

【实时数仓】Day04-DWS层业务:DWS设计、访客宽表、商品主题宽表、流合并、地区主题表、FlinkSQL、关键词主题表、分词
一、DWS层与DWM设计
1、思路
之前已经进行分流
但只需要一些指标进行实时计算,将这些指标以主题宽表的形式输出
2、需求
访客、商品、地区、关键词四层的需求(可视化大屏展示、多维分析)
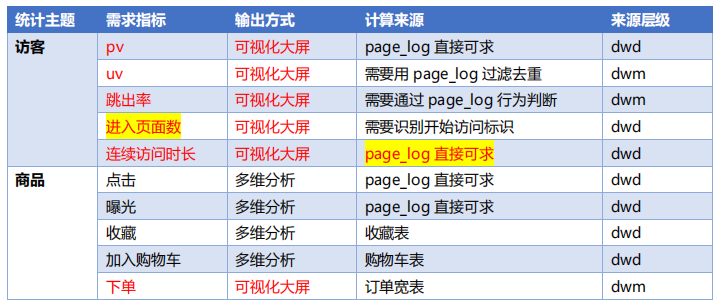

3、DWS层定位
轻度聚合、主题中管理
二、DWS层-访客主题宽表的计算

DWS表主要包含维度表和事实表
维度表主要包括渠道、地区、版本、新老用户等
事实表主要包括PV、UV、跳出次数、进入页面数(session_count)、连续访问时长等
1、需求分析
合并接收到的数据流,按时间窗口聚合,并将聚合结果写入数据库
2、实现
(1)读取kafka各个流的数据
page_log、dwm_uv、dwm_jump_user跳出用户
(2)合并读取到的数据流
使用union合并两个结构相同的数据流
需要提前调整数据结构封装主题宽表实体类(两个待合并的流也都要是这样的结构)
userJumpDStream.map实现转换
合并4条输入的流:
uniqueVisitStatsDstream.union(
pageViewStatsDstream,
sessionVisitDstream,
userJumpStatDstream
);
(3)根据维度进行聚合
设置时间标记及水位线
4个维度作为key,使用tuple4组合,进行分组,.keyBy(new KeySelector
reduce窗口内聚合,并补充时间字段
(4)写入OLAP数据库ClickHouse
专门解决大量数据统计分析的数据库,在保证了海量数据存储的能力,同时又兼顾了响应速度
先建表,使用 ReplacingMergeTree 引擎来保证幂等性
将日期变为数字作为分区类型
编写ClickhouseUtils工具类
创建 TransientSink 注解,标记不需要保存的字段
配置连接地址类,并增加写入OLAP的sink
查看控制台输出及表中数据 visitor_stats_2021
三、商品主题宽表

把多个事实表的明细数据汇总起来组合成宽表
1、需求及思路
获取数据流并转换为统一的数据对象格式
将统一数据结构合并为一个流
设定事件时间与水位线,分组、开窗、聚合
关联维度表补充数据
写入ClickHouse
2、功能实现
建商品统计实体类(各种业务数据的统计),并给必要字段添加@Builder.Default注解,各类添加@Builder注解(构造方法)
kafka中获取指定的流:FlinkKafkaConsumer<String> pageViewSource = MyKafkaUtil.getKafkaSource(pageViewSourceTopic,groupId);
对各种流数据进行结构转换,转换为构建的实体类
创建电商业务常量类 GmallConstant,类似维度表,用一个数字表示一个字符串
将统一的数据结构合并为一个流
设定事件时间与水位线
按商品id分组,10秒的窗口进行开窗window(TumblingEventTimeWindows.of(Time.seconds(10)))
补充商品维度、SKU维度、品类维度、品牌维度等信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SingleOutputStreamOperator<ProductStats> productStatsWithTmDstream = AsyncDataStream.unorderedWait(productStatsWithCategory3Dstream, new DimAsyncFunction<ProductStats>("DIM_BASE_TRADEMARK") { @Override public void join(ProductStats productStats, JSONObject jsonObject) throws Exception { productStats.setTm_name(jsonObject.getString("TM_NAME")); } @Override public String getKey(ProductStats productStats) { return String.valueOf(productStats.getTm_id()); } }, 60, TimeUnit.SECONDS);productStatsWithTmDstream.print("to save"); |
ClickHouse中创建商品主题宽表,添加写入ch的sink
1 2 3 4 | //TODO 7.写入到 ClickHouseproductStatsWithTmDstream.addSink( ClickHouseUtil.<ProductStats>getJdbcSink("insert into product_stats_2021 values(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)")); |
查看ClickHouse表中的数据
四、地区主题表(Flink SQL)

1、需求分析
定义 Table 流环境,把数据源定义为动态表
通过 SQL 查询出结果表并转换为数据流
将数据流写入目标数据库
2、功能实现
(1)添加FlinkSQL依赖
(2)定义 Table 流环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
(3)将数据源topic定义为动态表WITH (" + MyKafkaUtil.getKafkaDDL(orderWideTopic, groupId) + ")");
WATERMARK FOR rowtime AS rowtime 是把某个虚拟字段设定为 EVENT_TIME
(4)拼接 Kafka 相关属性到 DDL
(5)做聚合运算
Env.sqlQuery("select " +……并将其转换为数据流
DataStream<ProvinceStats> provinceStatsDataStream =
tableEnv.toAppendStream(provinceStateTable, ProvinceStats.class);
(6)定义地区统计宽表实体类并写入到ClickHouse(addSink)
五、关键词主题表(Flink SQL)
1、需求分析
维度聚合决定关键词的大小
来源:用户在搜索框中的搜索、以商品为主题的统计中获取
2、搜索关键词的实现
(1)使用IK分词器对字符串进行分词
(2)编写自定义函数,将分词器加入FlinkSQL中
Flink的自定义函数包括:Scalar Function(相当于 Spark 的 UDF)、Table Function(相当于 Spark 的 UDTF)、Aggregation Functions (相当于 Spark 的 UDAF)
由于分词是一对多的拆分,应该选择TableFunction
封装 KeywordUDTF 函数,自定义UDTF,继承TableFunction
(3)定义Table流环境
(4)注册自定义函数,将数据源定义为动态表
(5)过滤非空数据 tableEnv.sqlQuery
(6)利用 UDTF 进行拆分(SQL内部)LATERAL TABLE(ik_analyze(fullword)) as T(keyword)");
(7)聚合,根据各个关键词出现次数进行 ct
(8)转换为流并写入 ClickHouse
建表、封装实体类、添加sink
六、总结
1、DWS 层主要是基于 DWD 和 DWM 层的数据进行轻度聚合统计
2、利用 union 操作实现多流的合并
3、窗口聚合操作
4、对 clickhouse 数据库的写入操作
5、FlinkSQL 实现业务
6、分词器的使用
7、在 FlinkSQL 中自定义函数的使用
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15780738.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix