
【Hadoop学习】下:MapReduce程序编写、Hadoop序列化、框架原理、Yarn组件、设置队列
一、MapReduce概述
1、定义
编程框架,组成分布式运算程序,运行在集群上
2、特点
优点:易于编程、扩展性、容错性(内部完成)、海量数据离线处理
缺点:非实时、不擅长流式计算、不擅长DAG有向图计算
3、原理
编程思想:MapTask-->ReduceTask
三类进程:MrAppMaster(过程调度)、MapTask、ReduceTask(数据处理)
驱动类setjar设置jar包路径
maven打包并执行:右键->Run as->maven install
二、Hadoop序列化
1、概念
对象转换成字节序列
不用java序列化:重量级、序列化的对象附带额外信息
2、过程
定义bean实现序列化接口(Writable)
空参构造
重写序列化和反序列化方法
3、实操:统计手机号的上传下载流量
编写bean方法
编写mapper类
编写reducer类,分别对上行流量和下行流量累加
三、MapReduce框架原理
1、InputFormat数据输入
MapTask并行度决定机制:数据块和切片大小
2、FileInputFormat切片机制
按照文件长度切片,默认为block大小
缺陷:小文件
3、CombineTextInputFormat切片机制
可以将多个小文件从逻辑上规划到一个切片中
4、TextInputFormat的KV
读取记录,K是偏移量,V是内容
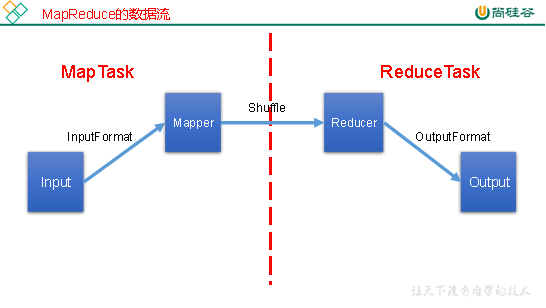
5、MapReduce工作流程
6、shuffle机制
Map方法之后,Reduce方法之前的数据处理过程
7、Partition分区
不同结果输出到不同的区中
实操:按照归属地省份分区到不同的文件中
8、自定义排序WritableComparable排序
实现WritableComparable接口重写compareTo方法
9、实操:全排序(按照总体流量排序)、区内排序(手机流量)
10、Combiner合并
局部汇总,不影响全局逻辑
多个重复的,按照数量汇总去重,计数
11、MapTask工作机制
、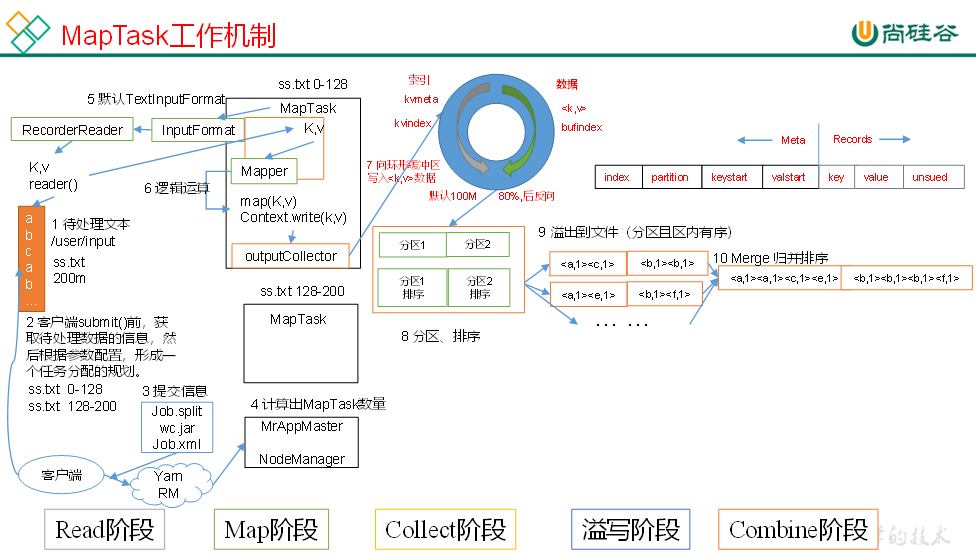
Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。
12、 ReduceTask工作机制
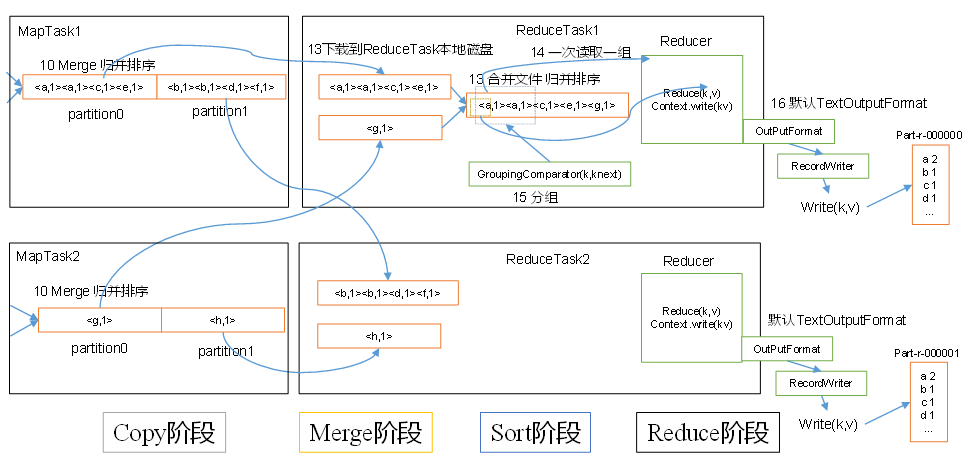
13、OutputFormat数据输出
控制文本输出路径和格式
可以使用自定义OutputFormat
14、Join多种应用
区别不同来源的记录
Reduce Join(reduce阶段完成,压力大)
Map Join(一张表大,一张表小)
15、计数器应用
数据清洗(ETL):去除小于11的日志



四、Yarn资源调度器
1、架构组成
ResourceManager、NodeManager、ApplicationMaster和Container
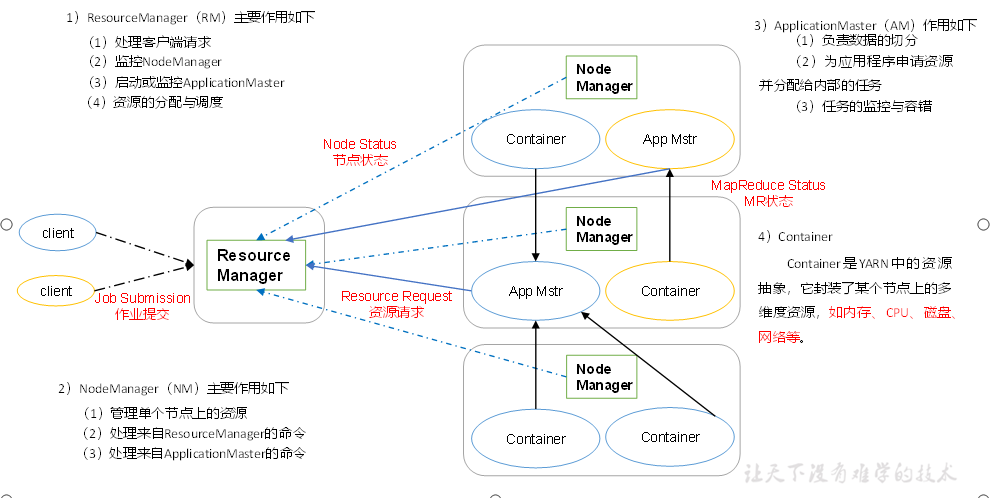
2、工作机制
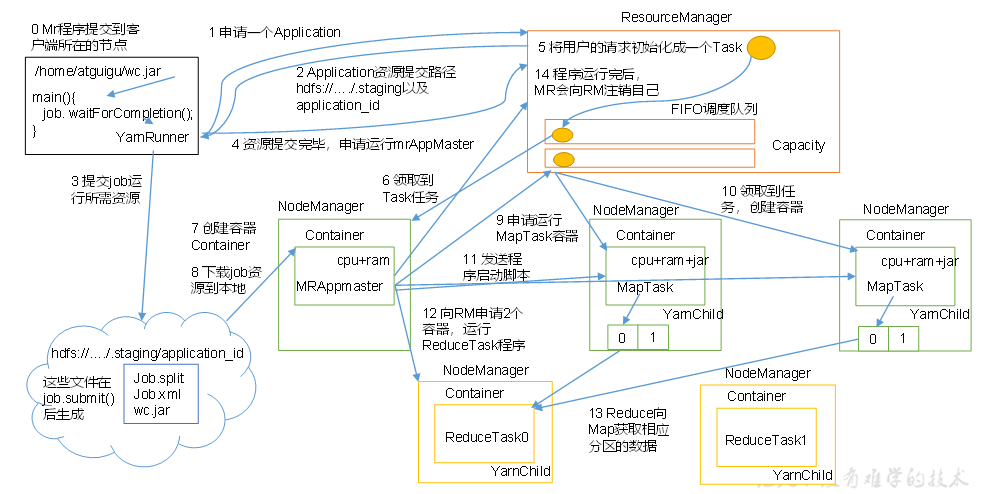
3、作业提交全过程
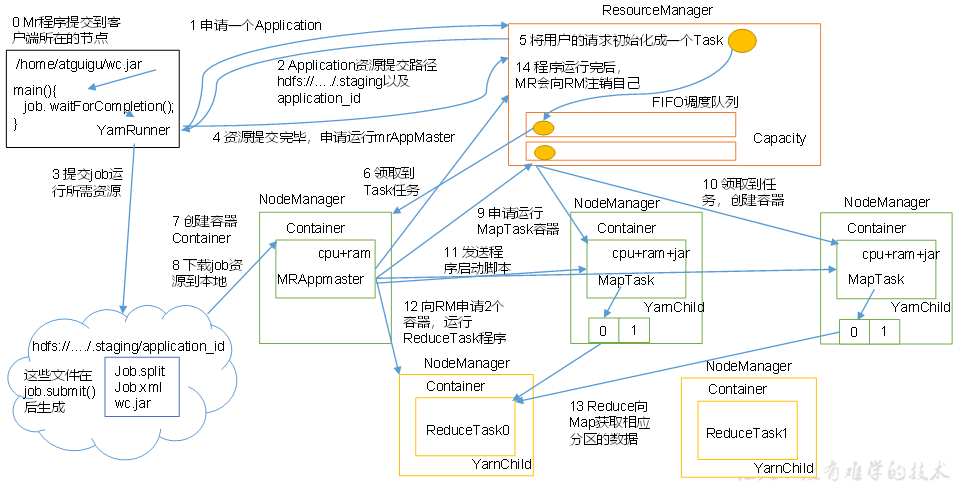
4、资源调度器
Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler
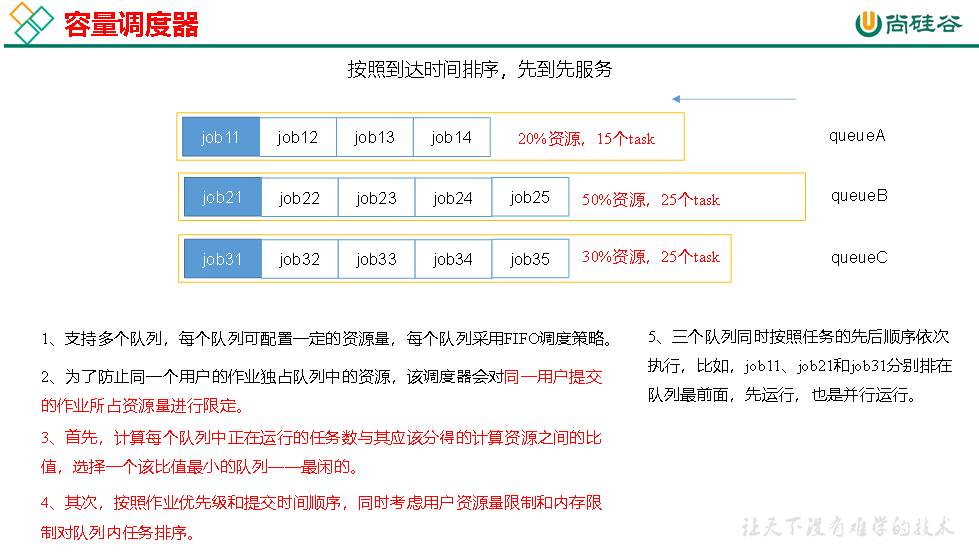
选择比值最小的队列
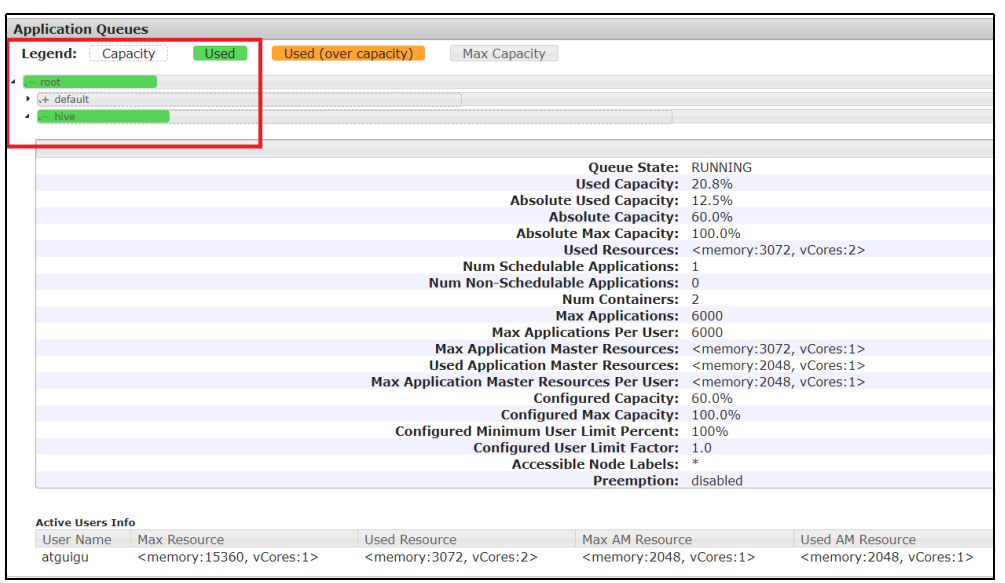
5、分业务限制集群使用率。这就需要我们按照业务种类配置多条任务队列。
capacity-scheduler.xml中可以配置多条队列
重启yarn就可以进行查看
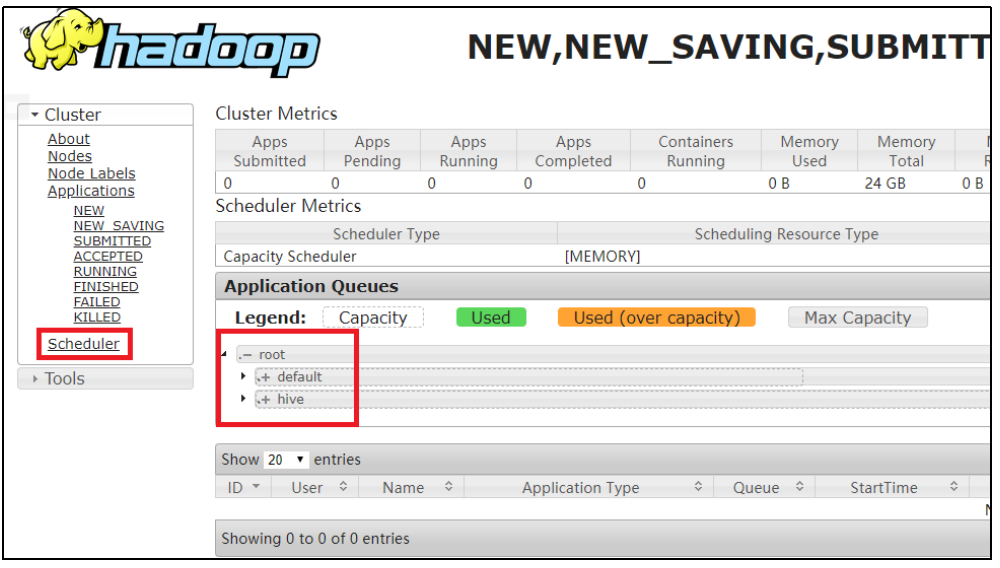
向hive队列提交任务
Driver中声明
configuration.set("mapred.job.queue.name", "hive");
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15501482.html

