

【实习项目介绍】XXXXX大数据平台介绍
一、技术架构
1、整体介绍及架构
(1)概述
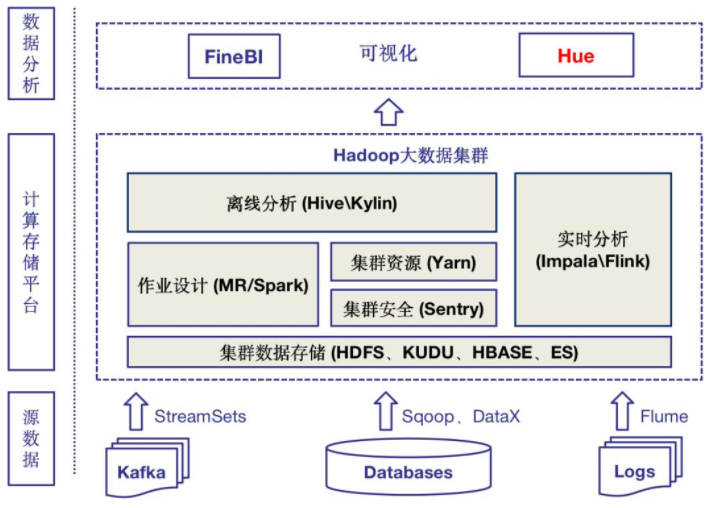
Odeon大数据平台以全图形化Web操作的形式为用户提供一站式的大数据能力:包括数据采集、任务编排、调度及处理、数据展现(BI)等;同时提供完善的权限管理、日志追踪、集群监控等能力
自己描述:一个PAAS平台即服务,全图形web操作构建数据闭环,实现多源数据导入、导出及分析、多源SQL数据查询、元数据和日志管理、工作流调度、快速部署
简述:数据采集(结构数据和日志数据sqoop)、数据开发(oozie工作流调度&仪表盘监控、HBASE使用Phoenix查询)、数据分析(OLAP基于kylin查询,支持kafka、hdfs等多数据源,可以整合BI工具)、数据编程(HUE使用统一的8888端口管理)
(2)组成
Odeon大数据平台主要由以下几部分组成:
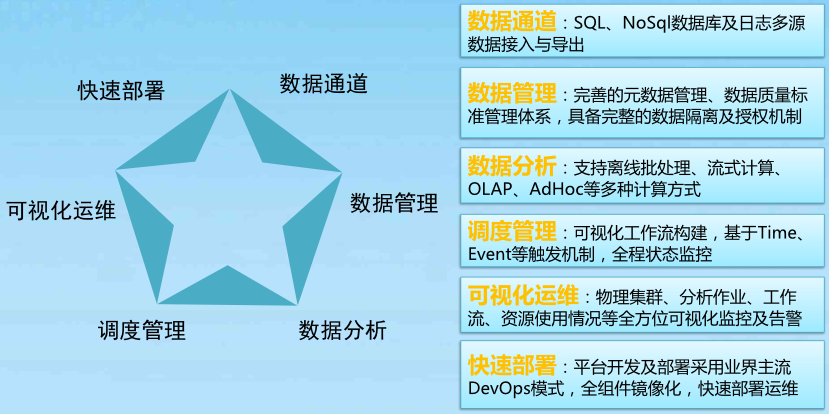
多源头数据通道:SQL、NoSql数据库及日志多源数据接入与导出
元数据和日志数据管理:元数据管理、数据质量标准管理体系,以及完整的数据隔离及授权机制
多源头数据分析:支持离线批处理、流式计算、OLAP、AdHoc等多种计算方式
SQL数据查询服务:基于Greenplum和Kylin的数据服务架构,提供DaaS服务
工作流调度管理与状态监控:可视化工作流构建,基于Time、Event等触发机制,全程状态监控
可视化运维:物理集群、分析作业、工作流、资源使用情况等全方位可视化监控及告警
快速部署:DevOps模式,全组件镜像化,实现快速部署运维
(3)架构图
2、使用技术
(1)大数据:Hadoop、Spark、HBASE、Hive
(2)中间件:Kylin、k8s、Druid、Oozie、Impala
二、实现功能
1、功能分类
(1)数据查询:可以对Hive、Spark、Impala进行数据查询,实现编写SQL实现,并打印执行日志
(2)数据开发/仪表盘:可以查看各任务的执行状态
(3)日志数据通道:通过web实现增删改查topic等信息
(4)资源集市:配置业务表,实现资源集市,为用户分配项目、资源
(5)业务运维与告警:查看集群状况、任务数量,并能够添加告警
2、具体细节
0987
三、实际使用
1、kafka的QPS、TPS吞吐量及并发量
(1)吞吐量(Throughput)
系统在单位时间内处理请求的数量、上传下载流量
(2)QPS每秒查询率(Query Per Second)
对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
一天有10万pv(访问量),
公式 (100000 * 80%) / (86400*20%) = 4.62 QPS(峰值时间的每秒请求)
(3)并发量
并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量。
(4)指标值
吞吐量:60-70M/s
qps查询率:10以内/s
并发量:峰值1-2w条数据/s
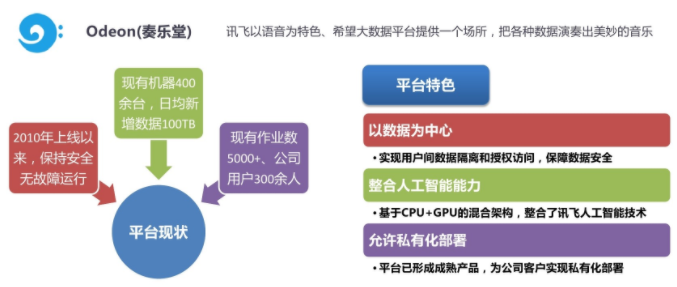
2、占用多大空间
每日新增数据100TB,共有400多台机器
四、完成工作
234
五、项目资料和截图
567
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15876802.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix