
4.1:简单python爬虫
简单python爬虫
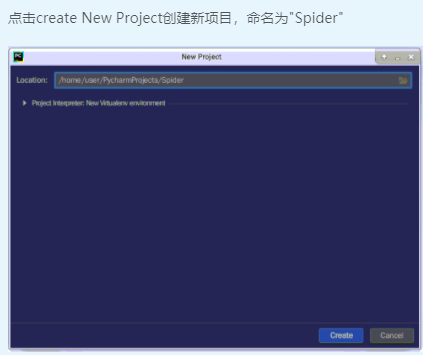
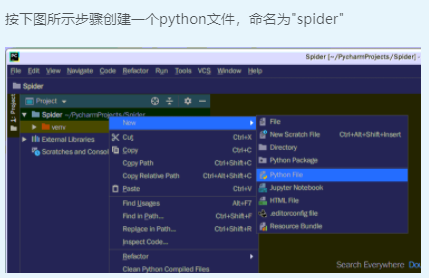
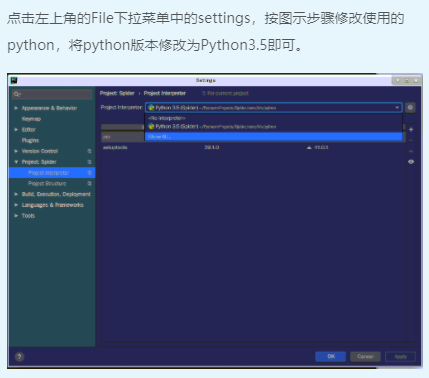
在创建的python文件中输入下列代码:
# coding:utf-8 import requests from bs4 import BeautifulSoup def spider(url,headers): with open('renming.txt', 'w', encoding='utf-8') as fp: r = requests.get(url, headers=headers) r.encoding = 'gb2312' # test=re.findall('<li>< a href= >(.*?)</ a></li>',r.text) # print(test) soup = BeautifulSoup(r.text, "html.parser") for news_list in soup.find_all(class_="list14"): content = news_list.text.strip() fp.write(content) fp.close() if __name__=="__main__": headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ' 'AppleWebKit/537.36 (KHTML, like Gecko)' ' Chrome/55.0.2883.87 Safari/537.36'} url = 'http://www.people.com.cn/' spider(url, headers)
如果代码中存在报错,请在PyCharm最下边找到Terminal,点击Terminal后Pycharm底部控制台处会出现其自带的命令行窗口,输入下面两条命令即可解决报错:pip install requestspip install bs4解决完报错之后,在代码文件的任意处右击,点击Run,之后就会发现在代码文件目录中出现了renmin.txt,里面是爬取的人民网的数据。

本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/16382415.html

