
【大数据面试】【数仓项目】其他知识点:行为数仓、业务数仓、拉链表、即席查询
一、用户行为数仓.
1、数仓分层架构图

2、埋点行为数据基本格式(基本字段)
"ap":"xxxxx",//项目数据来源 app pc "cm": { //公共字段 "mid": "", // (String) 设备唯一标识 "uid": "", // (String) 用户标识 "vc": "1", // (String) versionCode,程序版本号 "vn": "1.0", // (String) versionName,程序版本名 "l": "zh", // (String) 系统语言 "sr": "", // (String) 渠道号,应用从哪个渠道来的。 "os": "7.1.1", // (String) Android系统版本 "ar": "CN", // (String) 区域 "md": "BBB100-1", // (String) 手机型号 "ba": "blackberry", // (String) 手机品牌 "sv": "V2.2.1", // (String) sdkVersion "g": "", // (String) gmail "hw": "1620x1080", // (String) heightXwidth,屏幕宽高 "t": "1506047606608", // (String) 客户端日志产生时的时间 "nw": "WIFI", // (String) 网络模式 "ln": 0, // (double) lng经度 "la": 0 // (double) lat 纬度 }, "et": [ //事件 { "ett": "1506047605364", //客户端事件产生时间 "en": "display", //事件名称 启动和事件日志是根据事件名称的不同 "kv": { //事件结果,以key-value形式自行定义 "goodsid": "236", "action": "1", "extend1": "1", "place": "2", "category": "75" } } ] }
3、项目经验总结
MySQL的高可用
存储元数据,搭建时要进行高可用HA
4、日期函数
1)date_add、date_sub函数(加减日期)
2)next_day函数(周指标相关)
3)date_format函数(根据格式整理日期)
4)last_day函数(求当月最后一天日期)
5)collect_set函数
6)get_json_object解析json函数
5、Union与Union all区别
1)union会将联合的结果集去重,效率较union all差
2)union all不会对结果集去重,所以效率高
6、Shell中单引号和双引号区别
#!/bin/bash do_date=$1 echo '$do_date' #不取值 echo "$do_date" #取值 echo "'$do_date'" #谁在最外面,谁起作用 echo '"$do_date"' #不起作用 echo `date` #执行命令
7、Tez引擎--Mr/tez/spark区别
Mr引擎:多job串联,基于磁盘,落盘的地方比较多。虽然慢,但一定能跑出结果。一般处理,周、月、年指标。
Spark引擎:虽然在Shuffle过程中也落盘,但是并不是所有算子都需要Shuffle,尤其是多算子过程,中间过程不落盘 DAG有向无环图。 兼顾了可靠性和效率。一般处理天指标。
Tez引擎:完全基于内存。 注意:如果数据量特别大,慎重使用。容易OOM。一般用于快速出结果,数据量比较小的场景。
8、需求逻辑
用户活跃
用户新增:活跃用户表 left join 用户新增表
1天留存
最近七天内连续三天活跃
二、业务数仓
1、电商常识
SKU:一台银色、128G内存的、支持联通网络的iPhoneX-库存量具体产品
SPU:iPhoneX--produce
Tm_id:品牌Id苹果,包括IPHONE,耳机,mac等
2、电商业务流程
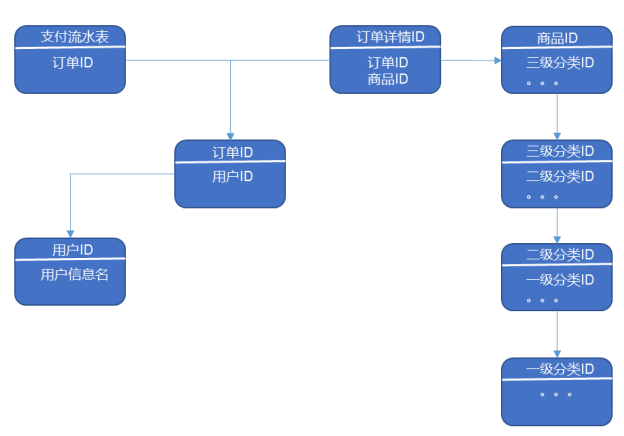
3、业务表关键字段
4、MySql中表的分类
实体表,维度表,事务型快照事实表,周期型快照事实表、累积型事实表
5、同步策略
实体表,维度表统称维度表,每日全量或者每月(更长时间)全量
事务型事实表:每日增量
周期性事实表:拉链表
【新增、新增和变化、全量】
新增:sqoop --query "select * from table where createtime = now" and 命令
新增和变化:sqoop --query "select * from table where createtime = now or operatetime = now" and 命令
全量:sqoop --query "select * from table where 1= 1" and 命令
6、3范式(数仓建模必问)
7、数据模型
星型模型(一级维度表),雪花(多级维度),星座模型(星型模型+多个事实表)
三、拉链表
1、是否做过拉链表
用户做过
2、场景:一张表,一年修改一次
缓慢变化维的场景,用户表很典型
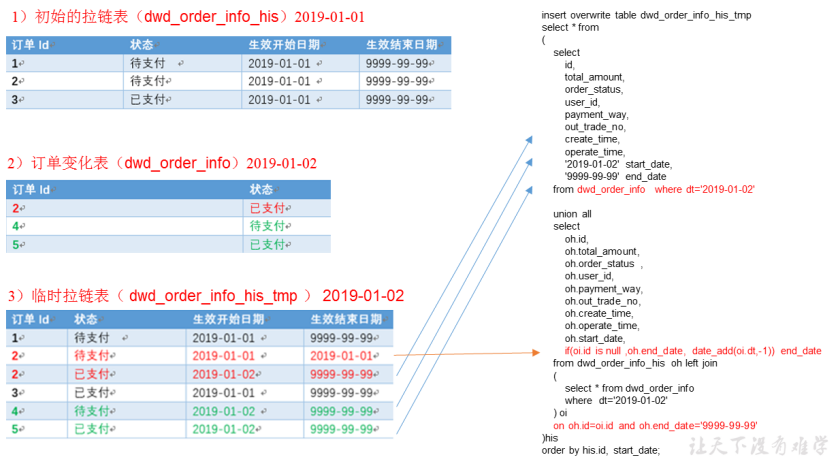
3、步骤-left join后得到临时表,拼接后修改结束日期
四、即席查询
1、查询工具
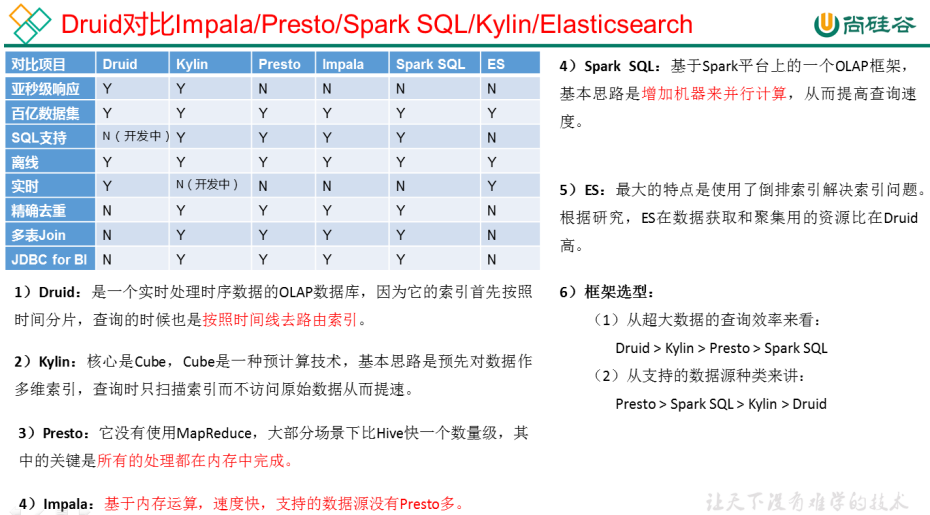
架构师的技术选型
Druid:支持实时(类似flink)和批处理(类似spark),处理速度快,但只支持单表,快的原因:行数据按照时间进行预聚合,列数据采用列式存储
新版本:clickhouse,是druid的竞品,支持多表
Kylin:预计算,提前算好结果,写入HBase,后续相当于查询HBASE。速度也快
presto:基于内存,速度快,但容易出现OOM;此外,支持的数据源最多(kafka、端口号等)
Impala:同上,支持的数据源少,查询性能比presto更高
生产环境:如果是CDH框架,选择默认集成的impala,如果是Apache,选择presto
spark:跑每天的定时任务,基于内存和磁盘
es:用于存储和查询,查询速度比较快,不擅长于join操作,一般用于没有大数据集群场景,如果有集群,一般用于存储用户画像标签(晚上、喝酒)
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15700116.html

