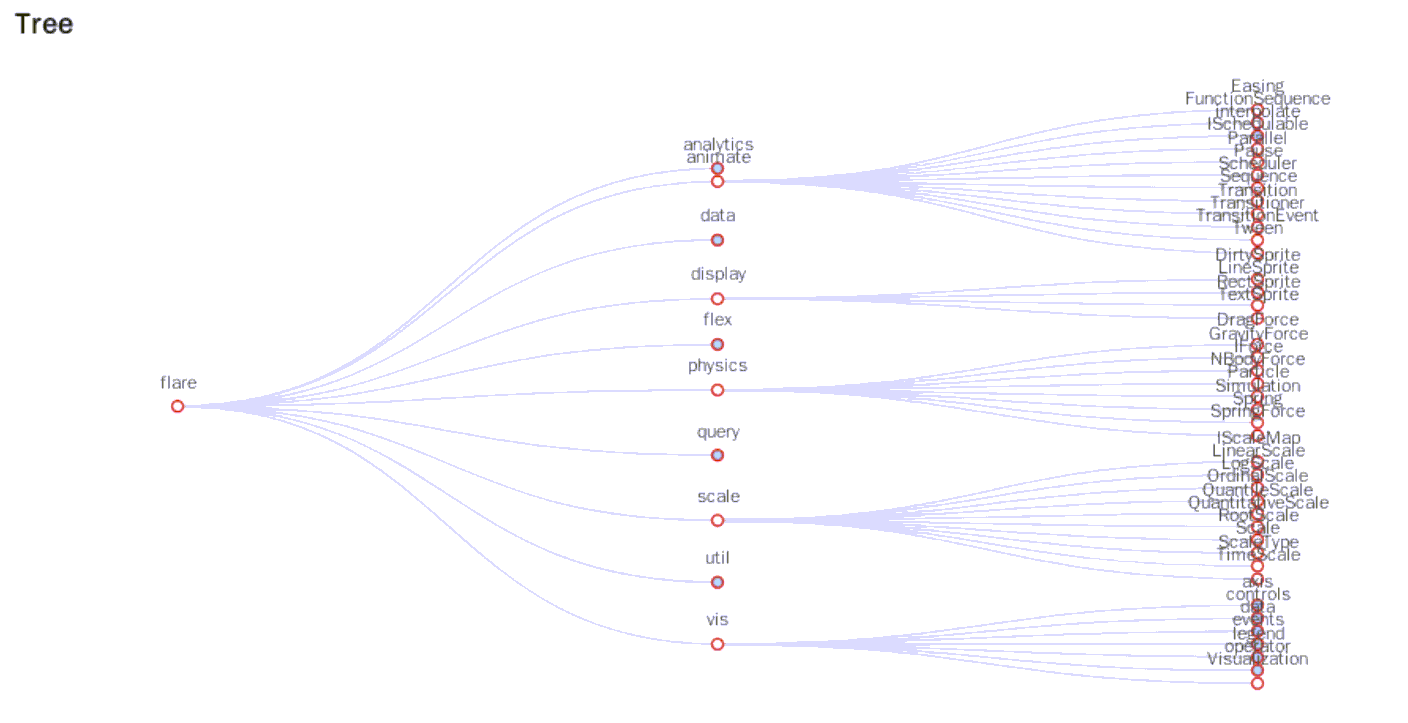
4、观察实验结果
代码执行结束后,会在桌面上生成tree.html文件,双击图标即可在浏览器中观察结果。
五、绘制热力图
1、启动编辑器并新建文件
双击桌面IDLE图标,启动IDLE
选择菜单栏File->New File新建文件

2、编写Python程序
在新建的文件窗口中编写代码如下:
from example.commons import Faker from pyecharts import options as opts from pyecharts.charts import Geo from pyecharts.globals import ChartType, SymbolType def geo_heatmap() -> Geo: c = ( Geo() .add_schema(maptype="china") .add( "geo", [list(z) for z in zip(Faker.provinces, Faker.values())], type_=ChartType.HEATMAP, ) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) .set_global_opts( visualmap_opts=opts.VisualMapOpts(), title_opts=opts.TitleOpts(title="Geo-HeatMap"), ) ) return c c = geo_heatmap() c.render("/home/user/Desktop/heatmap.html")
3、保存并执行程序
选择菜单栏File->Save File保存文件
选择菜单栏Run->Run Module执行代码


4、观察实验结果
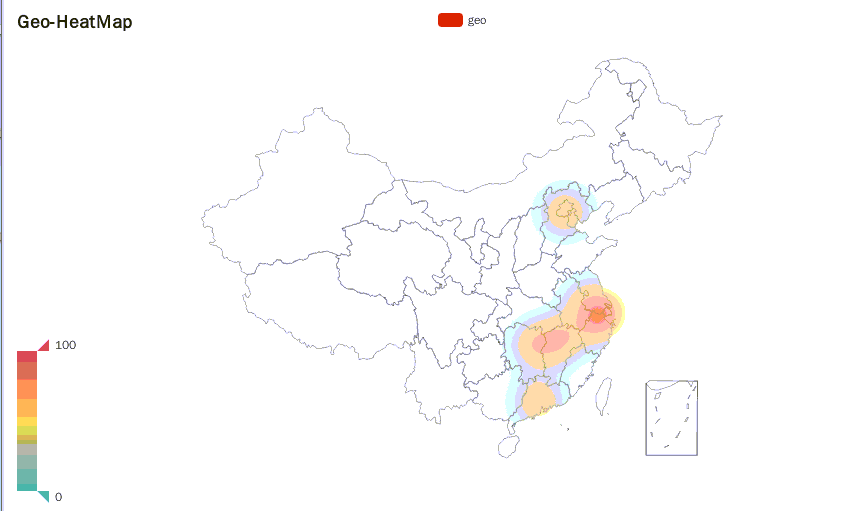
代码执行完毕后,会在桌面上生成一个名为heatmap.html的文件,双击文件图标即可在浏览器中观察实验结果
六、绘制词云
词云是一种典型的文本可视化技术。该方法把文本数据中的关键词根据出现的频率等规则进行统计,然后进行布局排列,利用颜色、大小等视觉编码其频率信息,该方法可以帮助用户对大规模文本数据有一个概览,已经被广泛用在众多的网站和博客中。
1、启动编辑器并新建文件
双击桌面IDLE图标,启动编辑器。
选择菜单栏File->New File 新建文件

2、编写Python代码
在新建的窗口中编写代码如下:
from pyecharts import options as opts from pyecharts.charts import Page, WordCloud from pyecharts.globals import SymbolType words = [ ("C++", 10000), ("C", 6181), ("Java", 4386), ("Python", 4055), ("JavaScript", 2467), ("PHP", 2244), ("XML", 1868), ("Pascal", 1484), ("C#", 1112), ("Object-C", 865), ("HasKell", 847), ("Lisp", 582), ("SQL", 555), ("LabVIEW", 550), ("Logic-based", 462), ("Ada", 366), ("Clojure", 360), ("Ruby", 282), ("Erlang", 273), ("MATLAB", 265), ] def wordcloud_base() -> WordCloud: c = ( WordCloud() .add("", words, word_size_range=[20, 100]) .set_global_opts(title_opts=opts.TitleOpts(title="WordCloud")) ) return c c = wordcloud_base() c.render("/home/user/Desktop/wordcloud.html")
3、保存并执行Python文件
选择File->Save File保存文件。
文件保存结束后,选择Run->Run Module执行程序

4、观察实验结果
程序执行结束后,会在桌面生成wordcloud.html文件,双击文件图标即可在浏览器中观察结果

本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/16391085.html

