

python读取CSV文件
python中有一个读写csv文件的包,直接import csv即可。利用这个python包可以很方便对csv文件进行操作,一些简单的用法如下。
1. 读文件
csv_reader = csv.reader(open('data.file', encoding='utf-8'))
for row in csv_reader:
print(row)
例如有如下的文件
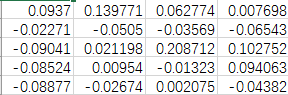
输出结果如下
['0.093700','0.139771','0.062774','0.007698']
['-0.022711','-0.050504','-0.035691','-0.065434']
['-0.090407','0.021198','0.208712','0.102752']
['-0.085235','0.009540','-0.013228','0.094063']
可见csv_reader把每一行数据转化成了一个list,list中每个元素是一个字符串。
2. 写文件
读文件时,我们把csv文件读入列表中,写文件时会把列表中的元素写入到csv文件中。
list = ['1', '2','3','4']
out = open(outfile, 'w') csv_writer = csv.writer(out) csv_writer.writerow(list)
可能遇到的问题:直接使用这种写法会导致文件每一行后面会多一个空行。
解决办法如下:
out = open(outfile, 'w', newline='') csv_writer = csv.writer(out, dialect='excel') csv_writer.writerow(list)
参考如下:
在stackoverflow上找到了比较经典的解释,原来 python3里面对 str和bytes类型做了严格的区分,不像python2里面某些函数里可以混用。所以用python3来写wirterow时,打开文件不要用wb模式,只需要使用w模式,然后带上newline=''。
|
In Python 2.X, it was required to open the csvfile with 'b' because the csv module does its own line termination handling. In Python 3.X, the csv module still does its own line termination handling, but still needs to know an encoding for Unicode strings. The correct way to open a csv file for writing is:
|


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗