
【大数据面试】【框架】Hive:架构、计算引擎、比较、内外部表、by、函数、优化、数据倾斜、动静态分区
一、组成
1、架构
源数据原本是存在dubby数据库,存在MySQL可以支持多个客户端
客户端、数据存储(HDFS)、MR计算引擎
2、计算引擎的选择
MR引擎:基于磁盘,计算时间长,但一定能算出结果【一般用于计算周指标、月指标、年指标,一个任务3-5天】
tez引擎:基于内存,计算时间快,如果宕机,数据直接丢掉【一般用于临时调试,但容易出现OOM】
Spark引擎:既基于内存,也会落盘,居中【一般用于每天的定时任务】
二、与MySQL/Hbase的区别
hive MySQL Hbase
1、数据量大小 大 小
2、速度 数据量大/快 数据量小/慢
3、擅长 查询 增删改查 擅长插入不擅长查询
三、内部表和外部表的区别【出现频率最高&最简单】
1、最重要-元数据、原始数据
删除数据的时候,内部表会将元数据和原始数据全部删除,外部表只会删除元数据,原始数据不会被删除
2、在公司生产环境下,什么情况创建内部表,什么情况创建外部表
先导入hdfs,再将hdfs与hive表进行关联
绝大多数场景都是创建外部表【多个人共同使用】
只有在自己使用的临时表时,才会创建内部表
四、四个by
1、用法
order by:全局排序,针对自己用的临时表
sort by:排序
distribute by:分区
c:排序和分区字段相同时使用
5、在生产环境下
是否使用order by
不用,全局排序,数据量比较大
京东40-50T内存,都会OOM
s+d用的比较多:主要是在分区内部进行排序,效果最佳
c用的也会比较少
五、函数
1、系统函数
时间相关(日、月、周的处理)
日:date_add date_sub
周:next_day
月:date_format last_day
解析json☆:get_json_object
2、自定义函数
(1)组成
自定义UDF:项目中使用UDF解析公共字段
自定义UDTF:项目中使用UDTF解析具体的事件字段
自定义UDAF(spark)
(2)如果项目中不使用UDAF和UDTF能否对数据解析?
可以用系统函数,get_json_object【不定义】
(3)用系统函数能解决,为什么还要自定义
如果使用系统函数,解析失败只会抛出异常,不会抛出因为什么原因没解析出来
而自定义的方式,可以将每一个过程日志打印出来【更灵活,方便调试】
(4)自定义UDF步骤
定义一个类,继承UDF,重写内部的evaluate方法(实现其业务逻辑)
(5)自定义UDTF的步骤
定义一个类,继承GenericUDTF,重写内部的初始化、process、stop
(5)使用步骤
打包 =》上传到集群 =》在hive里面创建永久函数
3、窗口函数☆
rank
over
需要手写topn☆(使用开窗的方式)
六、Hive的优化
1、mapjoin
默认是打开的,不要关闭
2、行列过滤
出题形式,join where==》优化后先where后join
能提前过滤就提前过滤,再进行join操作
3、创建分区表
分桶【少】:对数据不太清楚时(不同key数据量不同,将key打散,对数据分组采样,)【分区表的优化手段】
分区表更常见
4、小文件处理
combinInputformat减少切片,进而减少map task,从而减少内存分配
开启JVM重用
采用merge的方式:
针对maponly的任务,默认打开-执行完任务后,会将小于16M的文件合并到256M(hive的块大小)
针对MapReduce任务,需要打开merge功能
5、合理设置map个数和reduce个数
map个数怎么设置:切片的大小-规则为max(0, min(块大小, Long的最大值))
128M数据对应1G内存
6、压缩
好处:减少磁盘所占的空间,减少网络传输
坏处:增加了解压缩计算
7、采用列式存储ORC/parquet
好处:提高查询效率,提高压缩比例 100G==> 10G ==》5-6G
如:
id name age
1 zhangsan 15
2 lisi 18
行存:1 zhangsan 15,2 lisi 18
select age from user,属于随机存储
列式存储:1 2 zhangsan lisi 15 18
select age from user,直接取 15 18,属于顺序读写
8、在reduce端开启combiner
要求不能影响最终的业务逻辑
七、数据倾斜
1、数据倾斜的表现
hql发生在reduce聚合时
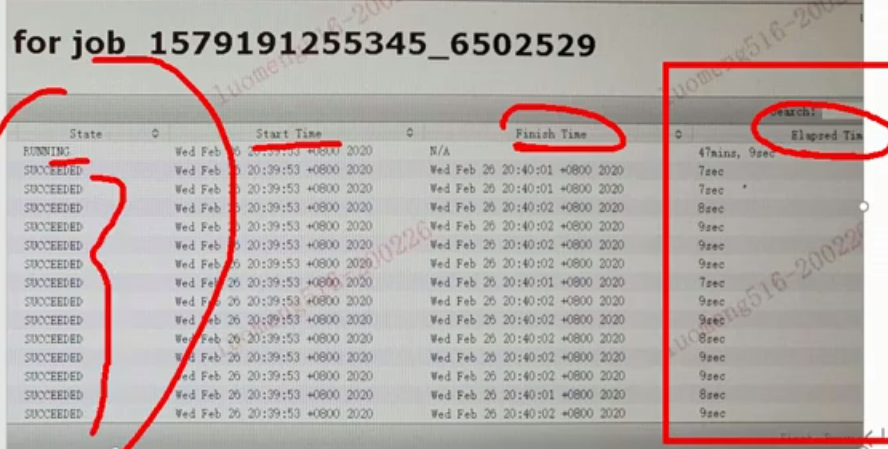
2、什么情况下会产生数据倾斜
不同数据类型关联产生数据倾斜(用户表中的id为int类型,log表中定义的用户id是string类型,两张表进行join操作时,数据不匹配,所有数据进入同一个reduce,其他都为空)
解决方式:

3、如何解决数据倾斜
(1)group by由于distinct group by
(2)在map端对数据进行join
(3)开启数据倾斜时负载均衡

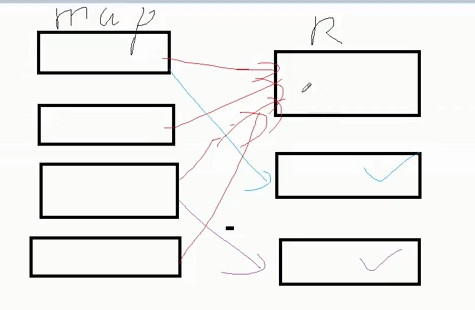
数据倾斜时,对reduce任务拆分,加随机数把数据打散,拆成多个reduce
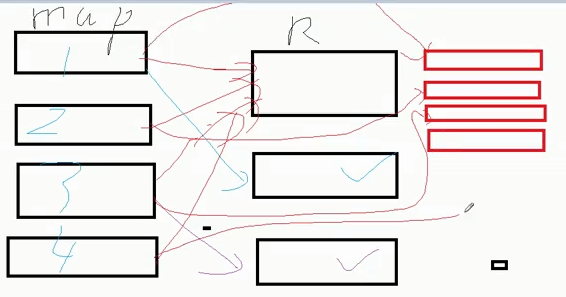
将多个执行的reduce重新聚合,按照groupby,将同一个key的聚合为一个reduce
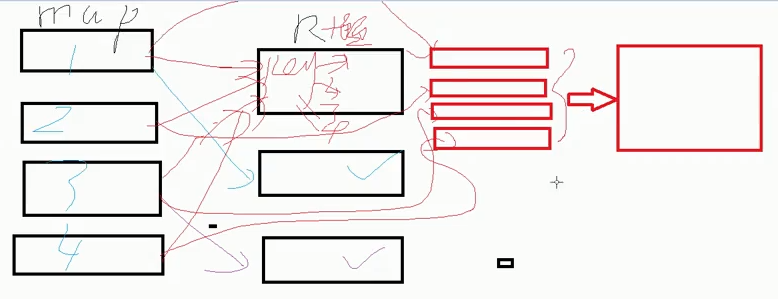
(4)控制数据分布,避免数据倾斜【类型不一致/空值】
默认值为空数据的值很大,可以在后面加随机数
将空值的分配一个特殊的值

八、hql练习
1、用的是动态分区吗,动态分区的底层原理
静态分区
insert overwrite table1 patition(dt=2021-12-14)
select age, name from user
动态分区
insert overwrite table1 patition(dt)
select age, name,dt from user
或
select age, name,'2021-12-14' from user
2、各自特点
静态是编译期时用户传递过来的
动态分区是执行SQL语句的时候才会决定(动态添加的值)
3、hive的字段分隔符
默认分隔符是\001,即^A
咱们使用的是\t
能否采用\abc作为分隔符
能,按照规范,前面不要出现这些字段,
如果出现,会产生什么后果
抛异常、类型不匹配(转换异常)
出现了,要对其进行转义,转义为普通的字符
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15690357.html

