
【CDH数仓】Day01:概念、环境搭建、CDH数仓搭建、用户行为数仓搭建

一、数仓之Cloudera Manager
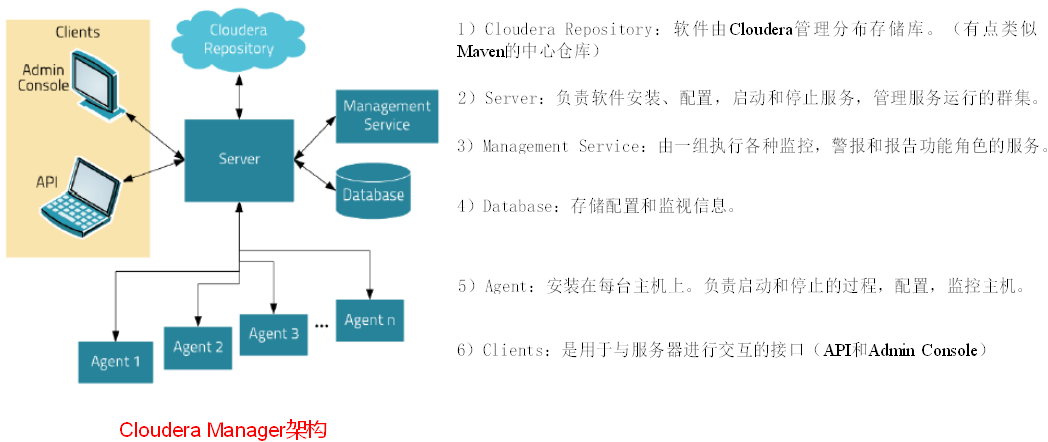
1、CM简介
拥有集群自动化安装、中心化管理、集群监控、报警功能的一个工具
快速安装,快速运维,提高集群的效率

CM架构
2、阿里云服务器准备
注册账号
购买ECS云服务器
ECS配置及安全组修改(开放各服务的端口)
3、CM部署准备
服务器连接
修改hosts文件
通过生成公钥和私钥配置SSH免密登录
编写集群同步脚本xsync
编写集群整体操作脚本vim xcall.sh
关闭防火墙和SELINUX
配置NTP时钟同步
4、CM安装部署
安装JDK
安装MySQL及其驱动(hadoop102上操作)
搭建本地yum源安装CM
进入/var/www/html/路径,并开启http服务
安装并修改CM配置文件
在MySQL中建数据库
启动服务:systemctl start cloudera-scm-server
查看日志并访问web ui
关闭服务
二、数仓之CDH
1、选择使用版本
免费版
2、部署CDH集群
选定物理节点
添加本地parcel库
自定义安装组件
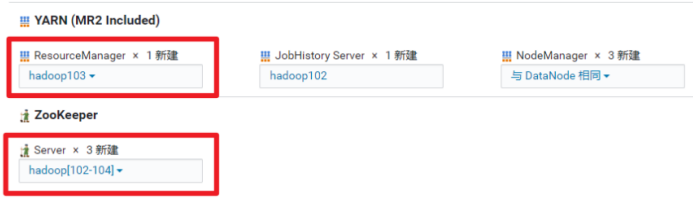
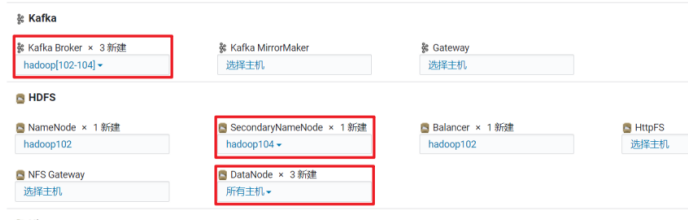
角色分布
测试数据库连接
三、数仓搭建环境准备
1、Flume 安装部署
添加服务
选择依赖及部署节点
2、Sqoop安装部署
3、配置Hadoop支持LZO
配置-gplextras parcel库的url
Parcel列表中出现了GPLEXTERAS,依次点击下载、分配、激活
修改HDFS配置压缩编码解码器,加入com.hadoop.compression.lzo.LzopCodec
配置Hive 辅助 JAR 目录
修改Sqoop配置,配置项中搜索“sqoop-conf/sqoop-env.sh 的 Sqoop 1 Client 客户端高级配置代码段(安全阀)
4、修改yarn配置参数
配置内存大小“yarn.nodemanager.resource.memory-mb”,修改成4G
“yarn.scheduler.maximum-allocation-mb”,修改成2G
重启相关组件
5、HUE使用概述
HUE=Hadoop User Experience(Hadoop用户体验),Hadoop的UI系统
http://hadoop102:8888(未优化)或http://hadoop102:8889(优化)
6、HUE用户管理
新建一个用户组——hive,并添加hive用户
四、数仓之用户行为数仓搭建
1、用户行为日志生成
分发jar包log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar
并启动lg.sh脚本(将打印的数据读入)
2、日志数据导入数仓
日志采集Flume配置
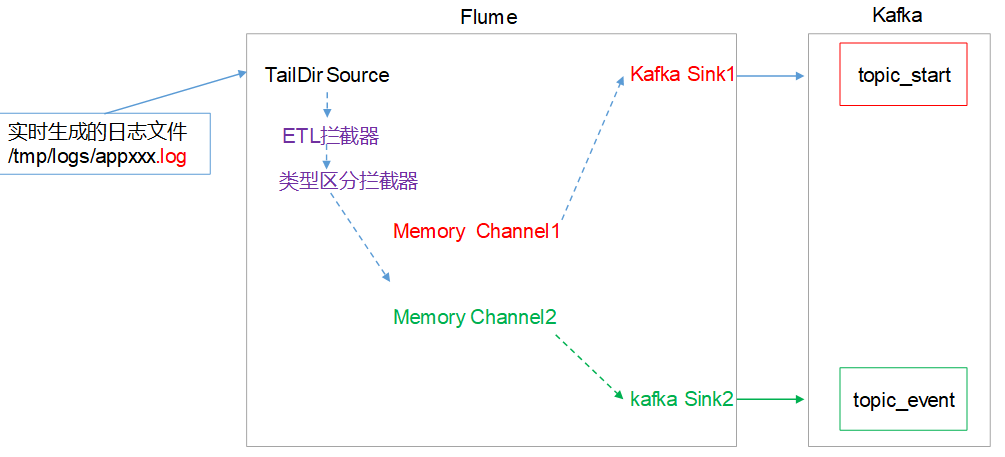
Flume拦截器:ETL拦截器LogETLInterceptor(编写工具类调用)、日志类型区分拦截器LogTypeInterceptor
ETL拦截器主要用于,过滤时间戳不合法和Json数据不完整的日志
日志类型区分拦截器主要用于,将启动日志和事件日志区分开来,方便发往Kafka的不同Topic。
拦截器打包放入lib目录并进行分发
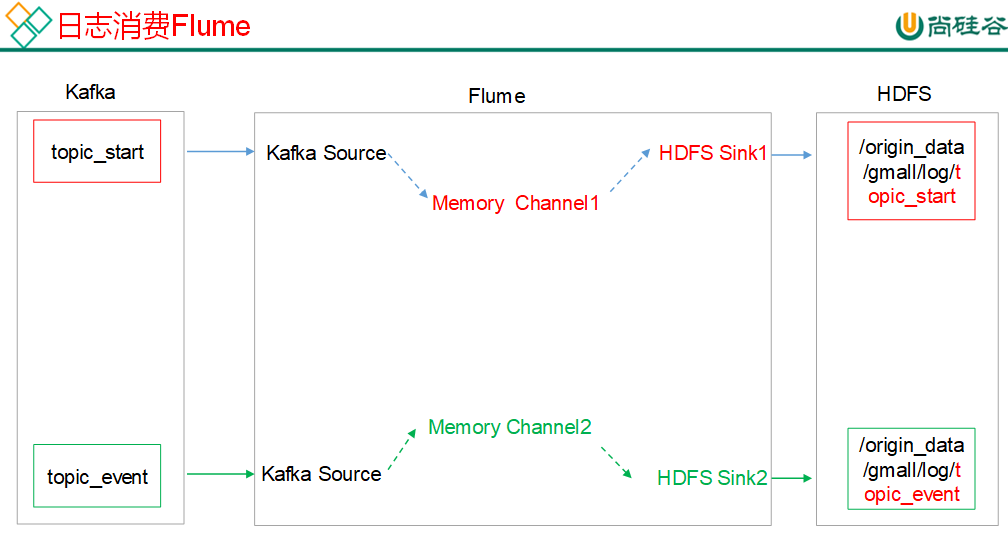
消费Kafka Flume配置
调用日志生成脚本lg.sh
#! /bin/bash for i in hadoop102 hadoop103 do ssh $i " source /etc/profile ; java -classpath /opt/module/log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.atguigu.appclient.AppMain $1 $2 >/opt/module/test.log &" done
3、ODS层-原始数据层,存放原始数据
创建数据库:创建数据仓库目录、修改hive配置并启动、创建并使用gmall数据库
创建启动日志表ods_start_log
ODS层加载数据脚本:将指定日期数据加入表中
4、DWD层启动表数据解析
创建启动表、DWD层启动表加载数据脚本dwd_start_log.sh
5、DWS层(需求:用户日活跃)
统计当日、当周、当月活动的每个设备明细

编写加载数据脚本
6、ADS层(需求:用户日活跃)
目标:当日活跃设备数
编写ADS层加载数据脚本
#!/bin/bash # 定义变量方便修改 APP=gmall # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天 if [ -n "$1" ] ;then do_date=$1 else do_date=`date -d "-1 day" +%F` fi sql=" set hive.exec.dynamic.partition.mode=nonstrict; insert into table "$APP".ads_uv_count select '$do_date' dt, daycount.ct from ( select '$do_date' dt, count(*) ct from "$APP".dws_uv_detail_day where dt='$do_date' )daycount; " beeline -u "jdbc:hive2://hadoop102:10000/" -n hive -e "$
增加执行权限并使用:ads_uv_log.sh 2019-09-03
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15631051.html

