

4.8:数据获取和存储综合
〇、概述
1、拓扑结构

2、目标
进行kafka,flume,和hive的数据综合处理实验
一、实验过程
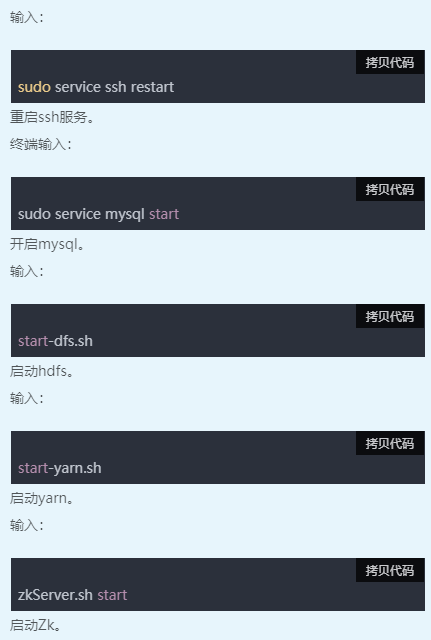
1、启动环境
2、hive操作
输入hive
进入hive,输入 create table kafkatest(id int,name string,age int) clustered by(id) into 2 buckets stored as orc tblproperties('transactional'='true');
创建一张表,用来盛放数据。
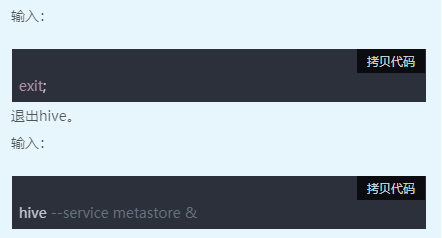
启动元数据服务
3、kafka操作

nohup bin/kafka-server-start.sh config/server.properties >~/bigdata/kafka_2.11-1.0.0/logs/server.log 2>&1 &
后台启动kafka。(进程数字可以不同)

输入:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic kafkatest
创建一个新的topic

4、flume操作
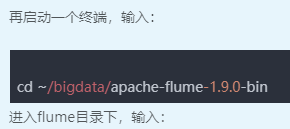
bin/flume-ng agent --conf conf/ --conf-file conf/kafkatohive.conf --name a -Dflume.root.logger=INFO,console
启动flume
回到kafka目录下的终端,输入:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafkatest
启动kafka的consumer。

向启动好的kafka中输入1,a,3(1对应hive表中的id,a对应name,3对应age,可以进行适当更换)。发现flume的终端在执行任务。最后启动一个新的终端,输入hive,输入select * from kafkatest;可以查看到刚才键入的数据。

退出hive:exit
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/16386851.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
2021-06-17 【重难点】常见排序算法表述及code
2021-06-17 【重难点】函数式接口、函数式编程、匿名内部类、Lambda表达式、语法糖
2021-06-17 笔面试知识点总结