
【Hadoop学习】补充:优化、新特性
一、数据压缩
1、概述
原则:IO密集而不是计算密集的job
压缩算法选择
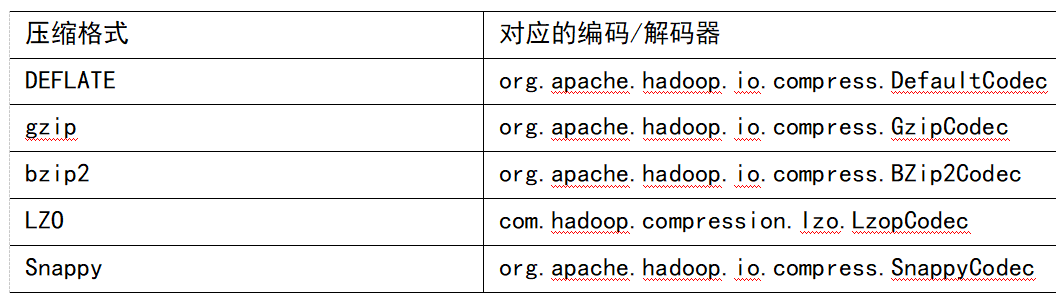
2、压缩位置选择

通过参数进行配置
3、压缩实例:
数据流的压缩和解压缩
Map输出端采用压缩
Reduce输出端采用压缩
二、企业优化
1、概述
从六个方面考虑:数据输入、Map阶段、Reduce阶段、IO传输、数据倾斜问题和常用的调优参数
数据输入:合并小文件、Combine格式输入
Map阶段:减少溢写及合并次数
Reduce阶段:合理设置Map、Reduce(规避使用),二者需要共存,合理设置reduce的buffer
IO传输:数据压缩、使用sequence二进制文件
数据倾斜问题(大小倾斜/频率倾斜):抽样、自定义分区、combine
调优参数:资源相关参数(mapred-default.xml)、yarn相关的参数(yarn-default.xml)、容错相关参数
2、小文件优化


三、Hadoop新特性
1、集群间数据拷贝(scp、distcp递归复制)
2、小文件存档
启动yarn,使用命令bin/hadoop archive归档和解归档
3、回收站
core-site.xml中配置fs.trash.interval
路径/user/atguigu/.Trash/….
清空回收站:hadoop fs -expunge
4、多NN的HA和纠删码
运行多个备用NameNode
四、HA高可用
1、概述
HA(High Availablity)
双NameNode消除单点故障
故障转移机制
2、集群配置
ZK集群、HDFS集群、YARN集群、
3、HDFS Federation
单个NameNode的HDFS架构,因此整个HDFS文件系统的吞吐量受限于单个NameNode的吞吐量,受到Namespace(命名空间)的限制
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15510761.html

