

java中的基本数据类型的转换
本文参考了如下两篇文章:
https://my.oschina.net/joymufeng/blog/139952
http://www.cnblogs.com/lwbqqyumidi/p/3700164.html
Java中,经常可以遇到类型转换的场景,从变量的定义到复制、数值变量的计算到方法的参数传递、基类与派生类间的造型等,随处可见类型转换的身影。Java中的类型转换在Java编码中具有重要的作用。
首先,来了解下数据类型的基本理解:数据是用来描述数据的种类,包括其值和基于其值基础上的可进行的操作集合。
Java中数据类型主要分为两大类:基本数据类型和引用数据类型。
基本数据类型共有8种,分别是:布尔型boolean, 字符型char和数值型byte/short/int/long/float/double。由于字符型char所表示的单个字符与Ascii码中相应整形对应,因此,有时也将其划分到数值型中。引用类型具体可分为:数组、类和接口。因此java中类型的转化分为基本数据类型的转换和引用数据类型的转换,本文将针对基本数据类型的转换进行总结.
1.基本数据类型的类型转换
| 数据类型 | 所占字节 |
| boolean | 未定 |
| byte | 1字节 |
| char | 2字节 |
| short | 2字节 |
| int | 4字节 |
| long | 8字节 |
| float | 4字节 |
| double | 8字节 |
从上表可以看出java中各种数据类型所占空间的大小. 在java中整数的默认数据类型是int, 例如数字4, 小数的默认数字类型是double, 例如3.12. 当float a = 3.12时会报错, 因为3.12的默认数据类型是double, 我们需要使用如下的赋值方法:
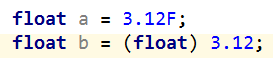
第一种方法在3.12后面加了一个F, 告诉编译器这是一个float的数. 第二种方法对3.12进行了强制的类型转换. 接下来我们仔细分析一下java中的类型转换问题.
基本数据类型中,布尔类型boolean占有一个字节,由于其本身所代码的特殊含义,boolean类型与其他基本类型不能进行类型的转换(既不能进行自动类型的提升,也不能强制类型转换), 否则,将编译出错。
a. 基本数据类型中类型的自动提升
数值类型在内存中直接存储其本身的值,对于不同的数值类型,内存中会分配相应的大小去存储。如:byte类型的变量占用8位,int类型变量占用32位等。相应的,不同的数值类型会有与其存储空间相匹配的取值范围。具体如下所示:

图中依次表示了各数值类型的字节数和相应的取值范围。在Java中,整数类型(byte/short/int/long)中,对于未声明数据类型的整形,其默认类型为int型。在浮点类型(float/double)中,对于未声明数据类型的浮点型,默认为double型。
看下面的例子

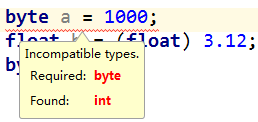
是不是有点奇怪?按照上面的思路去理解,将一个int型的1000赋给一个byte型的变量a,提示出错,但是最后一句:将一个int型的3赋给一个byte型的变量c,居然编译正确,这是为什么呢?
原因在于:jvm在编译过程中,对于默认为int类型的数值时,当赋给一个比int型数值范围小的数值类型变量(在此统一称为数值类型k,k可以是byte/char/short类型),会进行判断,如果此int型数值超过数值类型k,那么会直接编译出错。因为你将一个超过了范围的数值赋给类型为k的变量,k装不下嘛,你有没有进行强制类型转换,当然报错了。但是如果此int型数值尚在数值类型k范围内,jvm会自定进行一次隐式类型转换,将此int型数值转换成类型k。如图中的虚线箭头。这一点有点特别,需要稍微注意下。
另外在IDEA中, 类型的判断会在写程序时由编辑器帮你做判断, 而不需要到编译的时候由编译器来做判断, 这也是IDEA的一个优点.
在其他情况下,当将一个数值范围小的类型赋给一个数值范围大的数值型变量,jvm在编译过程中俊将此数值的类型进行了自动提升。在数值类型的自动类型提升过程中,数值精度至少不应该降低(整型保持不变,float->double精度将变高)。


如上:定义long类型的a变量时,将编译出错,原因在于11111111111默认是int类型,同时int类型的数值范围是-2^31 ~ 2^31-1,因此,11111111111已经超过此范围内的最大值,故而其自身已经编译出错,更谈不上赋值给long型变量a了。
此时,若想正确赋值,改变11111111111自身默认的类型即可,直接改成11111111111L即可将其自身类型定义为long型。此时再赋值编译正确。
将值为10的int型变量 z 赋值给long型变量q,按照上文所述,此时直接发生了自动类型提升, 编译正确。
接下来,还有一个地方需要注意的是:char型其本身是unsigned型,同时具有两个字节,其数值范围是0 ~ 2^16-1,这直接导致byte型不能自动类型提升到char,char和short直接也不会发生自动类型提升(因为负数的问题),同时,byte当然可以直接提升到short型。
b. 隐式类型转换
上面的例子中既有隐式类型转换, 也有强制类型转换, 那么什么是隐式类型转换呢?
隐式转换也叫作自动类型转换, 由系统自动完成.
从存储范围小的类型到存储范围大的类型.
byte ->short(char)->int->long->float->double
c. 显示类型转换
显示类型转换也叫作强制类型转换, 是从存储范围大的类型到存储范围小的类型.
当我们需要将数值范围较大的数值类型赋给数值范围较小的数值类型变量时,由于此时可能会丢失精度(1讲到的从int到k型的隐式转换除外),因此,需要人为进行转换。我们称之为强制类型转换。
double→float→long→int→short(char)→byte

byte a =3;编译正确在1中已经进行了解释。接下来将一个值为4的int型变量b赋值给byte型变量c,发生编译错误。这两种写法之间有什么区别呢?
区别在于前者3是直接量,编译期间可以直接进行判定,后者b为一变量,需要到运行期间才能确定,也就是说,编译期间为以防万一,当然不可能编译通过了。此时,需要进行强制类型转换。
强制类型转换所带来的结果是可能会丢失精度,如果此数值尚在范围较小的类型数值范围内,对于整型变量精度不变,但如果超出范围较小的类型数值范围内,很可能出现一些意外情况。
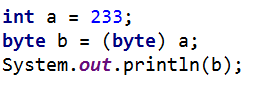
上面的例子中输出值是 -23.
为什么结果是-23?需要从最根本的二进制存储考虑。
233的二进制表示为:24位0 + 11101001,byte型只有8位,于是从高位开始舍弃,截断后剩下:11101001,由于二进制最高位1表示负数,0表示正数,其相应的负数为-23。
d. 进行数学运算时的数据类型自动提升与可能需要的强制类型转换
当进行数学运算时,数据类型会自动发生提升到运算符左右之较大者,以此类推。当将最后的运算结果赋值给指定的数值类型时,可能需要进行强制类型转换。例如:

a+b会自动提升为int, 因此在给c赋值的时候要强制转换成byte.
2.类型转换中的符号扩展Sign Extension
有没有想过这么一个问题, 当把一个byte的负数转换为int时, 它的值是正数还是负数呢? 当把一个int强制转为为byte, 我们能否确定转换后数字的符号呢? 要理解这两点, 我们首先要明白计算机中数的表示, 和java中类型转换时进行的操作.
a. 计算机中数的表示
计算机中的数都是以补码的形式存储的, 最高位是符号位. 正数的补码是它本身, 而负数的补码是原码按位取反后加1. 这样我们就很清楚java中这些数据类型的范围是怎么得到的.
例如: byte的范围是-128 ~ 127. 为什么会有-128呢? 其实-128的二进制表示是 10000000, 这个补码形式是不是很奇怪呢? 我们找不到一个数可以对应这样的补码, 其实这是-0的原码, 那-0的补码呢? 按位取反加1试试看, 是不是又变为00000000呢? 所以这个多出来的-0就用来表示-128了.
有了上面的表示, 我们就要问: 如何在类型扩展的时候保持数字的符号和值不变呢?
b. java中的符号扩展
1) 什么是符号扩展
符号扩展(Sign Extension)用于在数值类型转换时扩展二进制位的长度,以保证转换后的数值和原数值的符号(正或负)和大小相同,一般用于较窄的类型(如byte)向较宽的类型(如int)转换。扩展二进制位长度指的是,在原数值的二进制位左边补齐若干个符号位(0表示正,1表示负)。
举例来说,如果用6个bit表示十进制数10,二进制码为"00 1010",如果将它进行符号扩展为16bits长度,结果是"0000 0000 0000 1010",即在左边补上10个0(因为10是正数,符号为0),符号扩展前后数值的大小和符号都保持不变;如果用10bits表示十进制数-15,使用“2的补码”编码后,二进制码为"11 1111 0001",如果将它进行符号扩展为16bits,结果是"1111 1111 1111 0001",即在左边补上6个1(因为-15是负数,符号为1),符号扩展前后数值的大小和符号都保持不变。
2) java中数值类型转换的规则
这个规则是《Java解惑》总结的:如果最初的数值类型是有符号的,那么就执行符号扩展;如果是char类型,那么不管它要被转换成什么类型,都执行零扩展。还有另外一条规则也需要记住,如果目标类型的长度小于源类型的长度,则直接截取目标类型的长度。例如将int型转换成byte型,直接截取int型的右边8位。
所以java在进行类型扩展时候会根据原始数据类型, 来执行符号扩展还是零扩展. 数值类型转数值类型的符号扩展不会改变值的符号和大小.
c. 解析“多重转型”问题
一个连续三次类型转换的表达式如下:
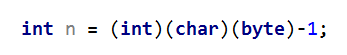
1. int(32位) -> byte(8位)
-1是int型的字面量,根据“2的补码”编码规则,编码结果为0xffffffff,即32位全部置1.转换成byte类型时,直接截取最后8位,所以byte结果为0xff,对应的十进制值是-1.
2. byte(8位) -> char(16位)
由于byte是有符号类型,所以在转换成char型(16位)时需要进行符号扩展,即在0xff左边连续补上8个1(1是0xff的符号位),结果是0xffff。由于char是无符号类型,所以0xffff表示的十进制数是65535。
3. char(16位) -> int(32位)
由于char是无符号类型,转换成int型时进行零扩展,即在0xffff左边连续补上16个0,结果是0x0000ffff,对应的十进制数是65535。
d. 几个转型的例子
在进行类型转换时,一定要了解表达式的含义,不能光靠感觉。最好的方法是将你的意图明确表达出来。
在将一个char型数值c转型为一个宽度更宽的类型时,并且不希望有符号扩展,可以如下编码:
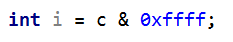
上文曾提到过,0xffff是int型字面量,所以在进行&操作之前,编译器会自动将c转型成int型,即在c的二进制编码前添加16个0,然后再和0xffff进行&操作,所表达的意图是强制将前16置0,后16位保持不变。虽然这个操作不是必须的,但是明确表达了不进行符号扩展的意图。
如果需要符号扩展,则可以如下编码:

首先将c转换成short类型,它和char是 等宽度的,并且是有符号类型,再将short类型转换成int类型时,会自动进行符号扩展,即如果short为负数,则在左边补上16个1,否则补上16个0.
如果在将一个byte数值b转型为一个char时,并且不希望有符号扩展,那么必须使用一个位掩码来限制它:

(b & 0xff)的结果是32位的int类型,前24被强制置0,后8位保持不变,然后转换成char型时,直接截取后16位。这样不管b是正数还是负数,转换成char时,都相当于是在左边补上8个0,即进行零扩展而不是符号扩展。
如果需要符号扩展,则编码如下:

此时为了明确表达需要符号扩展的意图,注释是必须的。
e.总结
实际上在数值类型转换时,只有当遇到负数时才会出现问题,根本原因就是Java中的负数不是采用直观的方式进行编码,而是采用“2的补码”方式,这样的好处是加法和减法操作可以同时使用加法电路完成,但是在开发时却会遇到很多奇怪的问题,例如(byte)128的结果是-128,即一个大的正数,截断后却变成了负数。3.2节中引用了一些转型规则,应用这些规则可以很容地解决常见的转型问题。
参考引用
1. 阮一峰-关于2的补码
http://www.ruanyifeng.com/blog/2009/08/twos_complement.html
2. wikipedia-Sign extension
http://en.wikipedia.org/wiki/Sign_extension
3. Joshua Bloch, 陈昊鹏译 - 《Java解惑》
