

【离线数仓CDH版本】即席查询工具(Presto、Druid、Kylin)、CDH数仓、Impala查询
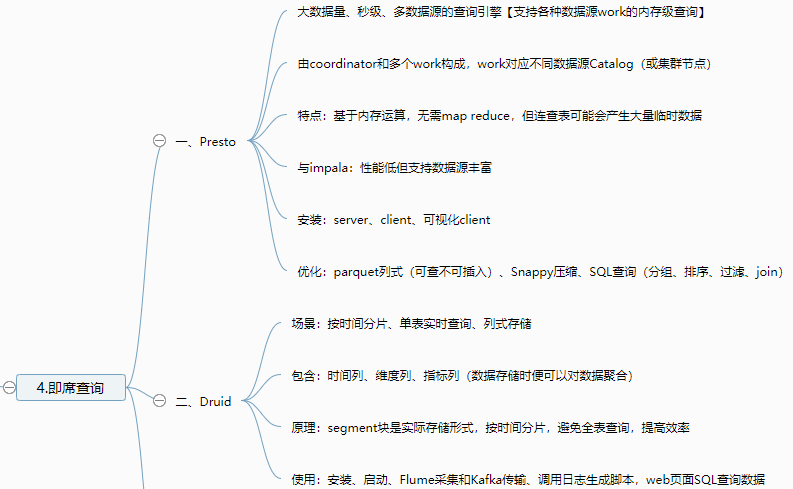

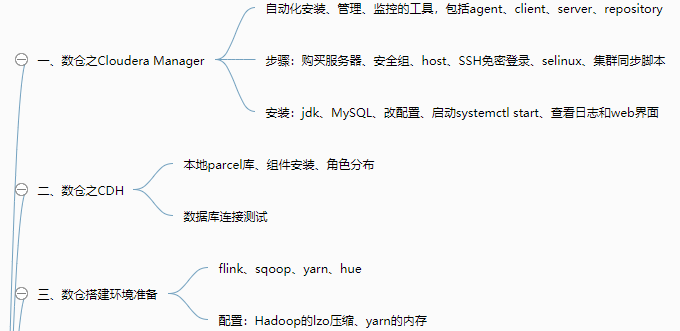
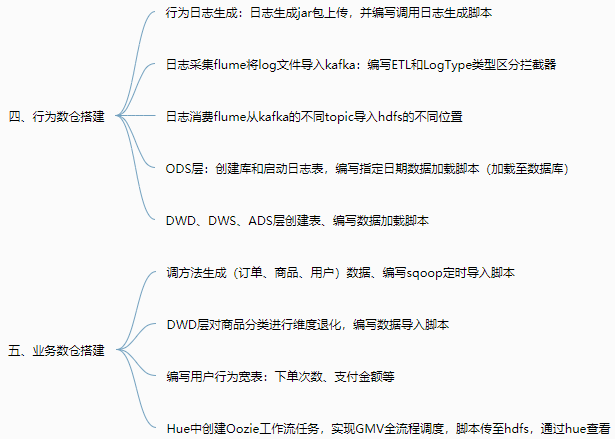
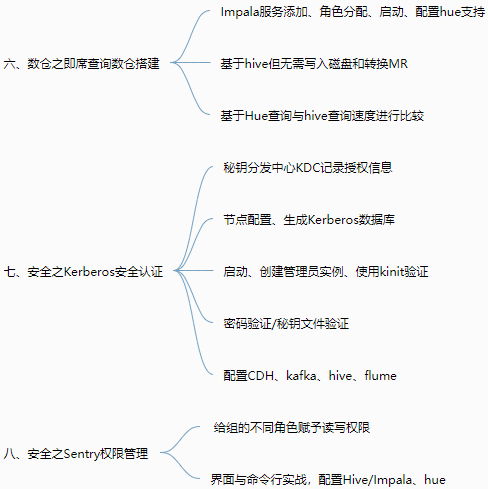
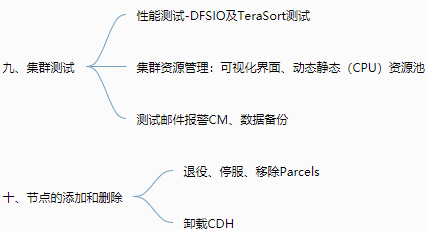
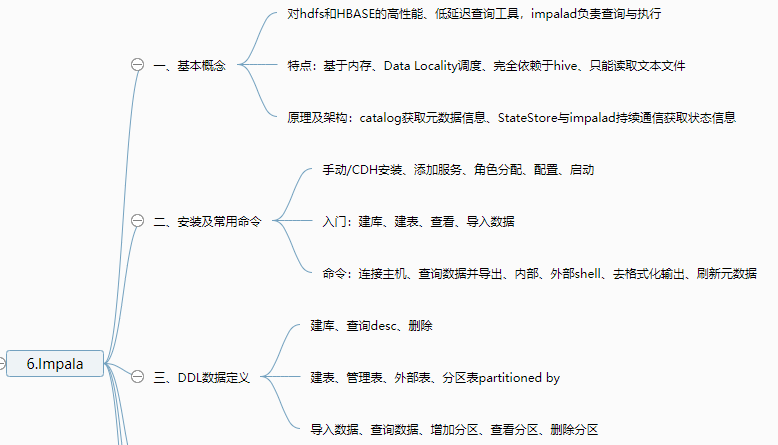

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 | 1.即席查询 一、Presto 大数据量、秒级、多数据源的查询引擎【支持各种数据源work的内存级查询】 由coordinator和多个work构成,work对应不同数据源Catalog 特点:基于内存运算,无需map reduce,但连查表可能会产生大量临时数据 安装:server、client、可视化client 优化:列式、Snappy压缩、SQL优化 二、Druid 适用于:按照时间作为索引分片、单表的实时查询与存储系统【按时间和不同维度对各种指标聚合,segment存】 包含:时间列、维度列、指标列(数据存储时便可以对数据聚合后的结果) 原理:segment块是实际存储形式,按时间分片,避免全表查询,提高效率 使用:安装、启动、Flume采集和Kafka传输、调用日志生成脚本,web页面SQL查询数据 三、Kylin 分析查询巨大的hive表数据,元数据存储在HBASE中【按01构建cube,可视化查询与图表展示】 web界面添加数据源、选择维度表、度量字段构建cube,选择构建的时间区间(编写每日构建的脚本) cube构建原理:cubeid+纬度01值构成HBASE的K,通过逐行/层快速构建 cube构建优化:衍生维度中间表实现主向非主的映射、使用聚合组、RowKey的优化 BI可视化工具集成:测试Zepplin访问kylin输入SQL语句查看各种图表,JDBC、ODBC、RestAPI2.CDH数仓 一、数仓之Cloudera Manager 自动化安装、管理、监控的工具,包括agent、client、server、repository 步骤:购买服务器、安全组、host、SSH免密登录、selinux、集群同步脚本 安装:jdk、MySQL、改配置、启动systemctl start、查看日志和web界面 二、数仓之CDH 本地parcel库、组件安装、角色分布 数据库连接测试 三、数仓搭建环境准备 flink、sqoop、yarn、hue 配置:Hadoop的lzo压缩、yarn的内存 四、行为数仓搭建 行为日志生成:日志生成jar包上传,并编写调用日志生成脚本 日志采集flume从生成的日志文件中导入kafka:flume编写ETL和LogType类型区分拦截器 日志消费flume从kafka的不同topic导入hdfs的不同位置 ODS层:创建库和启动日志表,编写指定日期数据加载脚本(加载至数据库) DWD、DWS、ADS层创建表、编写数据加载脚本 五、业务数仓搭建 调方法生成(订单、商品、用户)数据、编写sqoop定时导入脚本 DWD层对商品分类进行维度退化,编写数据导入脚本 编写用户行为宽表:下单次数、支付金额等 Hue中创建Oozie任务实现GMV全流程调度,脚本传至hdfs,通过hue查看 六、数仓之即席查询数仓搭建 Impala服务添加、角色分配、启动 基于hive但无需写入磁盘和转换MR 基于Hue查询与hive查询速度进行比较 七、安全之Kerberos安全认证 秘钥分发中心KDC记录授权信息 节点配置、生成Kerberos数据库 启动、创建管理员实例、使用kinit验证 密码验证/秘钥文件验证 配置CDH、kafka、hive、flume 八、安全之Sentry权限管理 给组的不同角色赋予读写权限 界面与命令行实战,配置Hive/Impala、hue 九、集群测试 性能测试-DFSIO及TeraSort测试 集群资源管理:可视化界面、动态静态(CPU)资源池 十、节点的添加和删除 退役、停服、移除Parcels3.Impala 一、基本概念 对hdfs和HBASE的高性能、低延迟查询工具,impalad负责查询与执行 特点:基于内存、Data Locality调度、完全依赖于hive、只能读取文本文件 原理及架构:catalog获取元数据信息、StateStore与impalad持续通信获取状态信息 二、安装及常用命令 手动/CDH安装、添加服务、角色分配、配置、启动 入门:建库、建表、查看、导入数据 命令:连接主机、查询数据并导出、内部、外部shell、去格式化输出、刷新元数据 三、DDL数据定义 建库、查询desc、删除 建表、管理表、外部表、分区表partitioned by 导入数据、查询数据、增加分区、查看分区、删除分区 四、DML数据操作 数据导入与导出并进行查询(txt文本文件) 五、函数 创建自定义函数extends UDF并打包,调用创建命令 使用select和查看show 六、存储与压缩 文件格式:Parquet、SequenceFile(只支持查询,不支持插入) 压缩编码方式:Snappy, GZIP |
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15659160.html
分类:
项目实战


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix