

【离线数仓】Day02-用户行为数据仓库:分层介绍、环境搭建(hive、tez)、LZO压缩、建表查询导入加索引、编写脚本

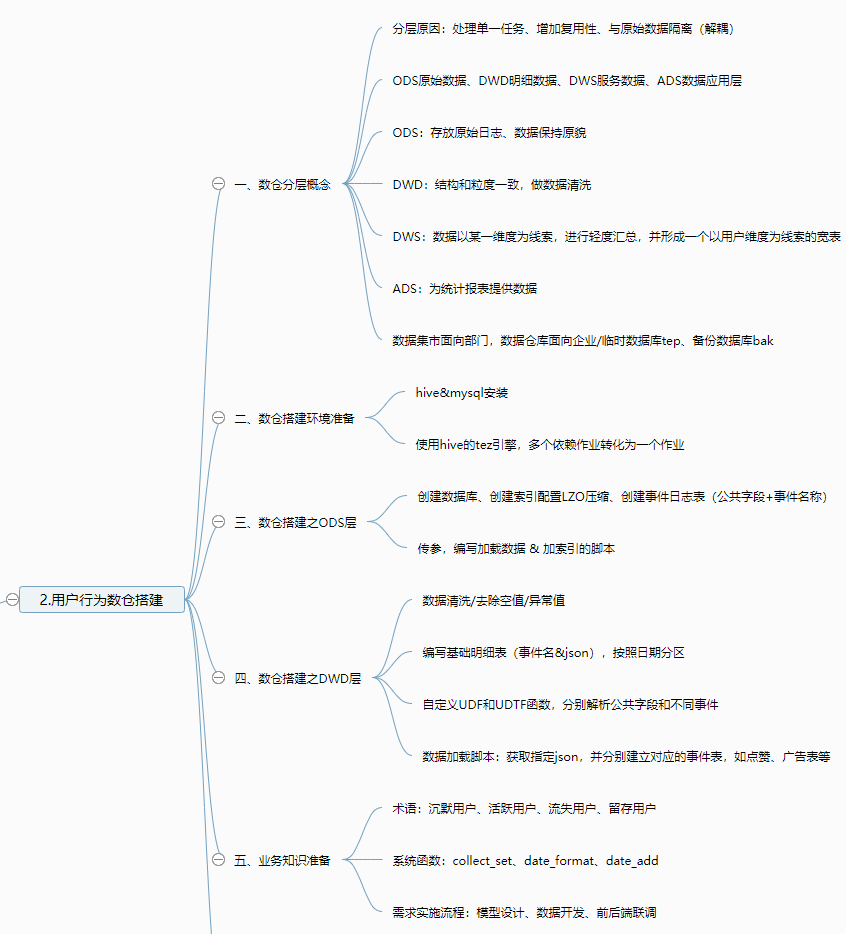
一、数仓分层概念
1、为什么要分层
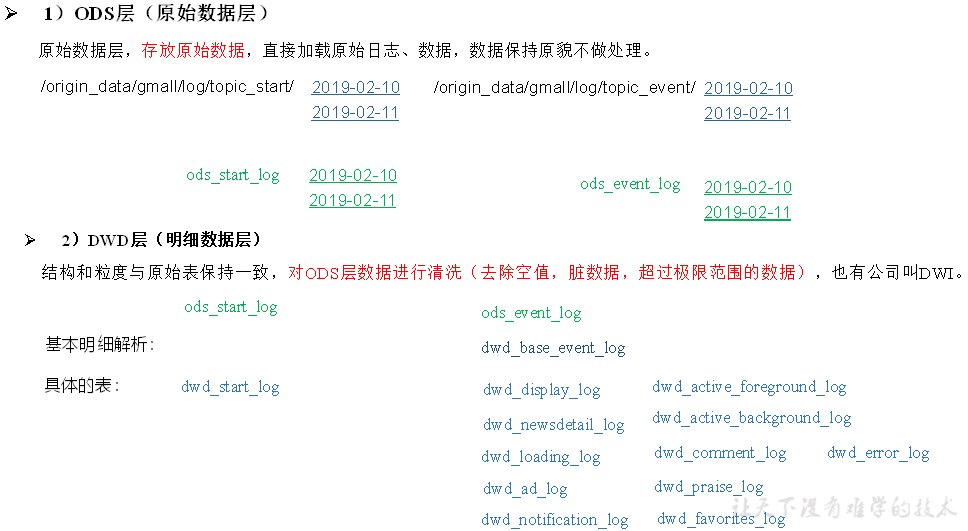
ODS:原始数据层
DWD层:明细数据层
DWS:服务数据层
ADS:数据应用层

2、数仓分层

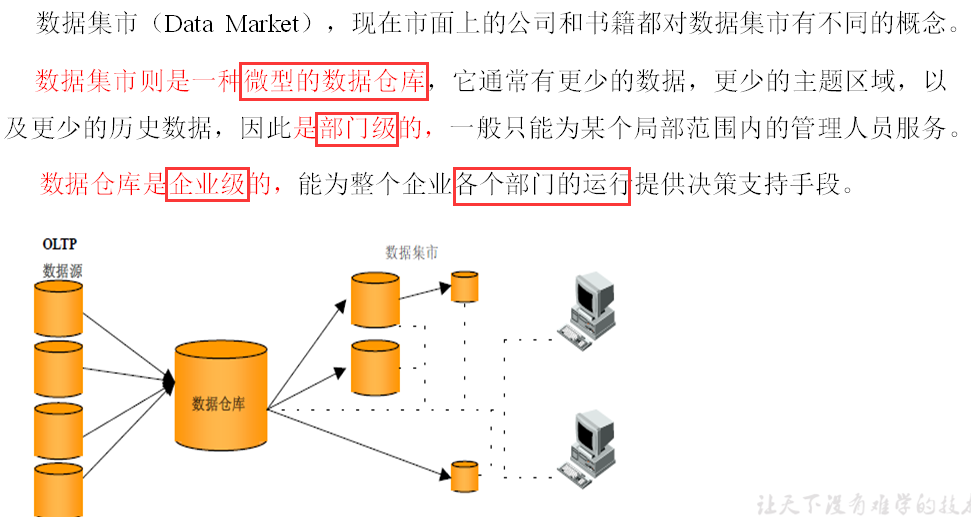
3、数据集市与数据仓库概念
4、数仓命名规范
ODS层命名为ods
DWD层命名为dwd
DWS层命名为dws
ADS层命名为ads
临时表数据库命名为xxx_tmp
备份数据数据库命名为xxx_bak
二、数仓环境搭建
1、Hive&MySQL安装
修改hive-site.xml,关闭元数据检查
设置元数据备份:每日零点之后备份到其它服务器两个
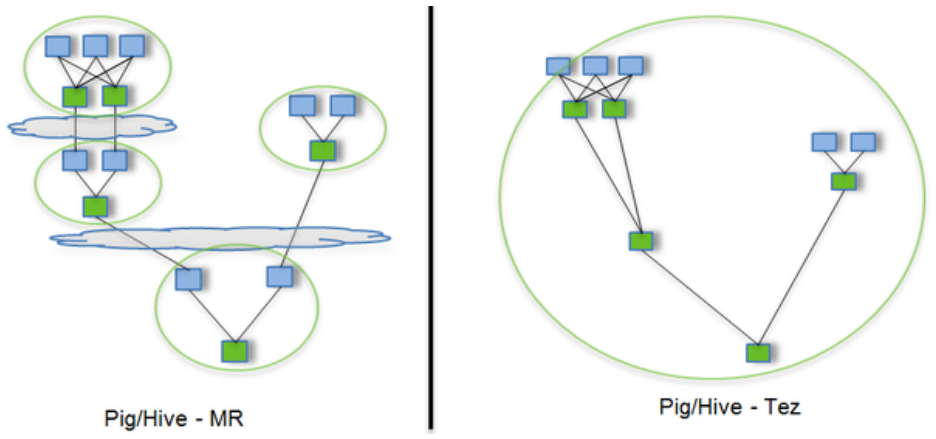
2、Hive运行引擎Tez
Hive的运行引擎,性能优于MR(用Hive直接编写MR程序,需要将中间结果持久化写到HDFS)
Tez可以将多个有依赖的作业转换为一个作业
Hive中配置Tez:/opt/module/hive/conf下面创建一个tez-site.xml文件
hive-env.sh文件中添加tez环境变量配置和依赖包环境变量配置
[atguigu@hadoop102 hive]$ bin/hive启动、创建、插入测试
三、数仓搭建之ODS层
1、创建数据库
create database gmall;
2、ODS层
支持LZO压缩配置:将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-2.7.2/share/hadoop/common/
core-site.xml增加配置支持LZO压缩
同步core-site.xml
创建lzo文件的索引,lzo压缩文件的可切片特性依赖于其索引
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /user/hive/warehouse/bigtable
建完索引时,查询时map个数变多
启动日志表ods_start_log创建,需要创建索引

创建事件日志表ods_event_log

Shell中单引号和双引号区别
(1)单引号不取变量值
(2)双引号取变量值
(3)反引号,执行引号中命令
(4)双引号内部嵌套单引号,取出变量值
(5)单引号内部嵌套双引号,不取出变量值
ODS层加载数据脚本(加载数据&加索引)
load data inpath '/origin_data/gmall/log/topic_event/$do_date' into table "$APP".ods_event_log partition(dt='$do_date'); $hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /warehouse/gmall/ods/ods_start_log/dt=$do_date
四、数仓搭建之DWD层
对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据,行式存储改为列存储,改压缩格式)
1、启动表
创建、导入数据、编写加载数据脚本,传递日期参数
2、DWD层事件表
基础明细表:存储明细数据
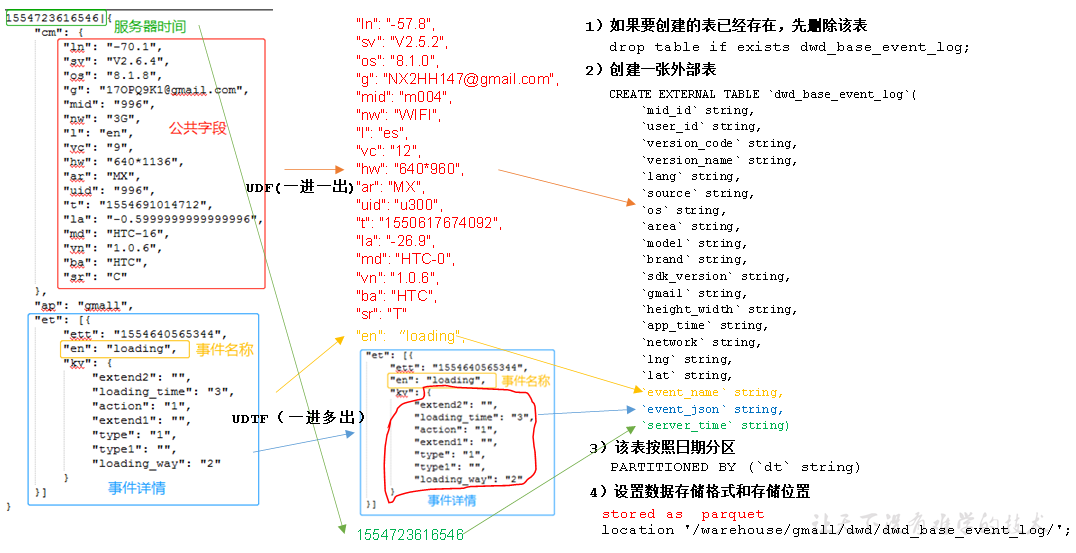
UDF和UDTF:
自定义UDF函数(解析公共字段)
自定义UDTF函数(解析具体事件字段)-获取事件、遍历、得到结果并返回
创建永久函数与开发好的java class关联
3、DWD层事件表获取
新添加字段
`entry` string, `action` string, `goodsid` string, `showtype` string, `news_staytime` string, `loading_time` string, `type1` string, `category` string,
基础明细表:导入数据时调用编写的方法get_json_object(event_json,'$.kv.loading_way')
商品点击表
商品详情页表
商品列表页表
广告表

获取json信息并加入
事件表加载数据脚本
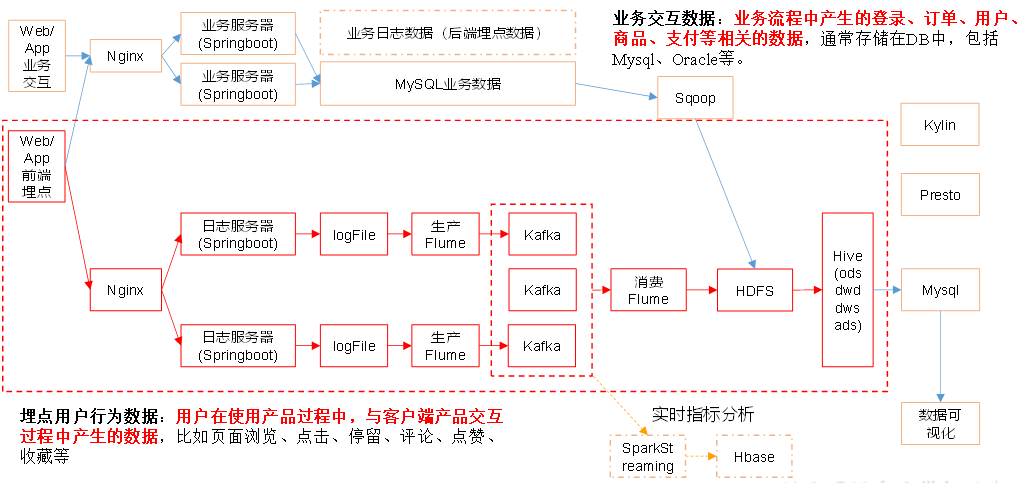
五、业务知识准备
1、业务术语
活跃用户
沉默用户
版本分布
流失用户
留存用户
使用时长
2、系统函数
collect_set函数:把同一分组的不同行的数据聚合成一个集合
hive (gmall)> select course, collect_set(area), avg(score) from stud group by course; chinese ["sh","bj"] 79.0 math ["bj"] 93.5
日期处理函数(datediff):date_format、date_add、next_day、last_day
当前周的周一:date_add(next_day('2019-02-12','MO'),-7)
3、需求实施流程
业务口径、技术口径、原型设计和评审、模型设计(分层建模)、数据开发、前后端开发、联调、测试、上线
以用户活跃需求为例,ods层需要存放start_log(启动日志),dwd层需要对数据进行清洗、过滤,dws层需要对数据进行轻度聚合,ads层需要得出最终统计指标的结果
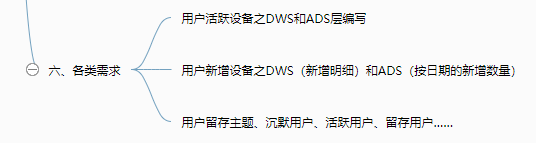
六、需求一:用户活跃主题
1、DWS层
目标:统计当日(dau)、当周、当月活动的每个设备明细
以用户单日访问为key进行聚合group by mid_id;【`mid_id` string COMMENT '设备唯一标识'】
周活跃明细:

导入数据
date_add(next_day('2019-12-14','MO'),-7),
date_add(next_day('2019-12-14','MO'),-1),
concat(date_add( next_day('2019-12-14','MO'),-7), '_' , date_add(next_day('2019-12-14','MO'),-1)
)
月活跃设备明细

2、ADS层
活跃设备数,加字段

hive (gmall)> drop table if exists ads_uv_count; create external table ads_uv_count( `dt` string COMMENT '统计日期', `day_count` bigint COMMENT '当日用户数量', `wk_count` bigint COMMENT '当周用户数量', `mn_count` bigint COMMENT '当月用户数量', `is_weekend` string COMMENT 'Y,N是否是周末,用于得到本周最终结果', `is_monthend` string COMMENT 'Y,N是否是月末,用于得到本月最终结果' ) COMMENT '活跃设备数' row format delimited fields terminated by '\t' location '/warehouse/gmall/ads/ads_uv_count/';
七、用户新增主题
1、DWS:每日新增设备明细表

2、ADS层(每日新增设备表)

八、用户留存主题
1、需求目标


2、DWS层
DWS层(每日留存用户明细表)

DWS层(1,2,3,n天留存用户明细表)
from dws_uv_detail_day ud join dws_new_mid_day nm on ud.mid_id =nm.mid_id where ud.dt='2019-02-11' and nm.create_date=date_add('2019-02-11',-1) union all
(1)union会将联合的结果集去重,效率较union all差
(2)union all不会对结果集去重,所以效率高
3、ADS层:留存用户数
hive (gmall)> drop table if exists ads_user_retention_day_count; create external table ads_user_retention_day_count ( `create_date` string comment '设备新增日期', `retention_day` int comment '截止当前日期留存天数', `retention_count` bigint comment '留存数量' ) COMMENT '每日用户留存情况' row format delimited fields terminated by '\t' location '/warehouse/gmall/ads/ads_user_retention_day_count/';
留存用户比率

九、新数据准备
分析沉默用户、本周回流用户数、流失用户、最近连续3周活跃用户、最近七天内连续三天活跃用户数,需要准备2019-02-12、2019-02-20日的数据
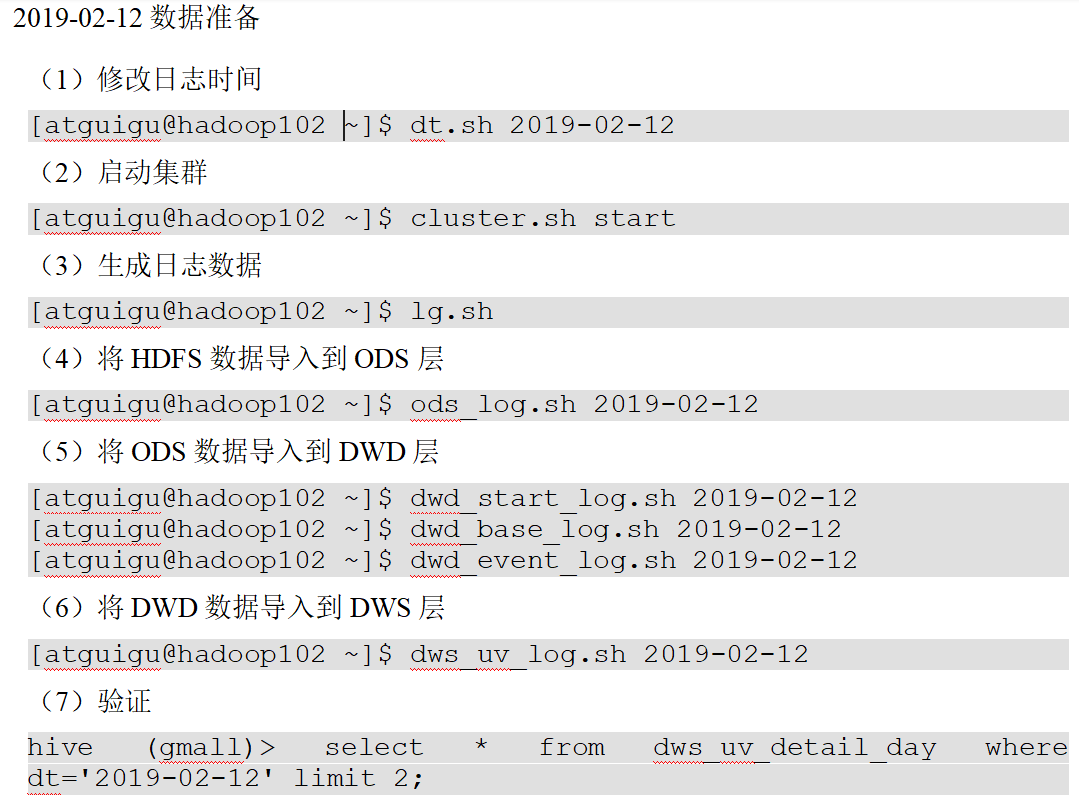
十、沉默用户数
沉默用户:指的是只在安装当天启动过,且启动时间是在一周前

……
十一、总结
1、用户行为数仓业务总结
1)ODS层(原始数据层)
存储原始数据,直接加载原始日志、数据,数据保持原貌不做处理。
2)DWD层(明细层)
对ODS层数据进行清洗(去除空值、脏数据,超过极限范围的数据)
3)DWS层(服务数据层)
以DWD层为基础,进行轻度汇总。比如:用户当日、设备当日、商品当日。
4)ADS层(数据应用层)
2、Tez优点:将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
2、在项目中是否自定义过UDF、UDTF函数,以及用他们处理了什么问题?
自定义过。
用UDF函数解析公共字段;用UDTF函数解析事件字段。
21.1.5 如何分析用户新增?
用活跃用户表 left join 用户新增表,用户新增表中mid为空的即为用户新增。
21.1.6 如何分析用户1天留存?
留存用户=前一天新增 join 今天活跃
用户留存率=留存用户/前一天新增
21.1.7 如何分析沉默用户?
按照设备id对日活表分组,登录次数为1,且是在一周前登录。
21.1.8 如何分析本周回流用户?
本周活跃left join本周新增 left join上周活跃,且本周新增id和上周活跃id都为null
21.1.9 如何分析流失用户?
按照设备id对日活表分组,且七天内没有登录过。
21.1.10 如何分析最近连续3周活跃用户数?
按照设备id对周活进行分组,统计次数等于3次。
21.1.11 如何分析最近七天内连续三天活跃用户数?
1)查询出最近7天的活跃用户,并对用户活跃日期进行排名
2)计算用户活跃日期及排名之间的差值
3)对同用户及差值分组,统计差值个数
4)将差值相同个数大于等于3的数据取出,然后去重,即为连续3天及以上活跃的用户
整个文档中涉及的所有层级及表
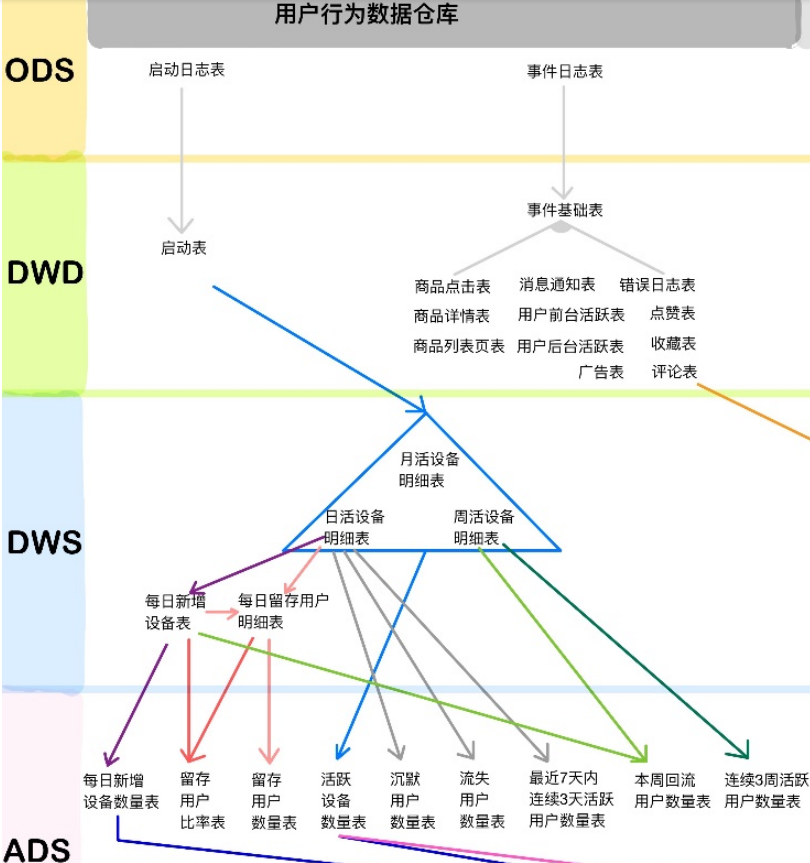
3、hive总结
窗口函数、排序函数
hive优化:分桶、小文件合并、map和reduce数量设置
常用参数设置
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15643512.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix