
【面试真题】翼支付-初试-2022年2月17日-面试复盘
一、Java相关
1、java的访问修饰符?(权限修饰符)
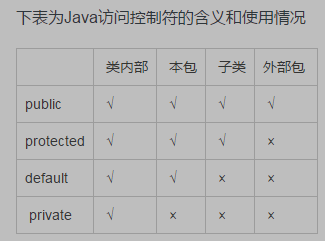
2、protected和private有什么区别?
允许所有外部类访问使用public
允许子类和同包类访问使用protected
只能自己访问使用private
访问权限修饰符权限从高到低排列是public ,protected ,friendly, private。
3、HashMap的组成中,为什么要选用红黑树?
红黑树相当于排序数据,可以自动的使用二分法进行定位,性能较高。
使用哈希值作为树的分支变量,如果两个哈希值不等,但指向同一个桶的话,较大的那个会插入到右子树里。如果哈希值相等,HashMap希望key值最好是实现了Comparable接口的,这样它可以按照顺序来进行插入。
4、红黑树、B树、B+树、AVL树能否使用,以及对应的使用场景?
红黑树牺牲了一些查找性能 但其本身并不是完全平衡的二叉树。因此插入删除操作效率略高于AVL树。
AVL树用于自平衡的计算牺牲了插入删除性能,但是因为最多只有一层的高度差,查询效率会高一些。
(1)红黑树--并不是完全平衡的二叉树
根黑子黑红子黑
查找效率与AVL树相似,但其插入删除效率比AVL树高
红黑树牺牲了一些查找性能 但其本身并不是完全平衡的二叉树。因此插入删除操作效率略高于AVL树。
AVL树用于自平衡的计算牺牲了插入删除性能,但是因为最多只有一层的高度差,查询效率会高一些。
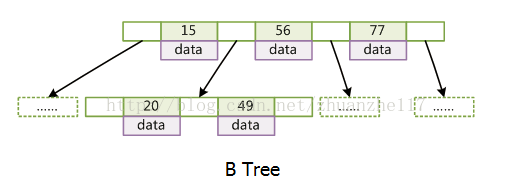
(2)B树-每个节点都存键和值
每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null。
(3)B+树-叶节点存键和值
只有叶子节点存储data,叶子节点包含了这棵树的所有键值,叶子节点不存储指针。
所有关键字都在叶子结点出现
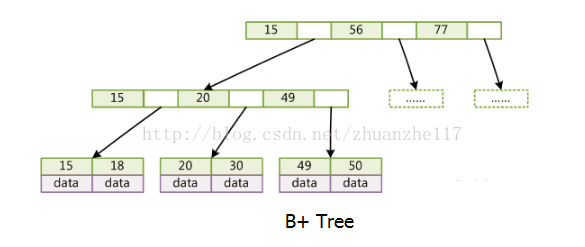
在B+树上增加了顺序访问指针,也就是每个叶子节点增加一个指向相邻叶子节点的指针,这样一棵树成了数据库系统实现索引的首选数据结构。
5、接口和抽象类有什么区别?
(1)接口只有定义,不能有方法的实现,java 1.8中可以定义default方法体,而抽象类可以有定义与实现,方法可在抽象类中实现。【有无方法的实现】
(2)实现接口的关键字为implements,继承抽象类的关键字为extends。一个类可以实现多个接口,但一个类只能继承一个抽象类。所以,使用接口可以间接地实现多重继承。
(3)接口强调特定功能的实现,而抽象类强调所属关系。【一个强调功能,一个强调类之间的关系】
(4)接口成员变量默认为public static final,必须赋初值,不能被修改;其所有的成员方法都是public、abstract的。抽象类中成员变量默认default,可在子类中被重新定义,也可被重新赋值;抽象方法被abstract修饰,不能被private、static、synchronized和native等修饰,必须以分号结尾,不带花括号。【变量修饰符】
(5)接口被用于常用的功能,便于日后维护和添加删除,而抽象类更倾向于充当公共类的角色,不适用于日后重新对立面的代码修改。功能需要累积时用抽象类,不需要累积时用接口。【是否可以进行代码修改】
6、MySQL中使用B+树做索引时,是聚簇索引还是非聚簇索引?
区别:叶子结点上的data是数据本身还是数据存放的地址
默认是聚簇索引!!!
(1)聚簇索引
主索引文件和数据文件为同一份文件,聚簇索引主要用在Innodb存储引擎中。在该索引实现方式中B+Tree的叶子节点上的data就是数据本身,key为主键
(2)非聚簇索引
指B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。
二、大数据相关
1、Hadoop中的HDFS文件块,为什么为128M?
HDFS中平均寻址时间大概为10ms;
寻址时间为传输时间的1%时,为最佳状态;
所以最佳传输时间为10ms/0.01=1000ms=1s
目前磁盘的传输速率普遍为100MB/s;
计算出最佳block大小:100MB/s x 1s = 100MB
所以我们设定block大小为128MB。
ps:实际在工业生产中,磁盘传输速率为200MB/s时,一般设定block大小为256MB,磁盘传输速率为400MB/s时,一般设定block大小为512MB
2、为什么HDFS中块(block)不能设置太大,也不能设置太小
基于传输时间和寻址时间,以及对元数据的考虑
如果块设置过大,
一方面,从磁盘传输数据的时间会明显大于寻址时间,导致程序在处理这块数据时,变得非常慢;
另一方面,mapreduce中的map任务通常一次只处理一个块中的数据,如果块过大运行速度也会很慢。
如果块设置过小,
一方面存放大量小文件会占用NameNode中大量内存来存储元数据,而NameNode的内存是有限的,不可取;
另一方面文件块过小,寻址时间增大,导致程序一直在找block的开始位置。
三、项目相关
1、介绍一下项目
(1)数据查询:可以对Hive、Spark、Impala进行数据查询,实现编写SQL实现,并打印执行日志
(2)数据开发/仪表盘:可以查看各任务的执行状态
(3)日志数据通道:通过web实现增删改查topic等信息
(4)资源集市:配置业务表,实现资源集市,为用户分配项目、资源
(5)业务运维与告警:查看集群状况、任务数量,并能够添加告警
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15903752.html

