
【Zookeeper】结构、应用、安装部署与参数、客户端命令行操作、API应用、内部原理(选举机制、写数据、监听器)
一、Zookeeper入门
1、概述
分布式服务管理框架(存储和管理数据)
Zookeeper=文件系统+通知机制
2、特点
主从集群
半数以上,正常工作
请求顺序执行
数据更新具有原子性
3、数据结构
树形结构,每个节点被称为一个Znode
一个znode存储1MB数据
4、应用场景
统一命名服务(域名而无需ip)
统一配置管理(集群节点配置一致,需要快速同步)
统一集群管理(监控节点的状态变化)
服务器节点动态上下线(上下线通知)
软负载均衡(记录服务器访问次数)
二、安装
1、本地模式
修改配置zoo.cfg
启动zk服务bin/zkServer.sh start / 停止bin/zkServer.sh stop
启动客户端bin/zkCli.sh / 退出quit
2、配置参数
tickTime =2000:通信心跳数
initLimit =10:LF初始通信时限
syncLimit =5:LF同步通信时限
dataDir:数据文件目录+数据持久化路径
clientPort =2181:客户端连接端口
三、Zookeeper实战
1、分布式安装部署
添加与server对应的编号
进行同步xsync myid
修改配置server.4=hadoop104:2888:3888---交换信息的端口:选举时通信的端口
启动、查看状态bin/zkServer.sh status
2、客户端命令行操作
查看子节点:ls path
获得节点的值:get path
递归删除节点:deleteall 或 rmr /sanguo/shuguo
创建短暂节点: create -e /sanguo/wuguo "zhouyu"
3、API应用
创建客户端zkClient
创建子节点zkClient.getChildren("/", true);
判断节点是否存在:zkClient.exists("/eclipse", false);
4、监听服务器节点动态上下线
任意一台客户端都能实时感知到主节点服务器的上下线
获取子节点信息:client.getServerList();
四、Zookeeper内部原理
1、节点类型
持久化(顺序)目录节点
临时目录节点(按节点名称顺序编号)
2、Stat结构体
修改状态会得到zxid形式的时间戳,也就是ZooKeeper事务ID
ctime 、mzxid 、mtime 、pZxid、cversion 、dataversion 、aclVersion 、ephemeralOwner、dataLength、numChildren
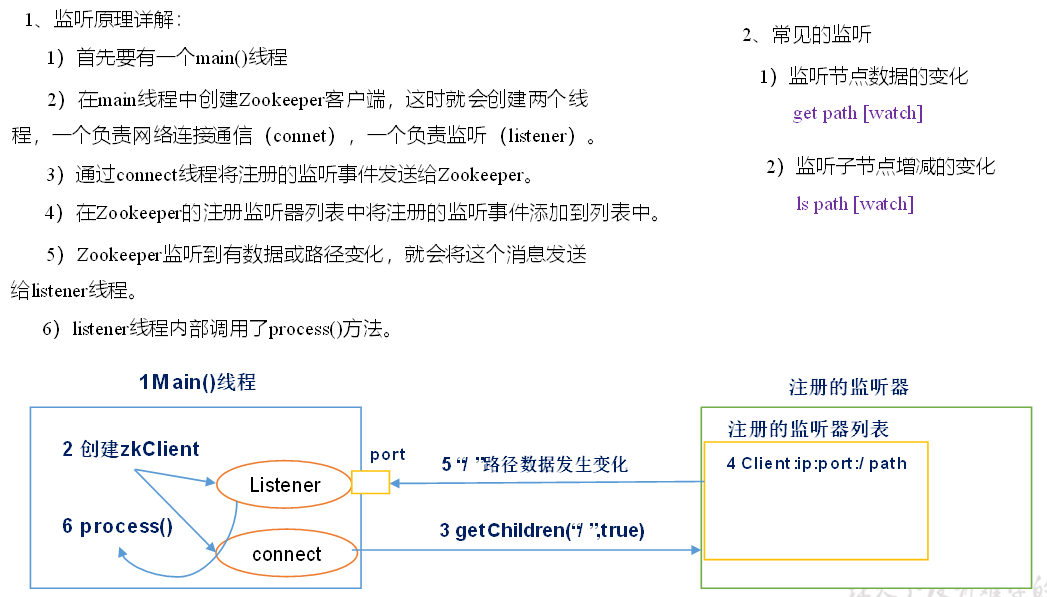
3、监听器原理
main创建两个线程connect和listener
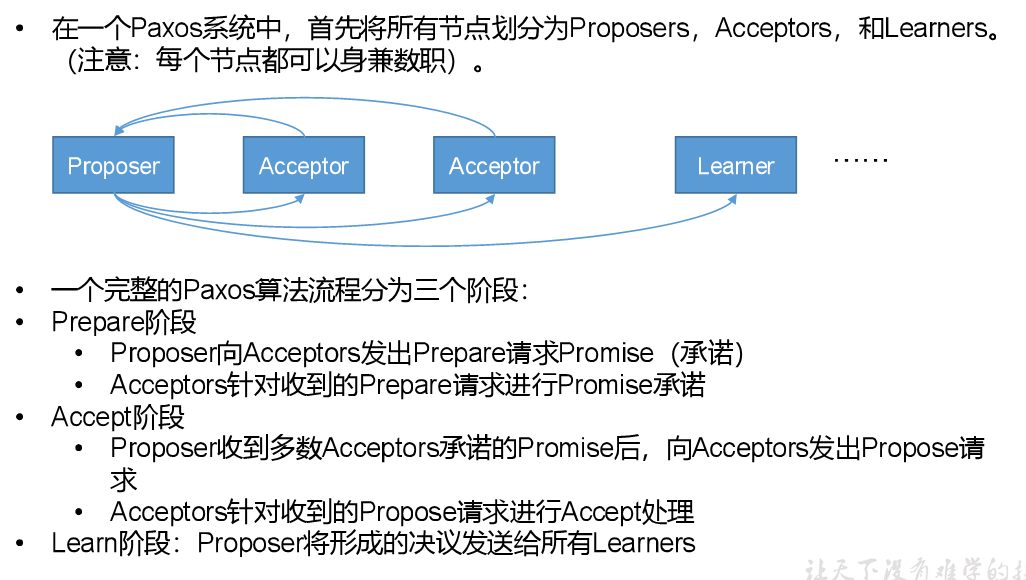
4、Paxos算法
基于消息传递且具有高度容错特性的一致性算法。
5、选举机制
半数机制(奇数个节点,三五个)
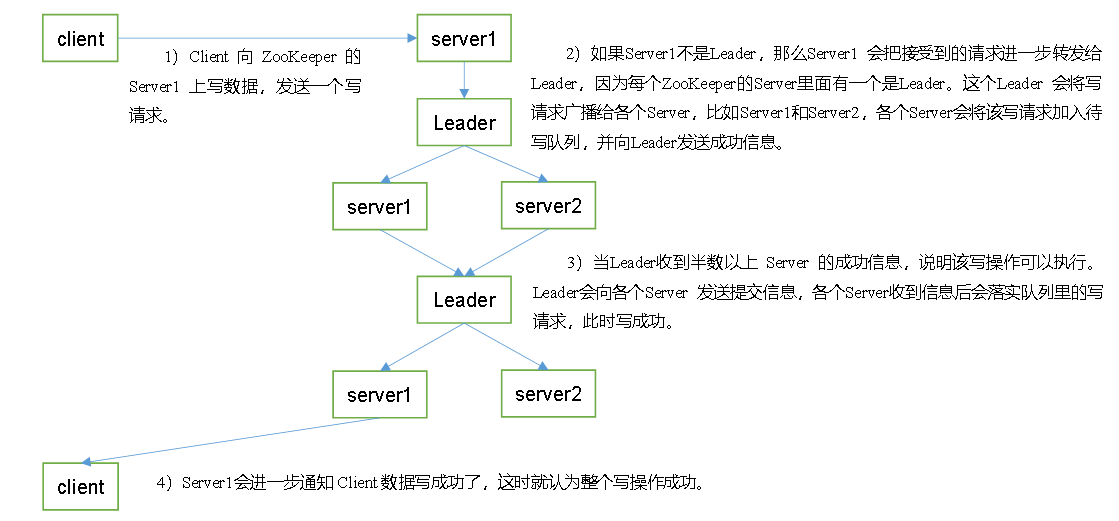
6、写数据流程
7、部署方式
(1)部署方式单机模式、集群模式
(2)角色:Leader和Follower
(3)集群最少需要机器数:3
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15515541.html

