【实时数仓】Day02-DWD、DIM层数据准备:各层职能、行为日志DWD层、业务日志DWD层及分流(Phoenix和HBASE)
一、需求分析及实现思路
1、分层需求
建立数仓目的:增加数据计算的复用性
可以从半成品继续加工而成
从kafka的ODS层(数据一开始就读到了kafka)读用户行为数据和业务数据,并写回到kafka的DWD层
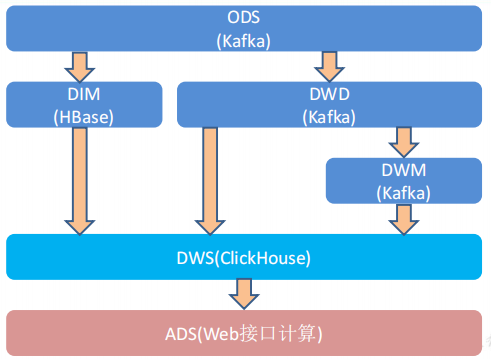
2、各层的职能
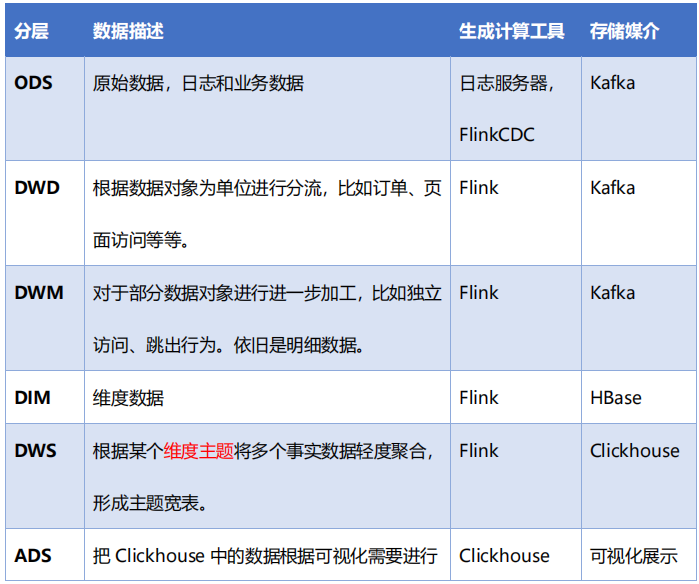
3、DWD层数据准备
环境搭建、计算用户行为日志DWD层、计算业务数据DWD层
二、环境搭建
1、在工程中新建模块gmall2021-realtime
common:公共常量
2、引入依赖、log4j配置文件记录日志
三、准备用户行为日志DWD层
日志数据作为ODS层,已经导入到kafka,并分为三类:页面日志、启动日志和曝光日志
将不同日志写入到不同主题中,作为日志的DWD层
其中,页面日志输出到主流、启动日志输出到启动侧输出流、曝光日志输出到曝光侧输出流
1、主要任务
(1)识别新老用户-状态确认
(2)利用侧输出流实现数据拆分
(3)不同流推送到kafka中不同的topic中
2、代码实现
(1)接收kafka数据并进行转换
获取FlinkDataSourceConsumer,并将获取到的topic数据存入json的object
(2)识别新老访客
记录每个 mid 的首次访问日期,每条进入该算子的访问记录
jsonObjDS.keyBy(data -> data.getJSONObject("common").getString("mid"));
首次访问时间不为空,则为老用户,否则为新用户
同时,无首次访问时间,也会将当前访问时间写入首次访问时间
(3)利用侧输出流实现数据拆分
日志数据分为三类:页面日志、启动日志和曝光日志
提取json中的start字段,看是否为空
提取display字段,看是否为空,判断是否是曝光数据
(4)不同流的数据推送到不同topic(分流)
使用工具类获取sink,就可以将ds中的数据传到指定的topic
pageDS.addSink(MyKafkaUtil.getKafkaSink("dwd_page_log"));
运行jar包查看输出效果
四、准备业务数据DWD层
可以使用FlinkCDC采集业务数据的变化(MySQL),将全部数据保存到ODS层的一个topic中
但上述数据既包括事实表,也包括维度表
该功能是从ODS层读取数据,将维度数据保存到HBase,将事实数据写到DWD层
1、主要任务
接收kafka数据,过滤空值
实现动态分流(维度表写入数据库,事实表写入流中,处理后形成宽表),并通过动态配置方案实时感知(MySQL库存储并进行周期性的同步)
对于配置数据初始化和维护管理,使用 FlinkCDC读取配置信息表,将配置流作为广播流与主流进行连接
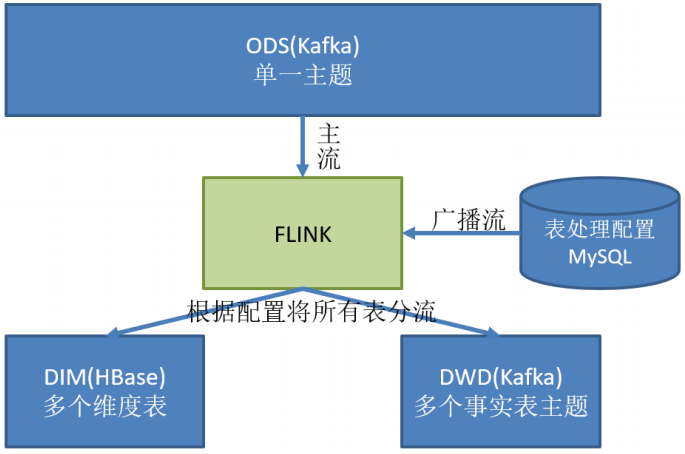
分好的流保存到对应的表和topic中
2、代码实现
(1)接收数据,过滤空值
获取json中的data字段,接口为空则返回true被过滤掉
(2)根据配置,动态分流【Phoenix中建表】
建立MySQL表table_process和对应的java Bean
来源表、输出类型、输出表/topic、主键字段、输出字段
读取配置表形成广播流
tableProcessDS.broadcast(mapStateDescriptor);
主流和广播流拼接
filterDS.connect(broadcastStream);
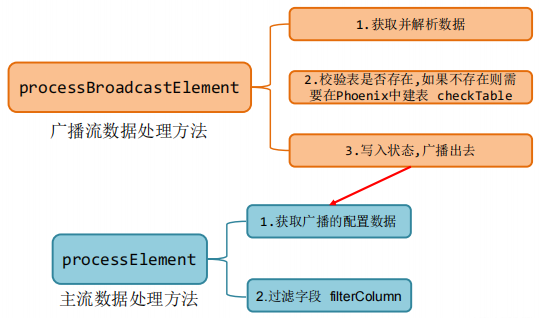
自定义TableProcessFunction-判断建表、发送到哪里(tableProcess.getSinkType()))
过滤多余字段,主程序调用上述函数进行分流
(3)分流sink并将维度表保存到HBase(Phoenix)
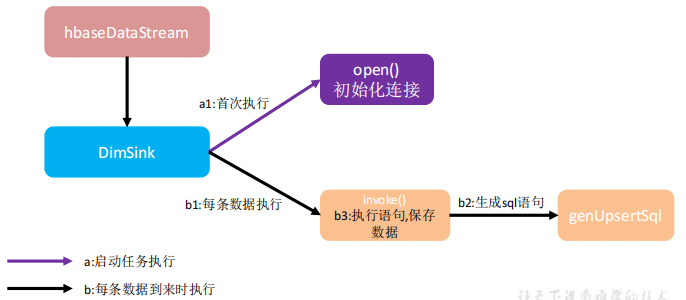
用单独的 schema,定义HBASE的配置文件
开启 hbase 的 namespace 和 phoenix 的 schema 的映射
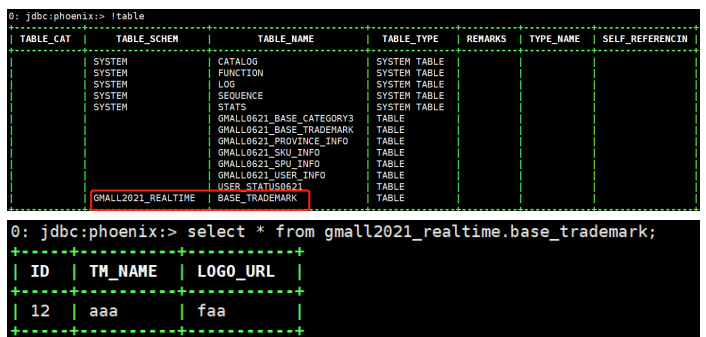
phoenix中建表,获取sink并使用Phoenix的方法插入到表中
插入数据并进行测试
(4)分流sink之保存业务数据到kafka topic
获取kafka的topic数据
五、总结
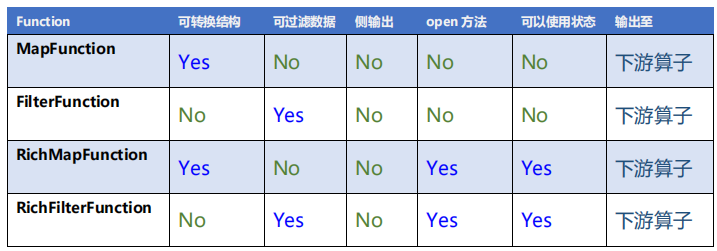
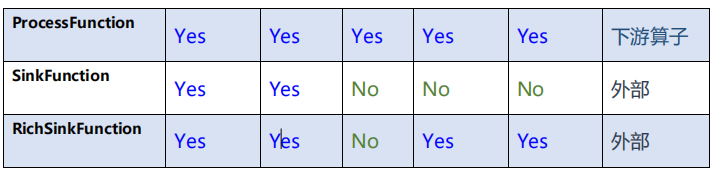
数据分流和状态识别的算子比较
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15768802.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号