
Hadoop知识总结
〇、目录
一、架构
1、组成:MapReduce(数据分析)、HDFS(分布文件管理)、Yarn(资源管理器)
2、HDFS:文件读写、存储
3、MapReduce:不同语言编写mr函数,通过JobTracker调度,通过TaskTracker执行,应用:单词计数、数据去重、单表关联、多表关联。(可以通过命令行执行Hadoop Streaming流,通常用于简单的任务)
4、Yarn:由全局的Resource Manager、Node Manager、Application Master和Container等组件构成,它是一个master/slave结构
5、Hadoop生态架构图
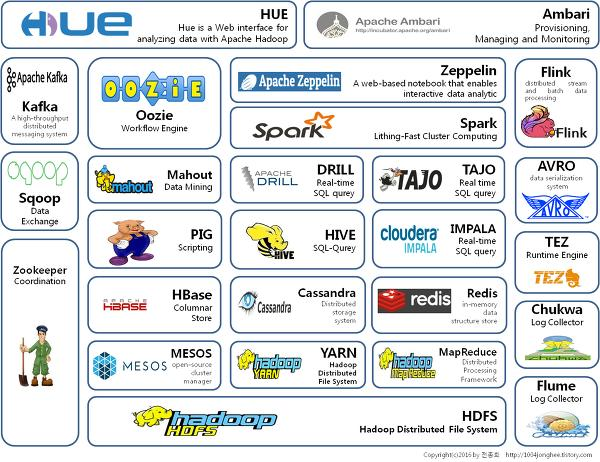
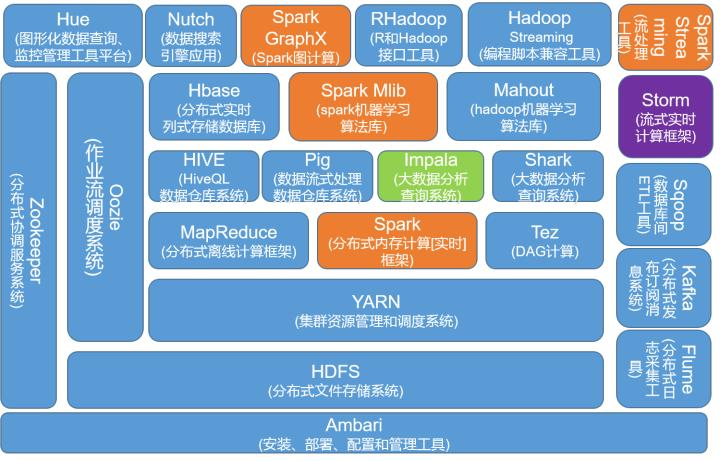
二、安装
虚拟机配置网关(host)
关闭selinux和防火墙
安装jdk及Hadoop
三、模式介绍
本地单节点模式
伪分布式模式
分布式模式
四、本地单节点模式
1、案例程序,匹配正则表达式,计算词频wordcount
2、过程:input(输入源文件)—>map(拆分)—>reduce(合并)—>output(输出结果)
五、伪分布式模式
1、一个节点上启动,并配置数据目录,可以jps看到各个进程
2、访问HDFS的Hadoop Administration可以浏览文件系统,上传文件,查看状态
3、迁移到yarn系统上运行,配置/mapred-site.sh及主从节点位置
启动yarn,可以看到resoucemanger,nodemanger
通过yarn系统的ui,可以看到执行进度
4、可以启动yarn系统的聚集日志及垃圾回收
聚集日志有其保存时间
垃圾回收时有文件保存时间
七、Hadoop Java API
1、读文件操作
2、写文件操作
3、MapReduce开发
Mapper和Reducer的静态内部实现类分别实现map方法和reduce方法
run方法负责运行,给job添加map和reduce对应的类
实现map负责查分,reduce负责合并
打成jar包并运行,输入输出作为参数
自定义数据类型,实现接口重写方法
八、分布式模式
1、步骤
克隆机器,设置固定ip
改名并配置映射地址
解压Hadoop并配置集群地址
配置主从节点信息并进行分发,分发后重新生成秘钥配置
启动yarn并查看节点是否顺利启动
2、zookeeper的安装和使用
配置数据目录,单节点启动
进入客户端进行目录创建
分布式创建server1.等并分别启动
3、Hadoop的高可用性
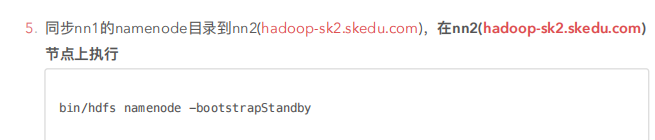
配置namenode的热备份及Hadoop的数据目录
启动各个节点,可以看到所属状态
节点升级,可以切换热备或活动节点为namenode
4、基于zk的故障自动转移高可用性Hadoop HA
zk内部选举一个active的namenode
NameNode主要负责管理元数据,DataNode主要负责存储文件块。NameNode来管理datanode与文件块的映射关系
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/15335844.html

