
【大数据面试】【项目】数仓架构:离线、实时、数仓输入输出、选型、版本、服务器、集群规模、数据保存、组件安装分配
一、质疑分层不合理
云上大数据数仓解决方案:https://www.aliyun.com/solution/datavexpo/datawarehouse
1、离线数仓--基于hive
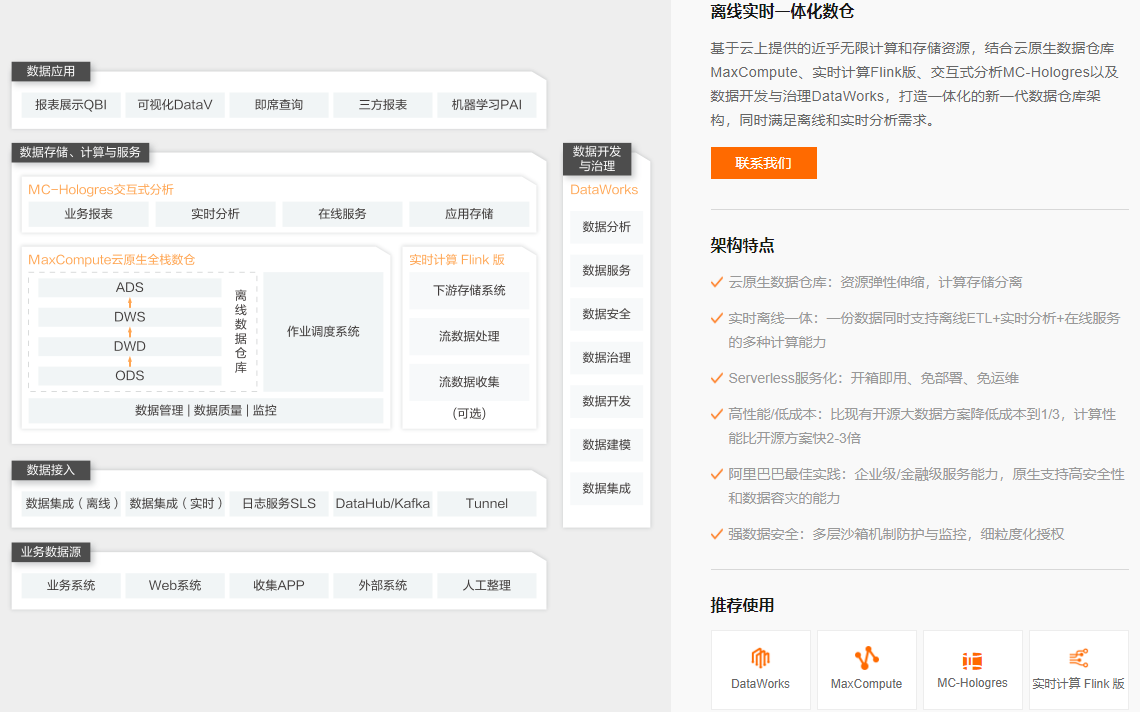
2、实时数仓--基于kafka中间件
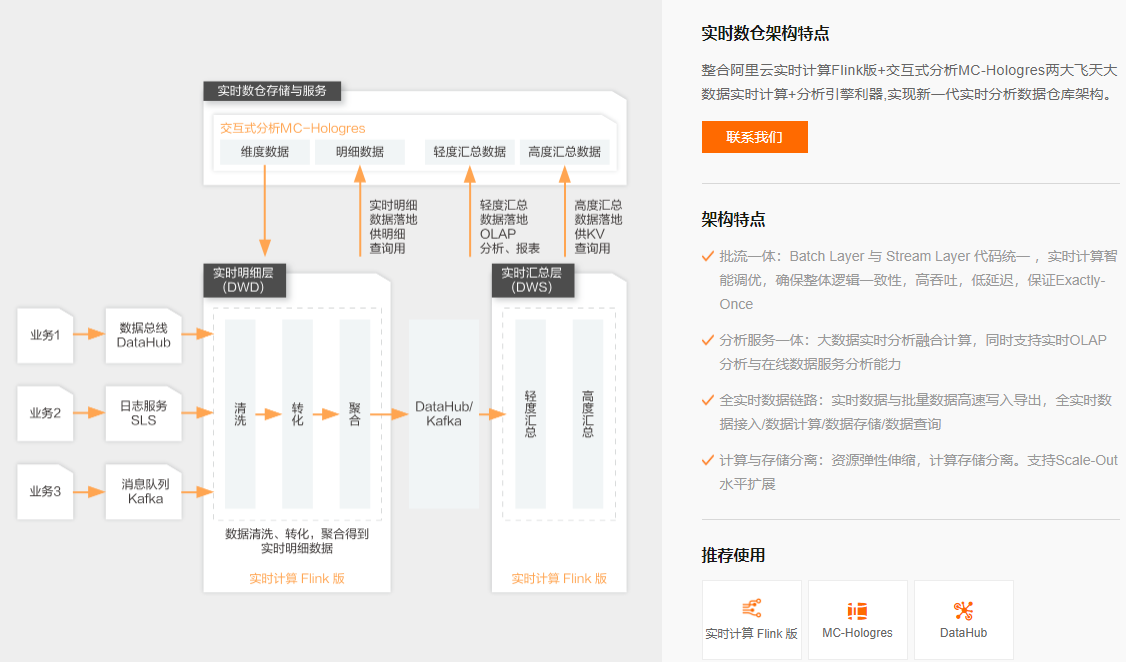
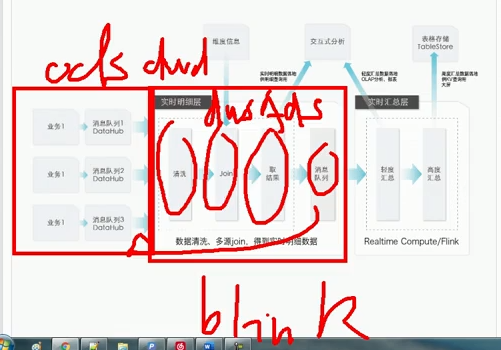
每一步都会缓存至datahub
二、数仓概念
1、数仓的数据源和输出系统分别是什么
数据源:用户行为数据、业务数据、爬虫(灰色地带,需要经过授权)
数据输出:报表、用户画像、推荐等
2、版本选型
Apache:开源、免费、需要自己解决兼容性问题--大厂和比较有实力的公司
例如,Hadoop是3.1.3,spark是2.4.5,hive是3.1.0
CDH:不开源、不能编译源码,而且收费(7.0之后),常用5.12.1 5.16 6.2.0 6.3.0
市场占有率最高,知道收费,短时间内难以更换
Java程序员在用,
HDP:可以重新编译源码,但是已经被CDH收购,并推出了CDP7.0
CDP7.0:60000一个节点
建议公司备用一套Apache
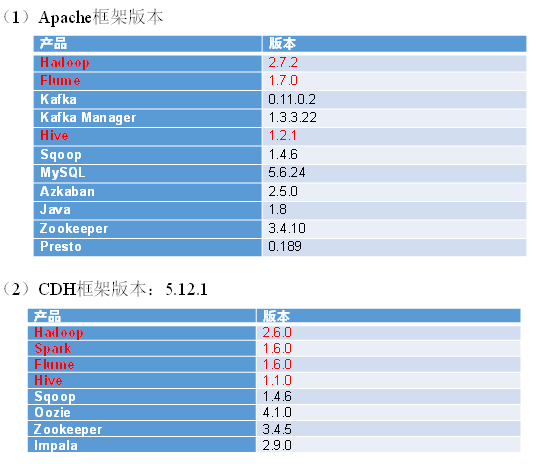
3、框架版本号
4、服务器的选型:物理机or云主机
物理机:刀片机服务器,1U 2U是指厚度,买1U,双电源,32*4 内存,4*2T硬盘,一共4w,能用5年
云主机:每年5w
运维成本:电费、运维人员工资

物理机:中型上市公司、传统行业、资金充足的公司、运维技术实力比较强
5、集群规模

6、三年的数据是否都会保存?
生产环境中,有的公司保留半年、一年、三年等
非保留的数据,不是删除,而是存储完之后,永久备份
怎么备份:
某一分区数据超过年限,使用get下载到磁盘,数据就可以永久的保存到磁盘
保存时,一般会采用压缩
公司稍微有点钱,保留数据,把数据也会备份一份
7、用户行为数据中,哪张表的数据最多,是多少
商品列表、详情、点击、广告、收藏、通知、故障、启动、后台活跃、评论、点赞,11张表
100g的数据,点击表的数据量多--点击
数据量大约为 ==》 先算平均值,大约为10G ==》 大约是平均值的2-3 倍
8、业务数据中,哪张表的数据最多,是多少
订单、用户、支付、订单详情、商品表、三级分类、二级分类、一级分类,8张表
实际30张表左右
1G/30张≈34M
订单详情/订单大约为100M
【平均值的2-3倍】
9、哪台服务器需要安装哪些组件

10、总体设计方案
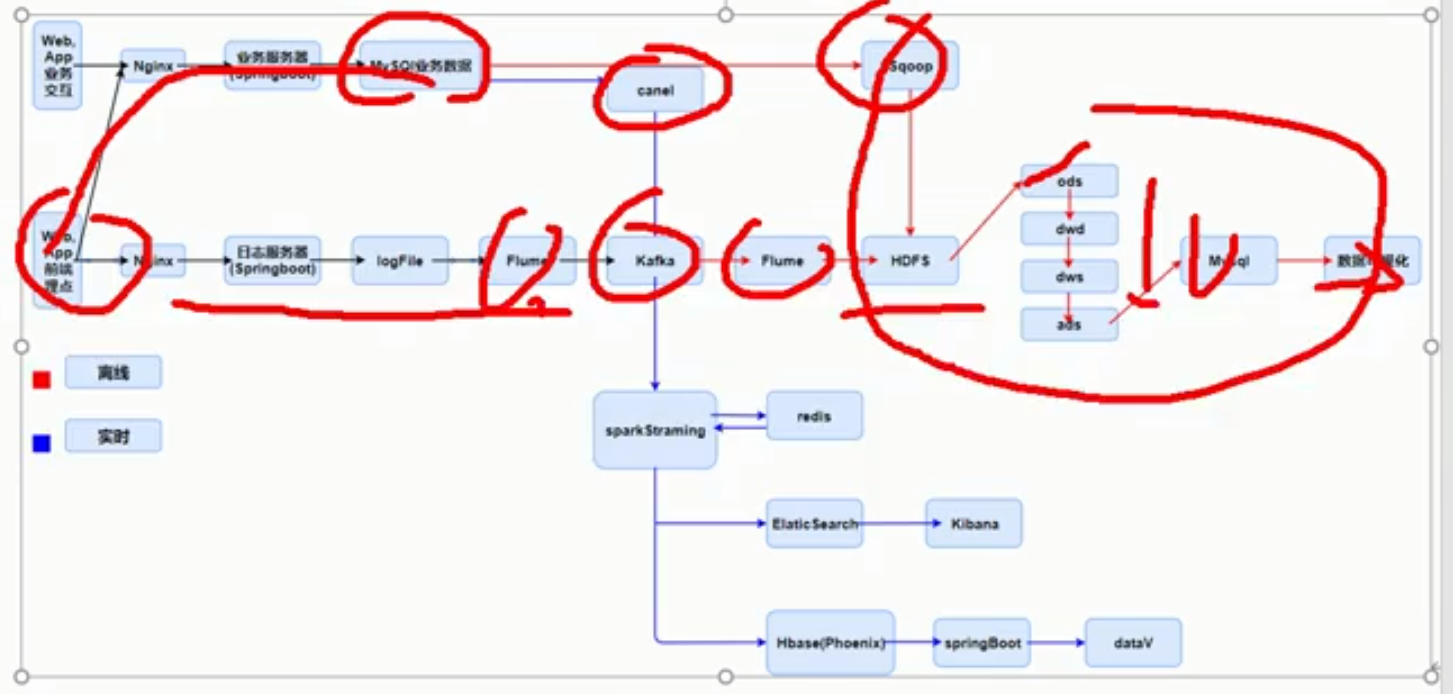




测试集群规划
10、人员配置参考
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15695616.html

