
Linux 中根据某一列的内容拆分文件(指定列内容重复的保存为一个文件,先生成唯一的文件名)
001、

[root@PC1 test2]# ls a.txt [root@PC1 test2]# cat a.txt 01 aa 02 03 04 aa 05 06 07 bb 08 09 10 bb 11 12 13 aa 14 15 16 bb 17 18 19 cc 20 21 22 cc 23 24 25 bb 26 27 28 ee 30 [root@PC1 test2]# awk '{OFS = "\t"; if(!($2 in ay1)) {ay1[$2]++; tmp = $2}; if($2 in ay1 && tmp != $2) {ay1[$2]++};tmp = $2; $2 = ay1[$2]"_"$2; print $0}' a.txt 01 1_aa 02 03 04 1_aa 05 06 07 1_bb 08 09 10 1_bb 11 12 13 2_aa 14 15 16 2_bb 17 18 19 1_cc 20 21 22 1_cc 23 24 25 3_bb 26 27 28 1_ee 30
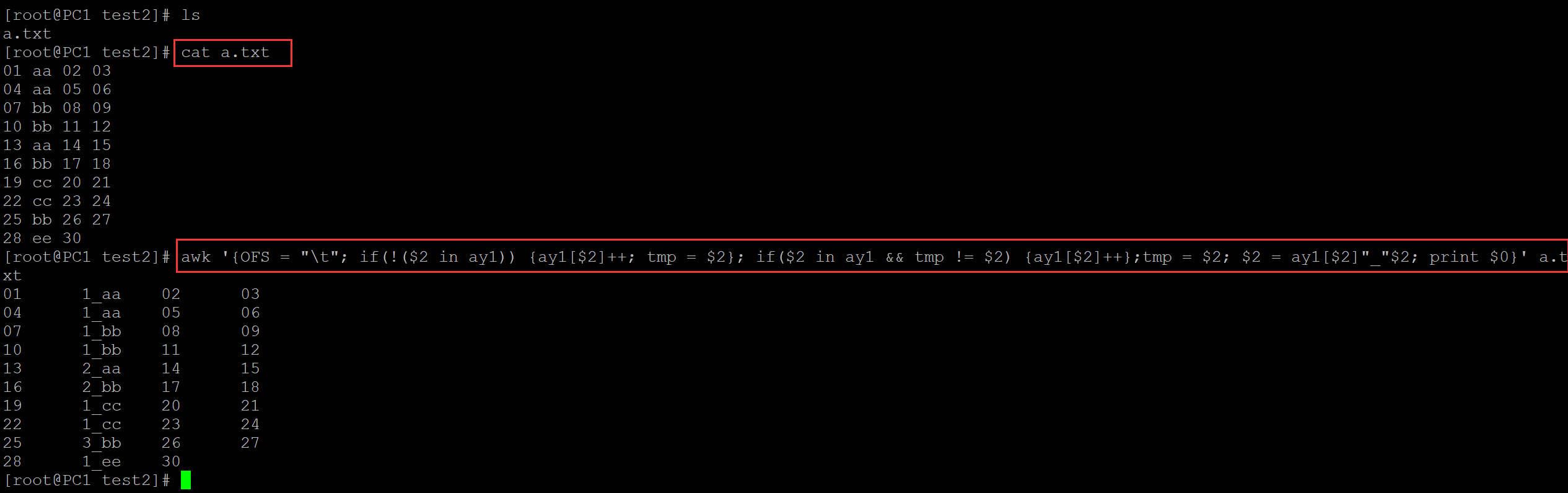
。
002、
[root@PC1 test2]# ls a.txt [root@PC1 test2]# cat a.txt 01 aa 02 03 04 aa 05 06 07 bb 08 09 10 bb 11 12 13 aa 14 15 16 bb 17 18 19 cc 20 21 22 cc 23 24 25 bb 26 27 28 ee 30 [root@PC1 test2]# awk 'BEGIN{tmp = 0}{if($2 != tmp) {count++}; tmp = $2; $2 = count"_"$2; print $0 }' a.txt 01 1_aa 02 03 04 1_aa 05 06 07 2_bb 08 09 10 2_bb 11 12 13 3_aa 14 15 16 4_bb 17 18 19 5_cc 20 21 22 5_cc 23 24 25 6_bb 26 27 28 7_ee 30
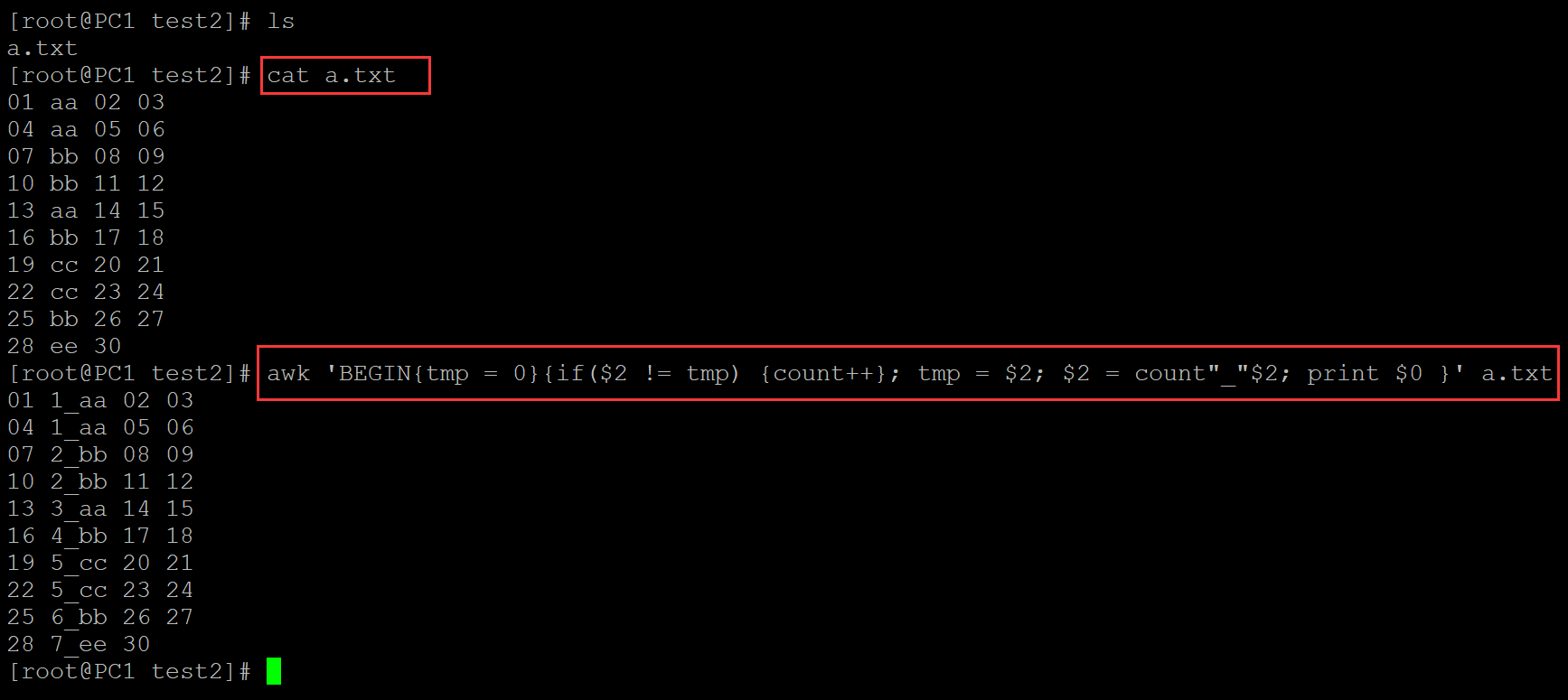
。
分类:
linux shell



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2023-06-06 python中实现提取碱基序列的互补序列
2023-06-06 linux中实现提取碱基序列的互补序列
2023-06-06 python中同时指定多个分隔符将字符串拆分为列表
2023-06-06 python启动状态下查看版本
2022-06-06 python中如何删除字典中的元素
2022-06-06 python中实现字典的合并
2022-06-06 R语言中which.max、which.min函数,返回最大值和最小值的索引