
【消息队列面试】6-10:Rebalance机制、副本同步机制、架构设计、zk的作用、kafka的高性能
六、简述kafka的Rebalance【偏向实战,有难度】
1、背景
kafka日志:在消息量大、高并发时,经常会出现rebalance中
rebalance会影响kafka性能,会阻塞partition的读写操作
2、了解其机制,以避免rebalance的发生

3、Rebalance是什么
coordinator:leader节点所在的broker,作为一个协调者,监控cg中消费者的存活,判断consumer是否消费超时

七、kafka的副本同步机制
注意:LEO从哪落盘、HW从哪消费【更新】、最后已被消费、最先待消费、起始的offset
leader(处理读写请求)和多个follower(负责数据同步),主备模式
根据offset判断消费到了哪里
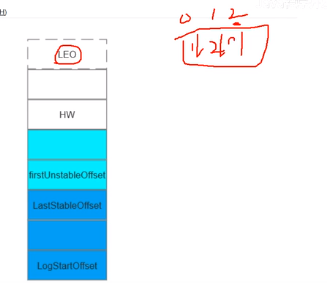
LEO:待写入数据的index
HW:HW前(下面)的数据对消费者可见,能够被消费者消费
第一条未提交的数据
最后一条已提交的数据

leader和follower都有HW,LEO会选择ISR中最小的HW和自身LEO进行写入,LEO落盘后,进行+1
当leader挂掉,变为follower后,follower的HW会覆盖当前节点的HW,从而会导致数据的丢失
消息丢失的解决,会在后面讲述
八、简述kafka的架构设计
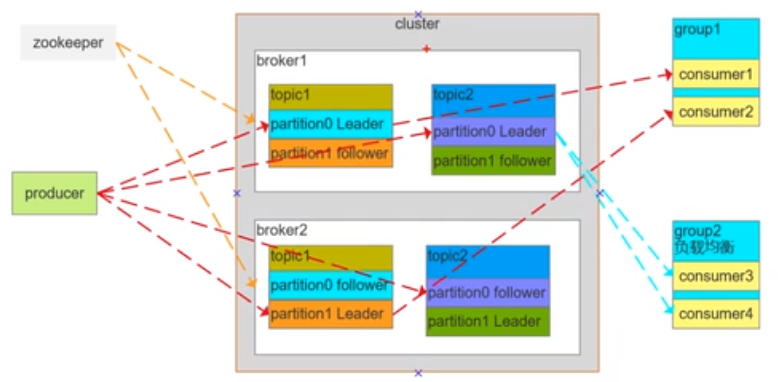
zk管理集群,存储一些元信息,作为znode中的一个节点
topic类似于queue,特点是可以分区
cg中不同的consumer消费同一topic的不同分区【cg是逻辑上的概念,实际上还是一个消费者】
如果指定同一消费者组的多个消费者同时消费某个分区,则多个消费者则会互斥,消息不会被重复发送
九、kafka中zk的作用(老版本)
1、后续zk的作用越来越小
2、哪些作用
无生产者信息,broker、topic、partition

十、kafka中高性能的原因
指其读写很快
顺序写、零拷贝
1、顺序写
kafka是一个日志系统,写到文件中
不是存入内存中,消息堆积能力强
硬盘是用磁头随机读写,而kafka是通过顺序写的方式(HBASE)
2、零拷贝
直接从磁盘读入网卡中
通过操作系统来实现
3、不依赖于java堆内存
使用操作系统的pageCache,进行读写

本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15795542.html

