
【大数据面试】Hbase:数据、模型结构、操作、读写数据流程、集成、优化
一、概述
1、概念
分布式、可扩展、海量数据存储的NoSQL数据库
2、模型结构
(1)逻辑结构
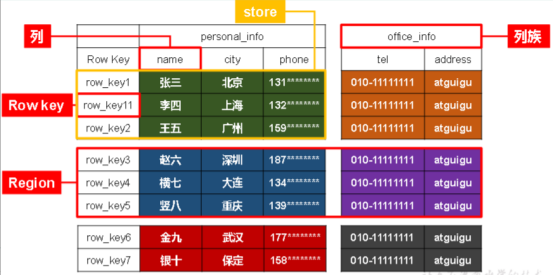
store相当于某张表中的某个列族
(2)存储结构
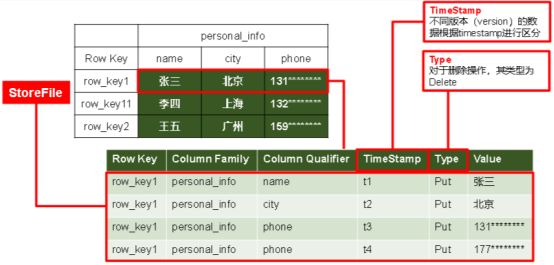
(3)模型介绍
Name Space:相当于数据库,包含很多张表
Region:类似于表,定义表时只需要声明列族,不需要声明具体的列。【字段可以动态、按需指定】
Row:每行数据按RowKey字典序存储,且只能根据RowKey检索
Column:由Column Family(列族)和Column Qualifier(列限定符,即列名,无需预先定义)进行限定,例如info:name,info:age。
Column Family:列族
Time Stamp:标识数据的不同版本
Cell:由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元/记录?
3、Hbase架构
(1)结构图
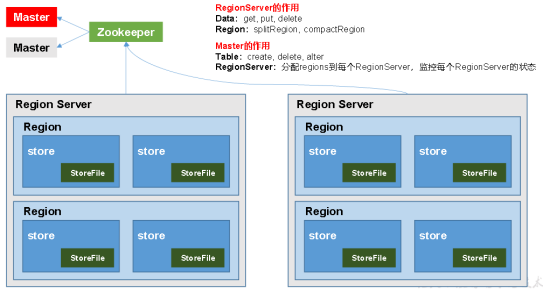
(2)架构角色
Region Server:Region的管理者,其实现类为HRegionServer,可以实现对数据的操作(get, put, delete)和对Region的操作(splitRegion、compactRegion)
Master:Region Server的管理者,实现类为HMaster,可以实现对表的操作(create, delete, alter)和对Region Server的操作(分配regions、监控ser的状态、负载均衡和故障转移)
Zookeeper:Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护
HDFS:底层数据存储、HBase的高可用
二、操作及进阶
1、入门操作
(1)启动
分别启动:bin/hbase-daemon.sh start master及regionserver
共同启动:bin/start-hbase.sh,查看页面:http://hadoop102:16010
配置HMaster的HA高可用:backup-masters文件并同步scp
(2)常见操作
进入命令行:bin/hbase shell
表的操作:create、put、scan、describe、count、delete、truncate清空表、get 'student','1001'指定行,'info:name'指定列族: 列、drop删除表、
2、架构原理
StoreFile:实际保存的物理文件,以HFile的形式存储在HDFS上,数据有序
MemStore:写缓存,先存储在MemStore中,排好序再刷写到StoreFile
WAL:写内存容易数据丢失,先写在一个叫做Write-Ahead logfile的文件中,然后再写入MemStore中;系统出现故障的时候,数据可以通过这个日志文件重建。
3、写数据流程
Client通过zk获取Region Server地址
(追加)到WAL,写入对应的MemStore
向client发送ack,等到刷写时机后,将数据刷写到HFile
4、MemStore Flush数据刷写
memstore的总大小达到java_heapsize时
到达自动刷写的时间,也会触发memstore flush
5、StoreFile Compaction
memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile
为了减少HFile的个数,以及清理掉过期和删除的数据,会进行StoreFile Compaction。
Minor Compaction:临近的HFile合并,但不会清理删除
Major Compaction:Store下的所有HFile合并,同时会清理和删除
6、Region Split拆分
每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分
由于负载均衡,可能会将当前table的region转移到其他region server上
7、读数据流程
访问zk,获取hbase:meta表位于哪个Region Server
根据读请求的namespace:table/rowkey获取region并缓存到meta cache
查询目标数据并合并
8、RowKey设计
(1)设计原则
1)rowkey长度原则
2)rowkey散列原则
3)rowkey唯一原则
(2)设计方式
1)生成随机数、hash、散列值
2)字符串反转
三、集成
1、集成Phoenix
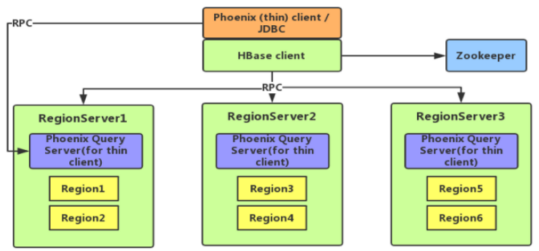
(1)Phoenix介绍
使用标准JDBC API代替HBase客户端API
特点:容易集成、操作简单、支持二级索引
(2)常见操作
安装:server和client拷贝
显示所有表:!tables
建表:表名等会自动转换为大写,加双引号可以指定小写
插入数据:upsert into student values
退出命令行:!quit
(3)视图&表映射
创建关联test表的视图:create view "test"(id varchar primary key,"info1"."name" varchar, "info2"."address" varchar);
删除视图:drop view "test";
(4)二级索引
二级索引配置文件
全局二级索引:创建新表,适用于多读少写的业务场景
本地二级索引:Local Index适用于写操作频繁
2、集成Hive
(1)HBase与Hive的对比



(2)Hive插入数据后影响Hbase
Hive中创建临时中间表,用于load文件中的数据
insert命令将中间表中的数据导入到Hive关联Hbase的那张表中
(3)借助Hive分析HBase表
Hive中创建外部表
使用Hive函数进行分析操作
四、优化
1、region预分区
提前规划region分区,提高性能
create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000']
方式:手工设定、生成16进制序列、按文件规则、使用java api
2、基础优化,配置hbase-site.xml
允许在HDFS的文件中追加内容
优化DataNode允许的最大文件打开数
优化延迟高的数据操作的等待时间
优化数据的写入效率
设置RPC监听数量
优化HStore文件大小
指定scan.next扫描HBase所获取的行数
flush、compact、split机制
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15841296.html

