

【大数据面试】【项目开发经验】Hadoop、Flume、Kafka、Hive、MySQL、Sqoop、Azkaban、Spark
主要内容:框架层面的调优、业务经验
一、Hadoop
1、Hadoop基准测试(HDFS的读写性能、MapReduce的计算能力测试)
(1)测试内容:文件上传下载的时间
(2)服务器有几个硬盘插槽
2/4块
问题:2块4T和一块8T的哪个贵
2块4T的贵,可靠性更高一些
(3)加了磁盘,默认情况下不会直接能够使用
需要负载均衡,保证每个目录数据均衡
开启数据均衡命令:
bin/start-balancer.sh –threshold 10:集群中各个节点的磁盘空间利用率相差不超过10%
均衡了差不多,就需要杀掉此进程bin/stop-balancer.sh
2、HDFS参数调优
线程池:调整NN和DN之间的通信:处理与datanode的心跳(报告自身的健康状况和文件恢复请求)和元数据请求
dfs.namenode.handler.count=20 * log2(Cluster Size)
3、yarn的参数调优
(1)服务器节点上YARN可使用的物理内存总量,默认是8192(MB)
(2)单个任务可申请的最多物理内存量,默认是8192(MB)
NN、DN、shuffle的默认大小为1G
4、HDFS和硬盘使用控制在70%以下
5、Hadoop宕机
MR造成系统宕机:调整上述yarn的参数
写入文件过量造成NameNode宕机
6、集群资源分配参数
集群有30台机器,跑mr任务的时候发现5个map任务全都分配到了同一台机器上
解决方案:yarn.scheduler.fair.assignmultiple 这个参数 默认是开的,需要关掉
https://blog.csdn.net/leone911/article/details/51605172
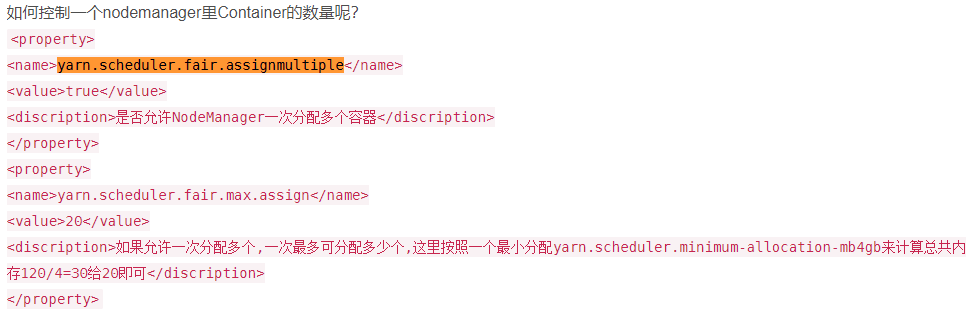
资源充沛,可以调大,资源部充沛,调小一点
7、HDFS 小文件
combiner
consequenceFile……
8、数据倾斜
MR:打散、聚合
二、Flume
1、调整内存
默认是2000,接近于2000,生产环境下调到4-6G
flume-env.sh修改
2、FileChannel优化
在不同的挂载硬盘上配置多目录,增大Flume吞吐量
3、Sink:HDFS Sink小文件处理
hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount
4、Ganglia监控
发现flume的问题
发现put尝试提交的次数大于最终成功的次数
或take拉取。。。
三、kafka
1、压力测试/测试吞吐量
测试生产速度(最快600m/s 实际20m/s)和消费速度(取决下级消费者【flume1000-3000event/s和spark Streaming读取的速度】)
2、默认内存调整
默认1G,最大可以调到6G(不能超过6G)
3、Kafka数量
2 * 峰值生产速度(m/s)* 副本数 / 100 + 1 = ?
4、数据量计算
每天数据总量100g(1亿条) 10000万/24/60/60 = 1150条/s
平均每秒钟:1150条
低谷每秒:100条
高峰每秒钟:1150 * 200 = 220000 条
每条日志大小: 1K左右
每秒多少数据量:1m/s 峰值20MB
5、挂了、丢了、重复了、积压
6、优化
压缩---消费者能够解压缩☆
数据保存时间,默认7天,调整为3天
计算线程=cpu+1
IO线程=cpu*2
零拷贝技术、顺序读写、分布式集群、分区(提高并发度)--为什么吞吐量大、效率高、是怎么保证的?
四、Hive
1、自定义UDF和UDTF解析和调试复杂字段
2、Hive优化、数据倾斜(map join、group by)
什么时候发生:join类型不同、空值【随机打散、负载均衡】
3、现场手写HQL☆ 30个指标一定会
五、MySQL
1、高可用
Keepalived或者用mycat配置,从而实现元数据备份
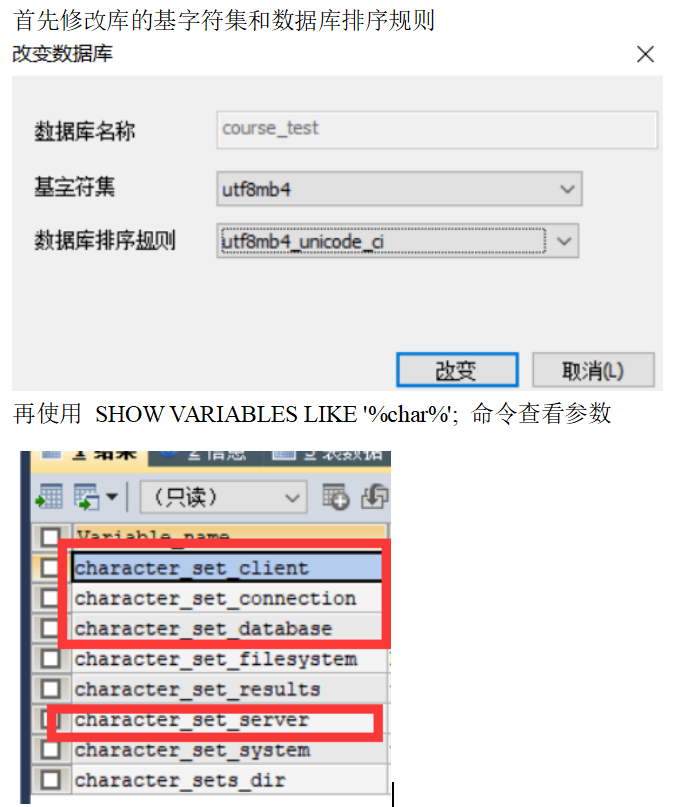
2、utf8超过字节数
UTF-8只能存储3个字节
当数据中存在表情号、特色符号时会占用超过3个字节数的字节,那么会出现错误 Incorrect string value: '\xF0\x9F\x91\x91\xE5\xB0...'
解决办法:将utf8修改为utf8mb4
六、sqoop
1、数据导出Parquet
Ads层数据用Sqoop往MySql中导入数据的时候,如果用了orc(Parquet)不能导入,需转化成text格式
(1)创建临时表,把Parquet中表数据导入到临时表,把临时表导出到目标表用于可视化
(2)Sqoop里面有参数,可以直接把Parquet转换为text
(3)ads层建表的时候就不要建Parquet表,直接创建textFile
2、空值问题
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string
3、一致性问题
因为在导出数据的过程中map任务可能会失败,可以使用—staging-table –clear-staging
任务执行成功首先在tmp临时表中,然后将tmp表中的数据复制到目标表中
4、导出时一次执行的时间
凌晨30分开始执行,Sqoop任务40-50分钟。取决于数据量
flume不能提前导
七、Azkaban
1、每天集群运行多少指标?
100-200个离线指标
100:没有活动时
200:搞活动时、周末、新产品上线
2、任务挂掉怎么办
通常凌晨30分时执行azkaban,会发邮件(普通级别)、打电话(重要任务)
打开电脑,通过VPN远程连接公司电脑,检查是那台任务挂了,并重新执行该任务
yarn(任务队列分等级):比如新产品、新市场、活动618
八、Spark【必问优化】
1、Spark OOM、数据倾斜解决

本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15703993.html

