
【Hadoop学习】中:HDFS、shell操作、客户端API操作、数据流、1NN、2NN原理、DataNode配置
一、概述
1、背景、定义、使用场景(一次写入、不支持修改)
2、优(容错)缺点(延迟、不支持小文件、不支持修改)
3、组成架构
NameNode:Master,管理命名空间、配置策略
DataNode:slave,执行数据读写操作
Client:使用命令访问和交互
SecondNameNode:辅助分担namenode的工作量、恢复namenode
4、HDFS文件块大小
分块存储,默认128M(寻址时间为传输时间的1%),块大小取决于磁盘传输速率
二、HDFS的shell操作
1、基本语法:bin/hadoop fs 或 bin/hadoop dfs
2、常见操作:
启动集群(sbin/start-dfs / yarn.sh)
上传文件:hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo【剪切、复制】
追加到文件:hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
下载:合并下载hadoop fs -getmerge /user/atguigu/test/* ./zaiyiqi.txt
3、hdfs直接操作
hadoop fs -mkdir
-chgrp 、-chmod、-chown、-tail显示末尾、-du统计信息、-setrep设置副本数量
三、HDFS客户端操作
1、客户端创建目录:fs.mkdirs(new Path("/1108/daxian/banzhang"));
2、API操作
文件上传:设置路径参数的优先级
文件下载:fs.copyToLocalFile
文件夹删除:fs.delete
文件名更改:fs.rename
获取文件详情:fs.listFiles
判断文件/文件夹:fs.listStatus
四、HDFS的数据流
1、写数据
向NameNode请求上传
通过packet逐级应答客户端
依次上传每个block的数据
节点距离:两个节点到达最近的共同祖先的距离总和。
2、读数据
向NameNode请求下载
查询元数据,获得对应的DataNode
packet方式传输数据给客户端
五、NameNode和Second NameNode
1、1 NN和2NN的工作机制
Fsimage和Edits文件存储namenode的元数据
NameNode节点断电,就会产生数据丢失
添加元数据时,修改内存中的元数据并追加到Edits【只追加,效率高】
二者合并,合成元数据【使用2NN完成二者合并】
2、oiv和oev命令可以查看Fsimage和Edits文件
3、2NN的CheckPoint时间设置
配置:默认1小时
或一分钟检查一次,操作次数达到一万次时执行一次
4、NameNode故障处理
2NN数据拷贝(手动)
使用-importCheckpoint选项启动NameNode守护进程,自动实现2NN的数据拷贝
5、安全模式
开启后只读,不能进行写操作
使用命令执行:查看、进入、离开、等待
六、DataNode
1、工作机制
周期性上报块信息到NN,
3秒一次心跳,10分钟未收到NN心跳表示节点不可用
2、数据完整性
周期验证CheckSum【数据一起发送的校验位】
3、掉线时限参数设置
hdfs-site.xml 配置文件中的heartbeat.recheck.interval、dfs.heartbeat.interval
4、服役新数据节点
克隆新主机,直接启动DataNode,即可关联集群
同时可以执行./start-balancer.sh实现数据均衡
5、退役旧数据节点
添加白名单的主机允许访问:vi dfs.hosts
需要配置hdfs-site.xml中的dfs.host属性
配置文件分发,刷新NN和ResourceManager节点
黑名单退役:
退役节点添加到:dfs.hosts.exclude中
配置文件分发:xsync hdfs-site.xml
刷新NN:hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes更新ResourceManager节点
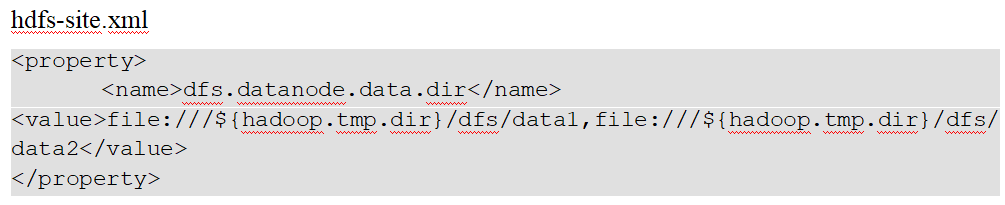
6、Datanode多目录配置
每个目录存储的数据不一样
hdfs dfsadmin -refreshNodes
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15487878.html

