

2.10:数据加工与展示-pandas清洗、Matplotlib绘制
〇、目标
1、 使用pandas完成基本的数据清洗加工处理;
2、 使用Matplotlib进行简单的数据图形化展示。
一、用pandas清洗处理数据
1、判断是否存在空值


数据缺失在很多数据中存在,是首先要解决的常见问题。NaN(Not a Number)在NumPy中是浮点值,易检测。而Python的None关键字在数组中也被作为NaN处理。需要注意的是,Python本身并没有定义NaN,而numpy中定义了NaN。因此使用的使用,要明确使用np.NaN。None是在Python中定义的,可以直接使用。Pandas提供isnull和notnull两个方法来判断Series对象或DataFrame对象中是否存在空值。其输出结果是一个有True和False组成的bool类型的Series对象或DataFrame对象。
2、过滤空值
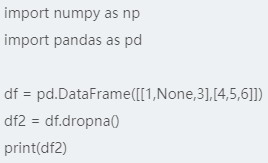

Series过滤空值时,直接过滤掉空值所在的数据和对应的索引。DataFrame过滤空值时,dropna()默认会删除包含缺失值的行,传入how=‘all’参数时,删除所有值均为NaN的行;传入axis=1,可以按照同样的方式删除列。注意在生成DataFrame时,None默认被标记为float,所以对应的列中,整数5也被转化成5.0。另外,dropna方法返回一个新的DataFrame对象,原来的DataFrame对象不变。
3、补全空值
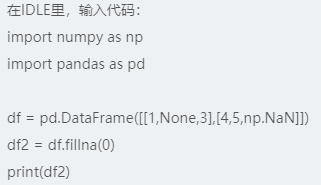

Dropna()简单粗暴,抛弃了其他非空数据,因此可以采取补全数据的方式,如fillna()。补全时,可以使用常数补全,如fillna(0);或者用字典补全,即为不同的列设置不同的填充值,字典的键就是列的索引名,如fillna({1:0.5, 2:0})。需要注意的是,默认fillna()返回一个新的对象。如果需要在原对象上修改数据,可设定inplace=True修改原对象,如df.fillna(0, inplace=True)。空值补全时可能会污染数据,比如错误的补全值。一般可以使用插值方法来填充,如前向填充:fillna(method=“ffile”, limit=2),或者将Series的平均值或中位数填充NaN,如data.fillna(data.mean())。
4、删除重复值

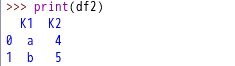
由于各种原因,DataFrame中会出现重复的行。可以使用DataFrame的duplicated()用于判断某行是否重复,返回一个Series对象,由True和False构成。可以使用drop_duplicates()直接返回不重复的值,还可以指定特定列,如:drop_duplicates([‘K1’])。
5、检测和过滤异常值

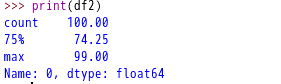
异常值(outlier)指的是在正常情况下,不可能产生的数值,比如在正常的水温测试过程中,水温在100摄氏度一下,人的年龄一般在120岁以内,大于零岁。异常值的过滤或变换运算在很大程度上其实就是数组运算。DataFrame的describe方法可以返回该DataFrame对象的数据进行统计信息展示。比如最大最小值,均值等。我们假定超过50的数据为异常值,可以通过使用any方法选出全部满足条件的行,比如any(1)表示一行中有1个数据满足即可进行过滤。
6、数据排序


Sort_index()在指定轴上对索引排序,默认升序,默认0轴(行)。Sort_values()在指定轴上根据数值进行排序,默认升序。如果排序的DataFrame中存在NaN数据,则排序末尾(最大或最小)。此外,Pandas还提供了一个更简单的取前n行最大值的函数:Nlargest(),使用方法为:df.nlargest(3,'A'),即取A列中最大的前3行数据。
7、空值替换

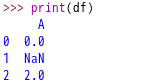
使用fillna填充空值是通用值替换的特殊例子。对于不同的数据源,对空值的标识可能不同,如有的使用-999标识空值。如果需要对这些非标准空值进行NaN替换,可以使用replace方法。可以替换单值:Df.replace( -999,np.NaN, inplace = True)或列表:Df.replace( [-999, -1000], np.NaN)或列表对:Df.replace( [-999, -1000], [np.NaN,0])或字典:Df.replace( {-999: np.NaN, -1000:0})。df的iloc方法,可以接收行号和列号进行选取。如果df.iloc[3][4]表示第三行,第四列。如果使用loc方法,则需要使用行号和列名,如df.loc[3][“A”]。
二、Matplotlib展示数据
1、使用plot函数绘制曲线

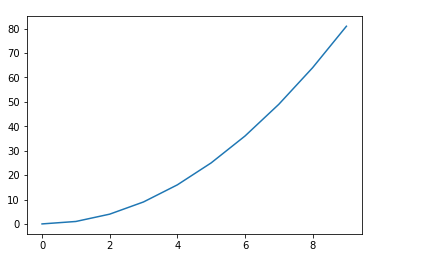
Matplotlib用于在python环境下进行Matlab风格的绘图,使用时主要使用其接口库pyplot,使用前先导入:import matplotlib.pyplot as plt。普通的曲线使用plot函数即可完成,plot函数的参数角度。但大多有默认参数。只需要输入x和y轴的数据即可绘制出一条默认风格曲线图。
2、使用控制字符串

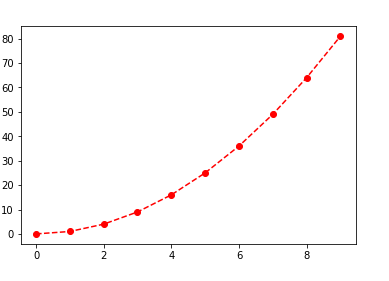
控制字符依次包括:颜色字符、风格字符和标记字符。其中,颜色字符:r、g、b等,或 数字格式'#008080';风格字符:- 、-- 、-.、 |(实线、虚线、点画线等);标记字符:.、,、v、<、>等;也可以使用显式表达,如color=“g”,linestyle=“dashed”,marker =“o”等。
3、图形中的文本

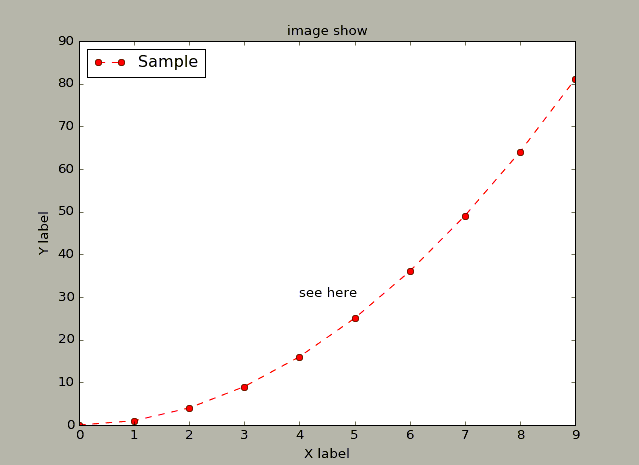
在Matplotlib中有丰富的图形文本设置,如:设置标题title(),图例标注label,X轴标注xlabel(),Y轴标:ylabel(),文本信息text()等。默认情况下,不能显示汉字,如果需要显示汉字,可设置fontproperties参数,指定使用的字体即可。
4、多线绘制

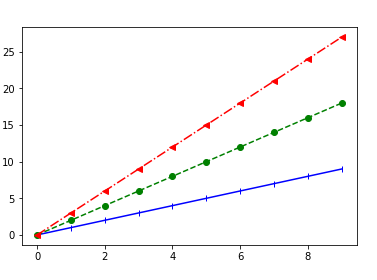
通过查看plot的函数原型,可以发现:plot([x], y, [fmt], [x2], y2, [fmt2], ..., **kwargs),其中x轴数据可省略,而y轴数据不可省略。如果不设定多线的格式控制,系统自动区分。除了设置多个y轴数据,plot函数还可以直接接受多维数组。
5、多子图绘制1

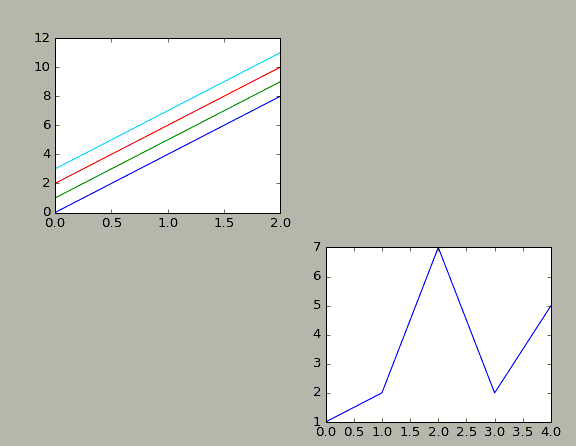
使用subplot函数,可以把多个子图绘制在一起。其原型为:plt.subplot(rows, cols, number),需要指定行列和当前正在绘制的编号,编号从左到右,从上到下,行优先。如plt.subplot(2,2,1)表示绘制2行2列的多子图,当前绘制位置是第1,subplot(2,2,4)则表示第四个位置(从上到下,都左到右)。
6、多子图绘制2
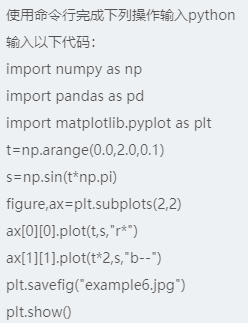
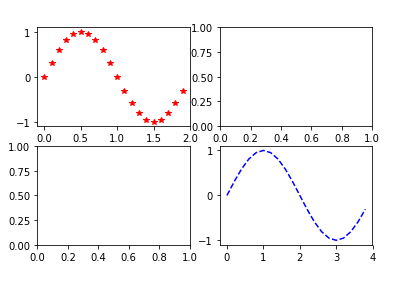
subplots函数可以生成一个画布和多个子图。其原型为:fig,ax = subplots(nrows, ncols, sharex, sharey, squeeze, subplot_kw, gridspec_kw, **fig_kw) 。 nrows和ncols表示将画布分割成几行几列 例:nrows = 2,ncols = 2表示将画布分割为2行2列,并起始值都为0,当调用画布中的坐标轴时,ax[0,0]表示调用坐上角的,ax[1,1]表示调用右下角的;sharex和sharey表示坐标轴的属性是否相同,可选的参数:True,False,row,col,默认值均为False,表示画布中的四个ax是相互独立的;当sharex = True, sharey = True时,生成的四个ax的所有坐标轴用有相同的属性;简单起见,直接使用二维索引的方式来获得指定的子图,并直接使用子图的plot方法进行绘制,如ax[0][0].plot(…),在一个2行2列的画布上的第一个子图中绘制。
7、不同的绘图风格

pie函数用于绘制饼图。饼图常用的设置属性包括:x,(每一块)的比例,如果sum(x) > 1会使用sum(x)归一化;labels :(每一块)饼图外侧显示的说明文字;explode :(每一块)离开中心距离;startangle :起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起;shadow :在饼图下面画一个阴影。默认值:False,即不画阴影;labeldistance :label标记的绘制位置,相对于半径的比例,默认值为1.1, 如<1则绘制在饼图内侧;autopct :控制饼图内百分比设置,可以使用format字符串或者format function'%1.1f'指小数点前后位数(没有用空格补齐)。其他设置参数,请参阅使用手册。
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/16375135.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· 地球OL攻略 —— 某应届生求职总结
2021-06-14 福利合辑
2021-06-14 【Java EE】Day14 Servlet、HTTP、Request
2021-06-14 【Java EE】Day13 Web概念回顾、Tomcat、Servlet