
【大数据课程】高途课程实践-Day01:Python编写Map Reduce函数实现各商品销售量展示(类似wordcount)
〇、概述
1、工具
http://www.dooccn.com/python3/
在线运行Python代码
2、步骤
(1)⽣成代码测试数据
(2)编写Mapper逻辑
(3)编写Reducer逻辑
(4)提交并执行
一、⽣成代码测试数据
运行代码,输出50个人,分别购买3种商品的数据
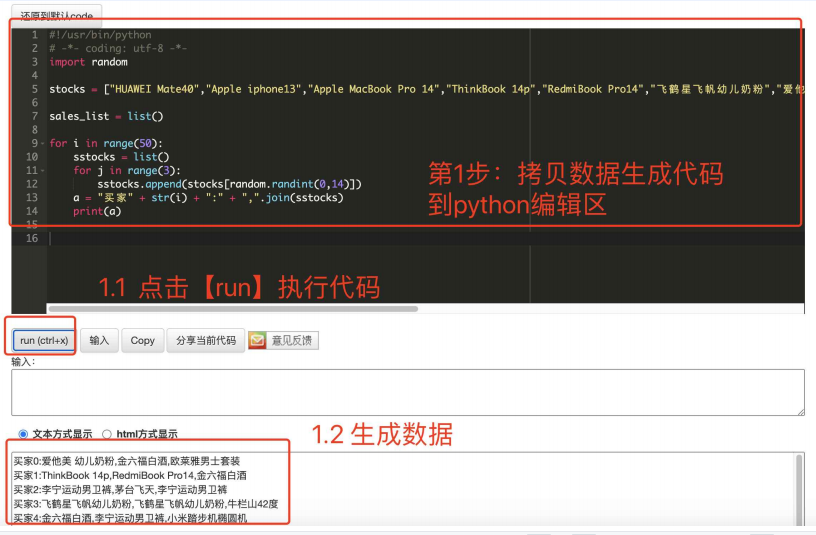
代码:
#!/usr/bin/python # -*- coding: utf-8 -*- import random stocks = ["HUAWEI Mate40","Apple iphone13","Apple MacBook Pro 14","ThinkBook 14p","RedmiBook Pro14","飞鹤星飞帆幼儿奶粉","爱他美 幼儿奶粉","李宁运动男卫裤","小米踏步机椭圆机","欧莱雅面膜","御泥坊面膜","欧莱雅男士套装","金六福白酒","牛栏山42度","茅台飞天"] sales_list = list() for i in range(50): sstocks = list() for j in range(3): sstocks.append(stocks[random.randint(0,14)]) a = "买家" + str(i) + ":" + ",".join(sstocks) print(a)
二、编写Mapper逻辑
拷⻉第1步1.2 ⽣成的数据到输⼊框中,然后参考mapper.py代码进⾏编辑程序
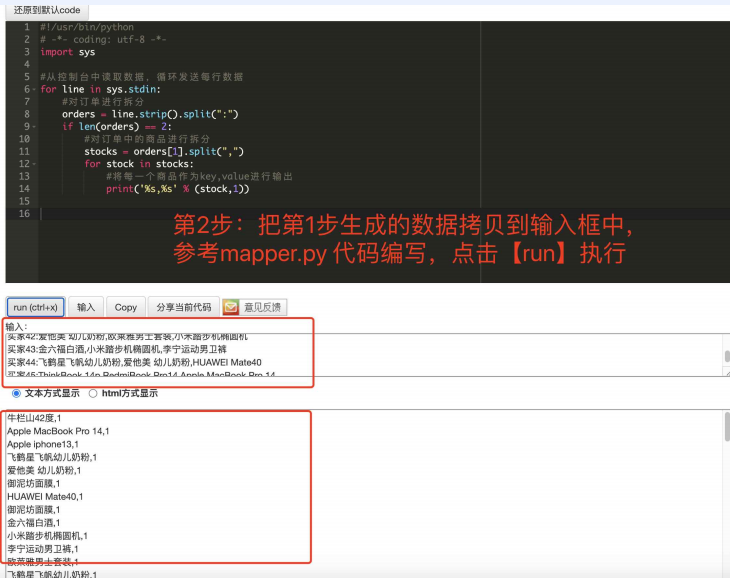
代码:
#!/usr/bin/python # -*- coding: utf-8 -*- import sys #从控制台中读取数据,循环发送每行数据 for line in sys.stdin: #对订单进行拆分 orders = line.strip().split(":") if len(orders) == 2: #对订单中的商品进行拆分 stocks = orders[1].split(",") for stock in stocks: #将每一个商品作为key,value进行输出 print('%s,%s' % (stock,1))
三、编写Reducer逻辑
拷⻉第2步⽣成的数据到输⼊框中,然后参考reducer.py代码进⾏编辑程序
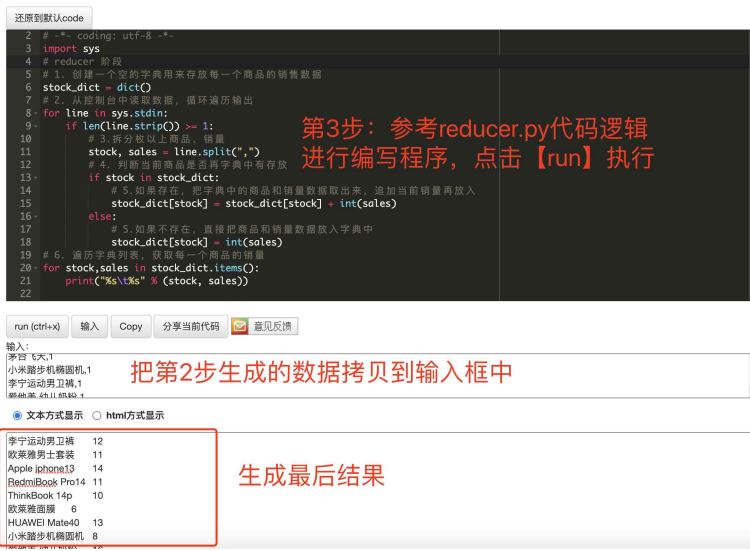
代码:
#!/usr/bin/python # -*- coding: utf-8 -*- import sys # 创建一个空的字典用来每一个商品的销售数据 stock_dict = dict() for line in sys.stdin: if len(line.strip()) >= 1: # 拆分每一行的商品,销量 stock, sales = line.split(',') # 判断当前商品是否在字典中有存放 if stock in stock_dict: # 如果有,把字典中的商品和销量取出来,追加当前销量再放入 stock_dict[stock] = stock_dict[stock] + int(sales) else: # 如果没有,直接把商品和销量数据放入字典中 stock_dict[stock] = int(sales) # 遍历字典列表,获取每一个商品的销量 for stock, sales in stock_dict.items(): print('%s\t%s' % (stock, sales))
最终结果:各个商品的购买次数
四、提交并执行
# hadoop jar 使用hadoop命令调用jar资源 # 运行streaming程序所在的资源位置(路径) hadoop jar /usr/local/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar -file mapper.py # 表示mapper程序所在位置 -mapper "python mapper.py" # 表示将要调用的map执行程序脚本 -file reduce.py # 表示reducer程序所在位置 -reducer "python reducer.py" # 表示将要调用的reduce执行程序脚本 -input /input/data # 数据的输入目录 -output /output # 数据的输出目录
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15941000.html

