
linux 中 awk 之 sub、gsub、substr、index、match函数的用法
001、awk中sub函数的用法:sub用于替换,其语法如下:
a、

[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试数据 abcdxabcd abcd xyz qmn opqriytyx abcd uny een abcdkabcd eabc abc abc [root@pc1 test1]# awk '{sub("abc", "QQQ", $0); print $0}' a.txt ## 替换对象是整个记录(一行);替换每行匹配的第一个 QQQdxabcd abcd xyz qmn ## 顺序依次是匹配内容,替换内容和替换对象 opqriytyx QQQd uny een QQQdkabcd eabc abc abc
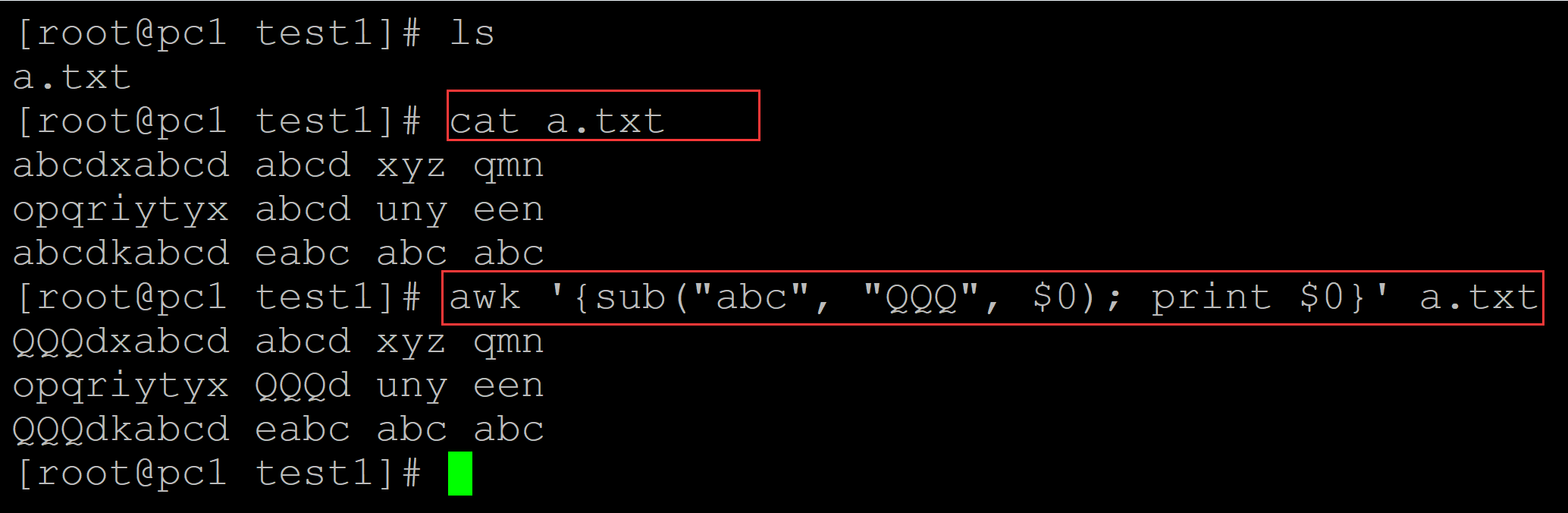
b、替换对象也可以是单独的一个字段,比如第一个字段$1;
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试数据 abcdxabcd abcd xyz qmn opqriytyx abcd uny een abcdkabcd eabc abc abc [root@pc1 test1]# awk '{sub("abc", "QQQ", $1); print $0}' a.txt ## 限定匹配字段为第一个字段 QQQdxabcd abcd xyz qmn opqriytyx abcd uny een QQQdkabcd eabc abc abc
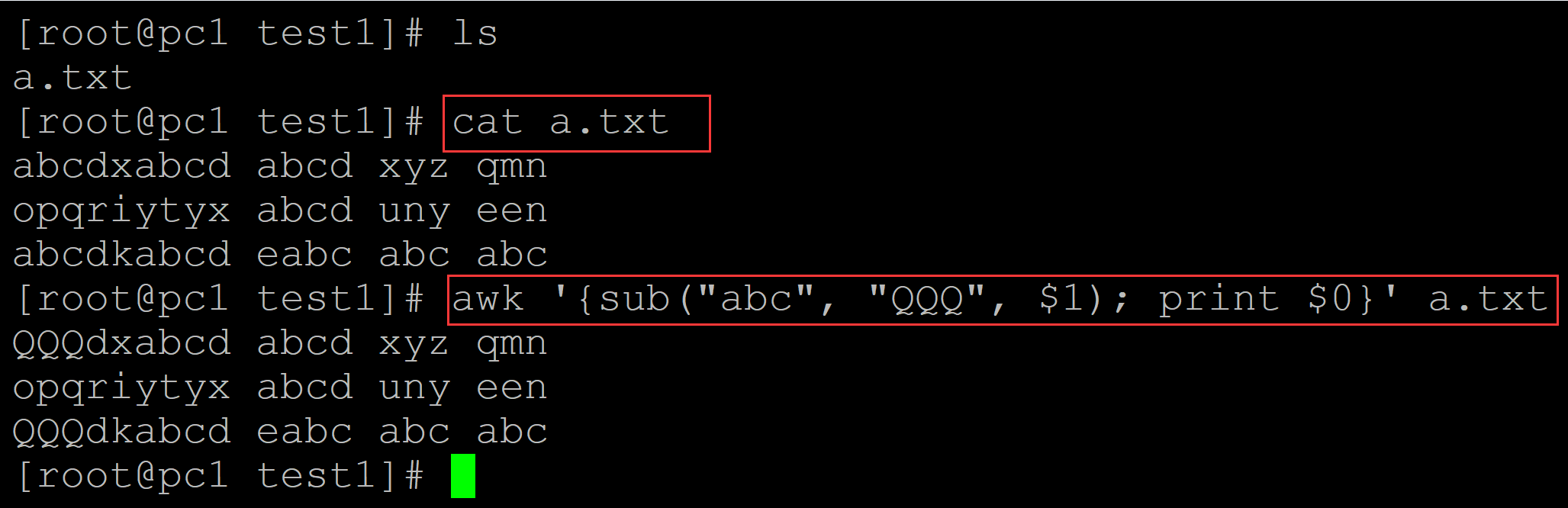
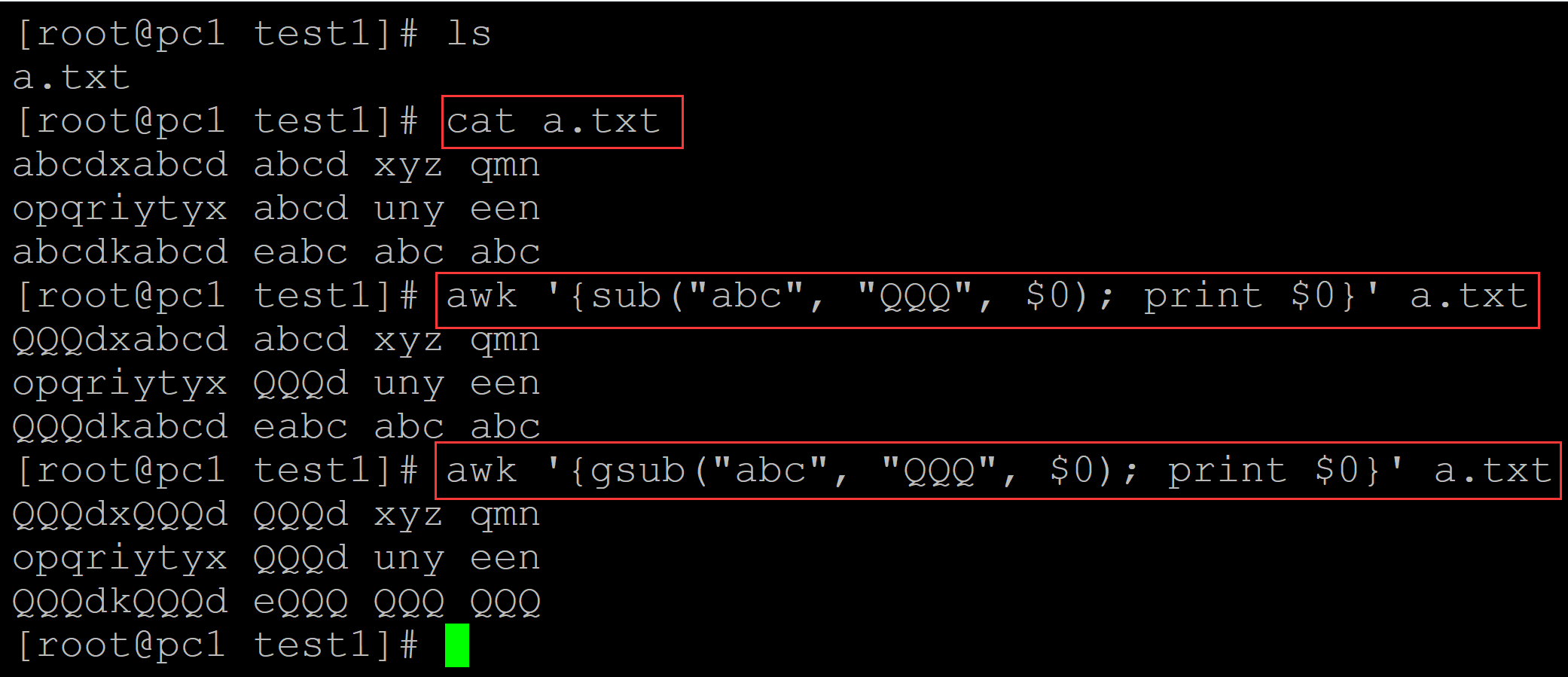
002、gsub: gsub和sub的区别就是gsub替换的是整行的所有匹配内容,而sub替换的是匹配的第一个,示例如下:
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试数据 abcdxabcd abcd xyz qmn opqriytyx abcd uny een abcdkabcd eabc abc abc [root@pc1 test1]# awk '{sub("abc", "QQQ", $0); print $0}' a.txt ## sub替换效果 QQQdxabcd abcd xyz qmn opqriytyx QQQd uny een QQQdkabcd eabc abc abc [root@pc1 test1]# awk '{gsub("abc", "QQQ", $0); print $0}' a.txt ## gsub替换效果 QQQdxQQQd QQQd xyz qmn opqriytyx QQQd uny een QQQdkQQQd eQQQ QQQ QQQ
003、awk的substr函数的用法:
substr在awk中用于截取字符串,示例如下:
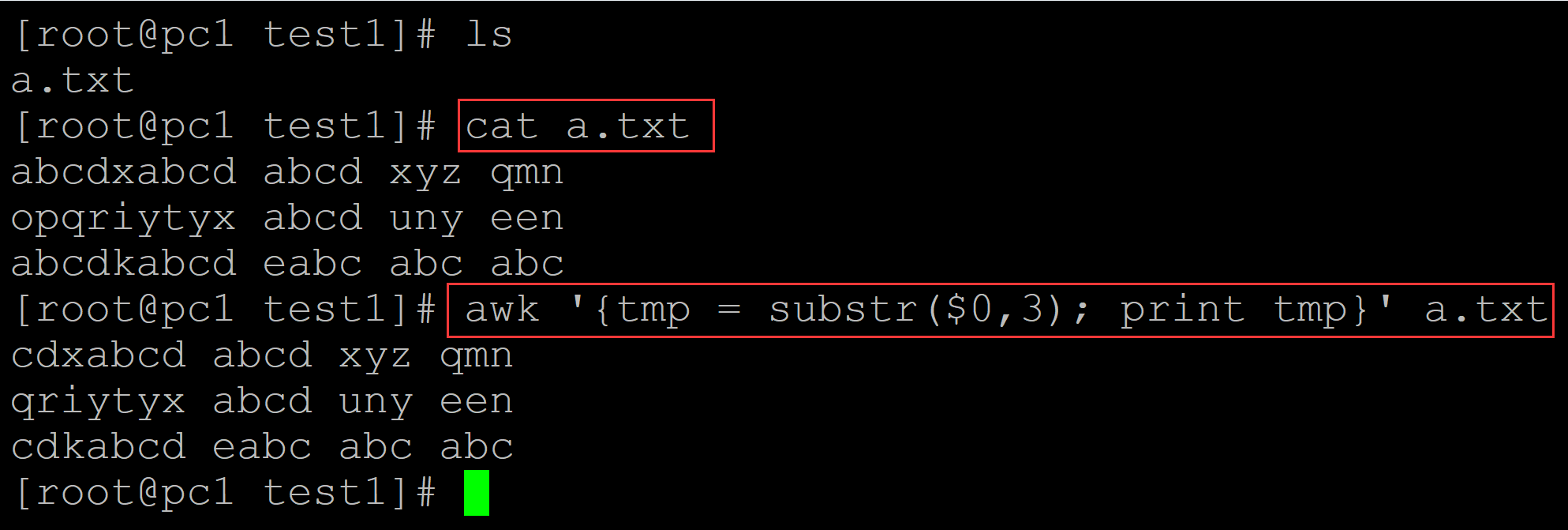
a、
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试数据 abcdxabcd abcd xyz qmn opqriytyx abcd uny een abcdkabcd eabc abc abc [root@pc1 test1]# awk '{tmp = substr($0,3); print tmp}' a.txt cdxabcd abcd xyz qmn ## 从整个字段的第三个字符开始截取,一直到整个字段最后 qriytyx abcd uny een cdkabcd eabc abc abc
b、
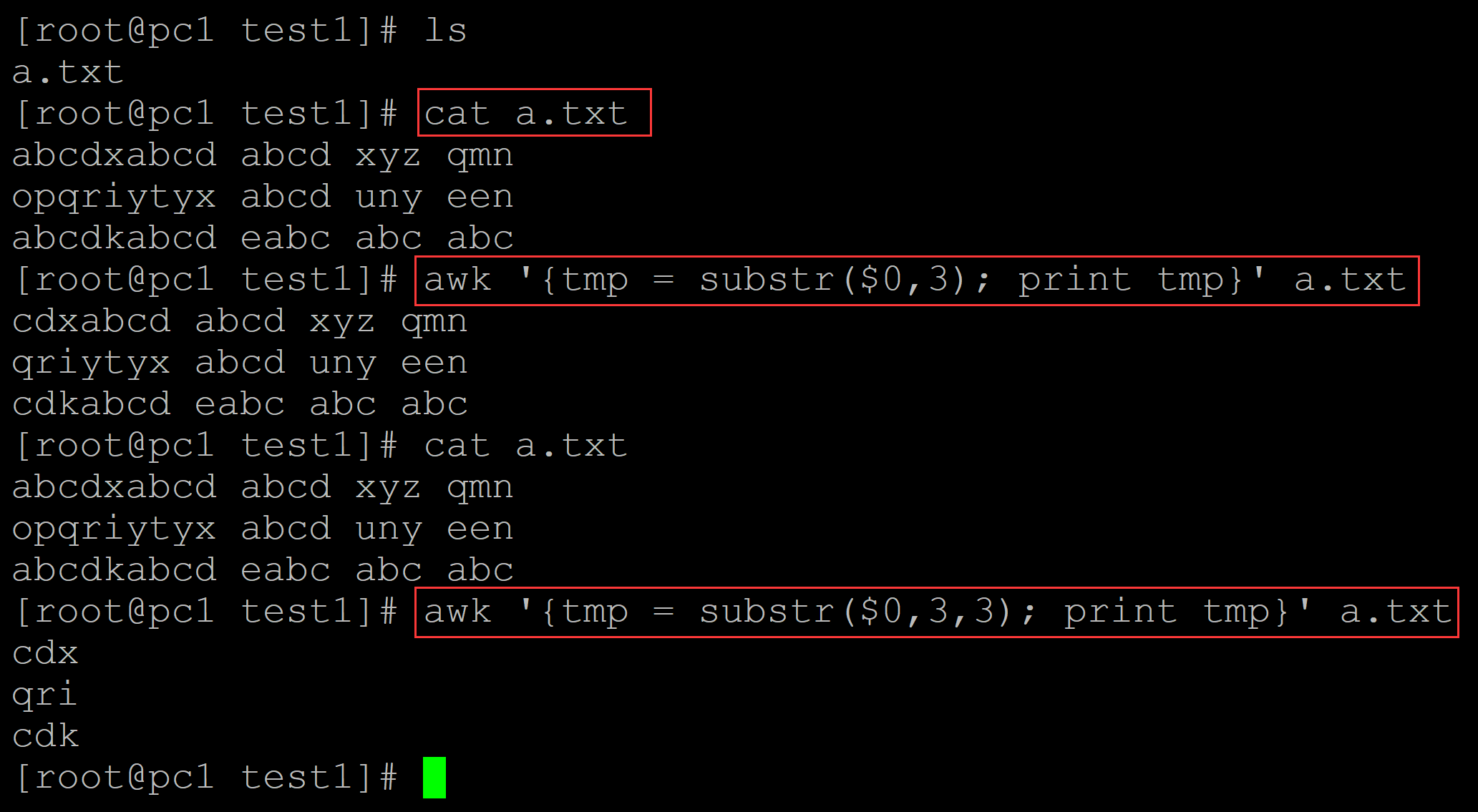
除了可以指定字符截取的起点,也可以指定字符向后截取的范围,如下:
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试文本 abcdxabcd abcd xyz qmn opqriytyx abcd uny een abcdkabcd eabc abc abc [root@pc1 test1]# awk '{tmp = substr($0,3); print tmp}' a.txt ## 从第三个字符开始截取,不限制范围 cdxabcd abcd xyz qmn qriytyx abcd uny een cdkabcd eabc abc abc [root@pc1 test1]# cat a.txt abcdxabcd abcd xyz qmn opqriytyx abcd uny een abcdkabcd eabc abc abc [root@pc1 test1]# awk '{tmp = substr($0,3,3); print tmp}' a.txt ## 从第三个字符截取,限制范围(向后截取3个) cdx qri cdk
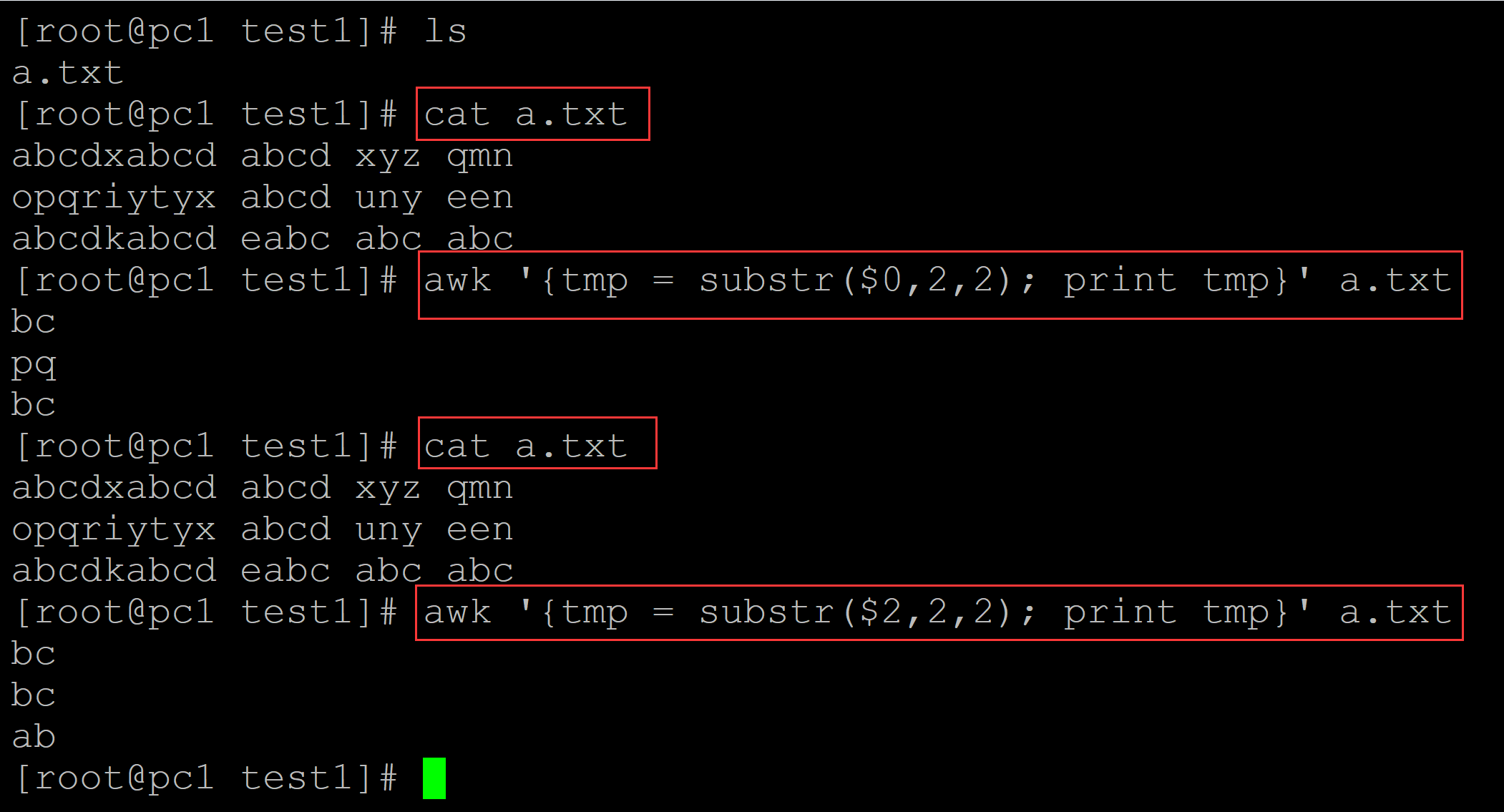
b、substr截取也可以指定不同的字段,示例如下:
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试数据 abcdxabcd abcd xyz qmn opqriytyx abcd uny een abcdkabcd eabc abc abc [root@pc1 test1]# awk '{tmp = substr($0,2,2); print tmp}' a.txt bc ## 整个字段截取 pq bc [root@pc1 test1]# cat a.txt abcdxabcd abcd xyz qmn opqriytyx abcd uny een abcdkabcd eabc abc abc [root@pc1 test1]# awk '{tmp = substr($2,2,2); print tmp}' a.txt bc ## 限定第二个字段截取 bc ab
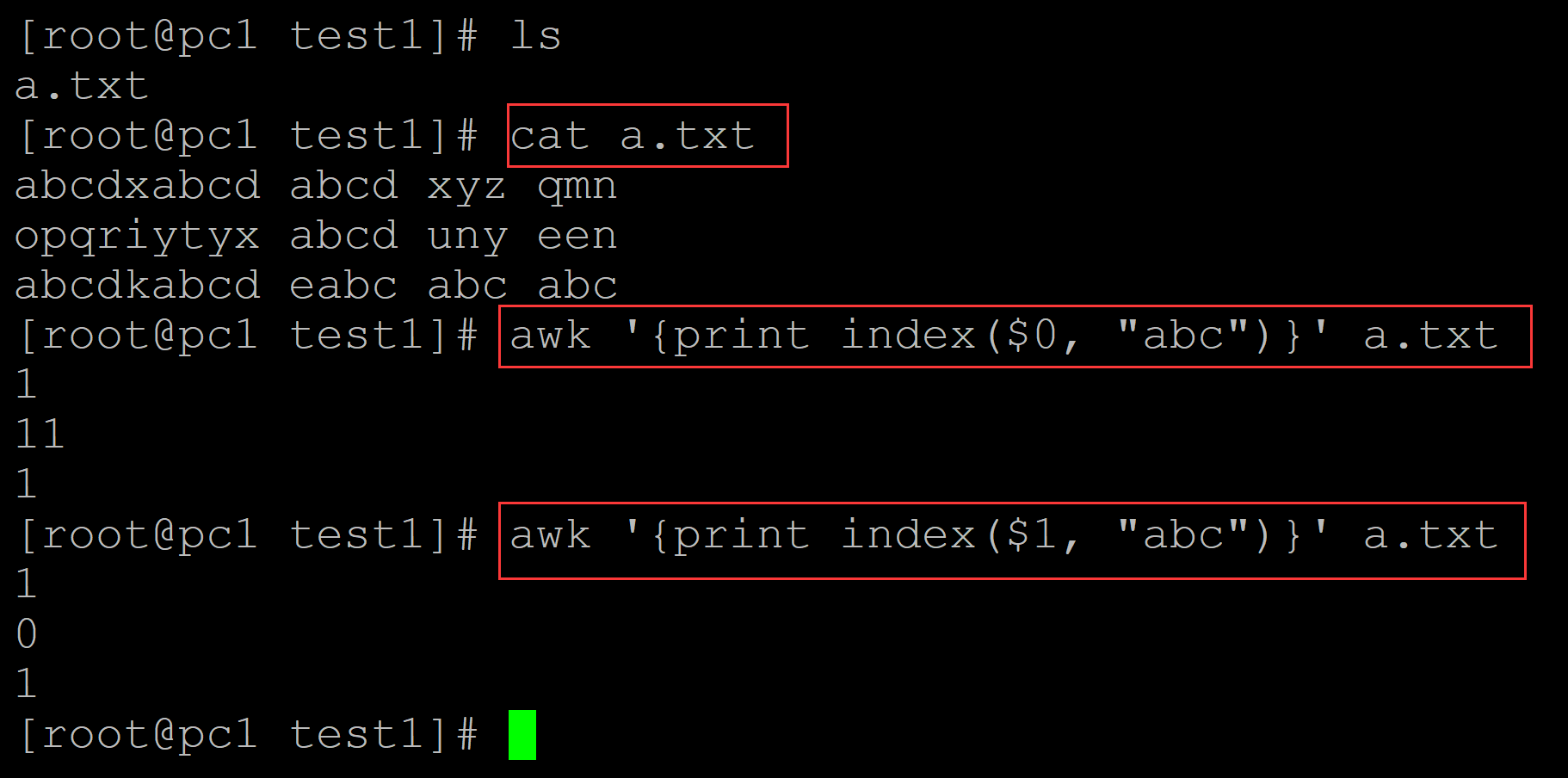
004、awk中index函数用于返回匹配字符串的索引,用法如下:
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试文本 abcdxabcd abcd xyz qmn opqriytyx abcd uny een abcdkabcd eabc abc abc [root@pc1 test1]# awk '{print index($0, "abc")}' a.txt 1 ## 在整个字段中进行匹配,返回匹配到的第一个字符的索引 11 1 [root@pc1 test1]# awk '{print index($1, "abc")}' a.txt 1 ## 同理可以限制匹配的字段,这里限制在第一个字段中匹配;0表示没有匹配到 0 1
005、awk中match函数的用法
a、就匹配而言,match的用法和index的用法一致,如下:
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试数据 abcdxabcd abcd xyz qmn opqriytyx abcd uny een abcdkabcd eabc abc abc [root@pc1 test1]# awk '{print match($0, "abc")}' a.txt 1 11 1 [root@pc1 test1]# awk '{print index($0, "abc")}' a.txt 1 ## match和index的效果一致 11 1 [root@pc1 test1]# awk '{print match($1, "abc")}' a.txt 1 0 1 [root@pc1 test1]# awk '{print index($1, "abc")}' a.txt 1 ## match和index的效果一致 0 1

b、match和index的区别
I、
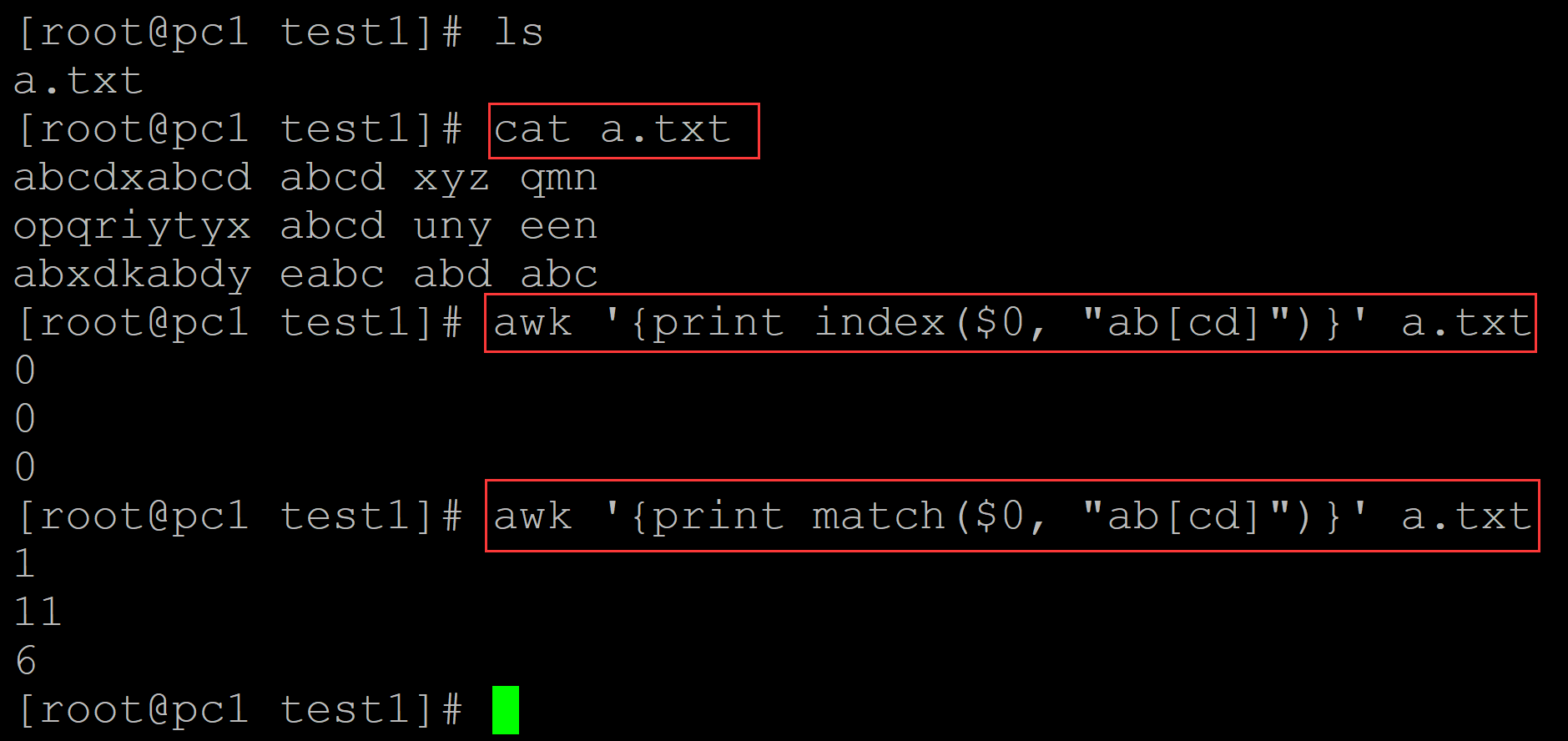
区别:index匹配的是字符串,match匹配的是正则表达式;
也就是说index函数的第二个参数时字符串; match的第二个参数时正则表达式;
可以用以下示例说明:
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试数据 abcdxabcd abcd xyz qmn opqriytyx abcd uny een abxdkabdy eabc abd abc [root@pc1 test1]# awk '{print index($0, "ab[cd]")}' a.txt 0 ## index默认第二个参数时字符串,因为无法匹配到,均返回0,表示没有匹配到 0 0 [root@pc1 test1]# awk '{print match($0, "ab[cd]")}' a.txt 1 ## match默认第二个参数时正则表达式,表示可以同时匹配到abc或者abd,并返回匹配索引 11 6
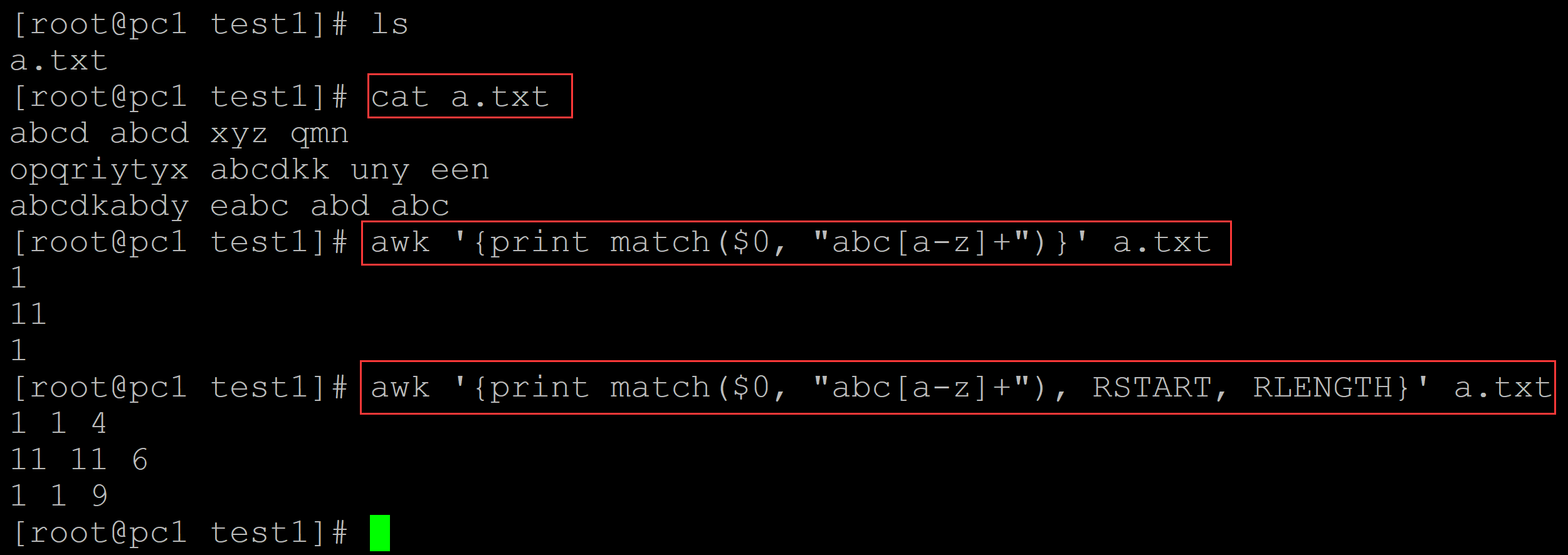
II、match匹配有两个内置变量,RSTART和RLENGTH,前者是匹配的索引,后者是匹配的长度,示例如下:
[root@pc1 test1]# ls a.txt [root@pc1 test1]# cat a.txt ## 测试数据 abcd abcd xyz qmn opqriytyx abcdkk uny een abcdkabdy eabc abd abc [root@pc1 test1]# awk '{print match($0, "abc[a-z]+")}' a.txt 1 ## match第二个参数正则表达式表示的是匹配abc后任意小写字母一次或多次 11 1 [root@pc1 test1]# awk '{print match($0, "abc[a-z]+"), RSTART, RLENGTH}' a.txt 1 1 4 ## RSTAT变量表示匹配的索引,因此1、2列相同,RLENGTH表示匹配的长度,第一行匹配到第一个字段 11 11 6 ## 长度为4,第二行匹配到第二个字段,长度为6,第三行匹配到第一个字段,长度为9 1 1 9
。
分类:
linux shell



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2021-02-23 python中实现列表倒序排列
2021-02-23 python中如何清空列表
2021-02-23 python中提取列表的奇数元素和偶数元素
2021-02-23 python中如何提取列表的前几个元素和后几个元素