
Linux 中shell脚本实现给fasta文件中重复的染色体名做序号标记
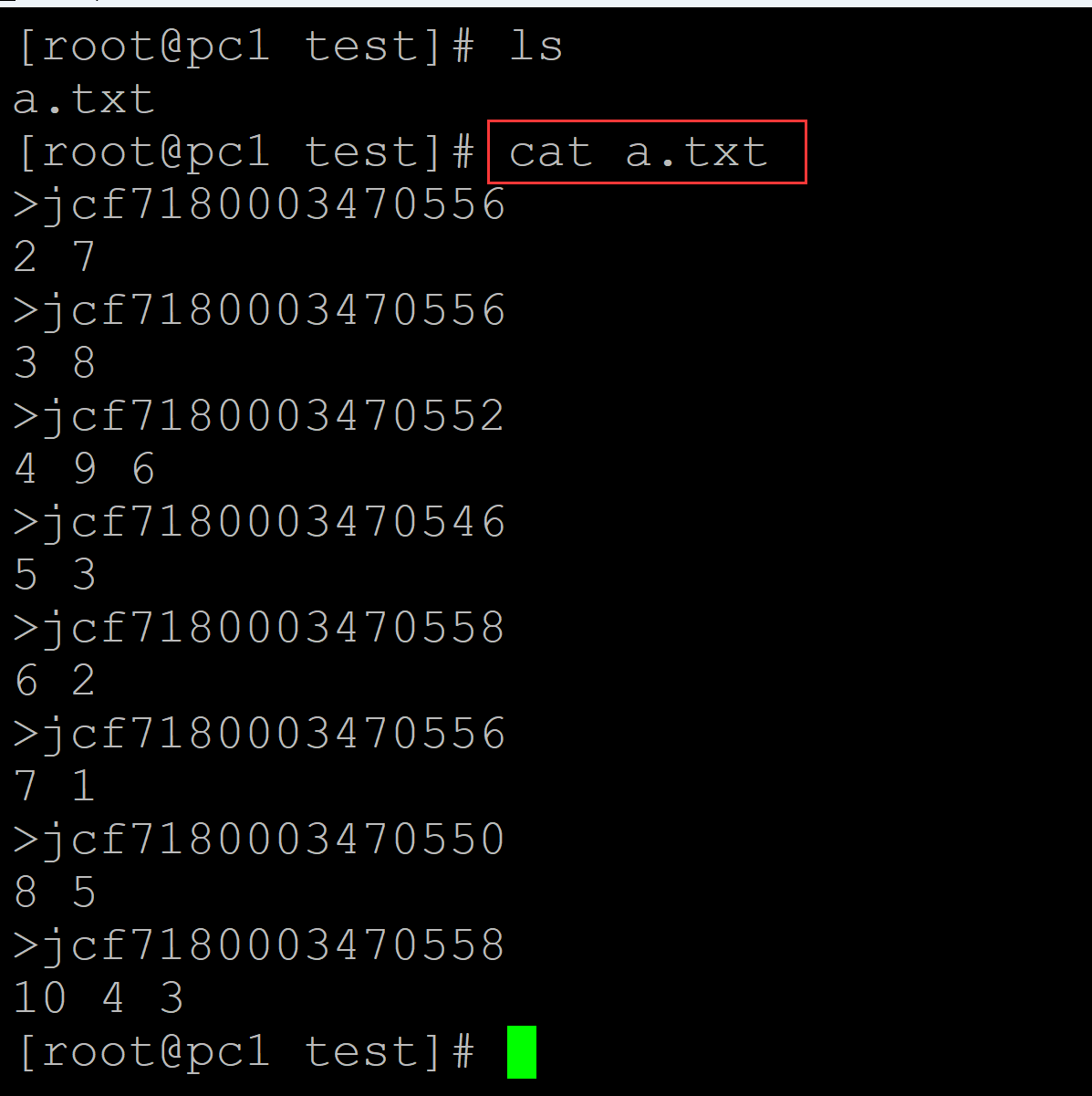
001、测试数据

[root@pc1 test]# ls a.txt [root@pc1 test]# cat a.txt ## 测试数据 >jcf7180003470556 2 7 >jcf7180003470556 3 8 >jcf7180003470552 4 9 6 >jcf7180003470546 5 3 >jcf7180003470558 6 2 >jcf7180003470556 7 1 >jcf7180003470550 8 5 >jcf7180003470558 10 4 3
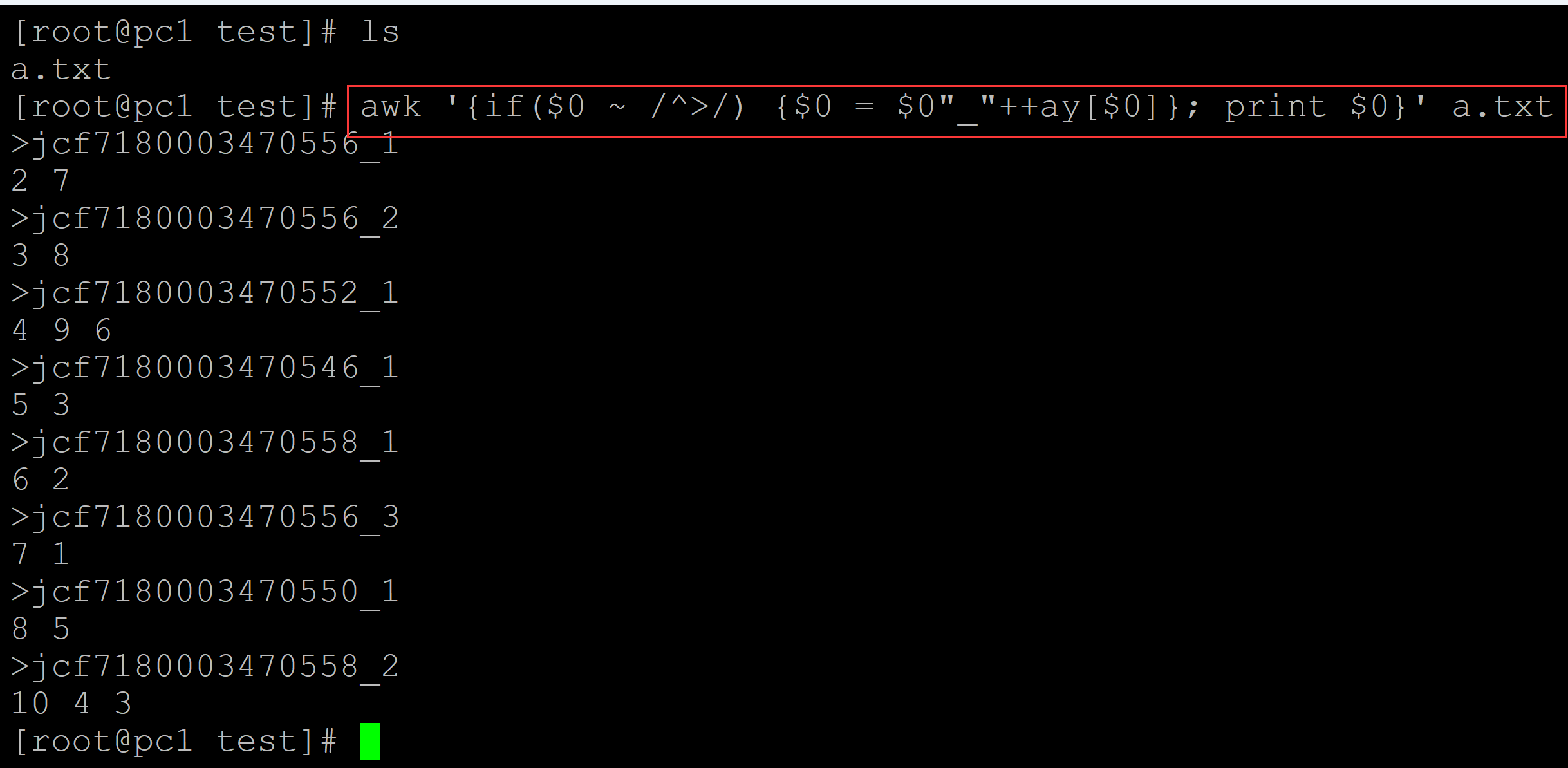
给重复的染色体名做标记:
[root@pc1 test]# awk '{if($0 ~ /^>/) {$0 = $0"_"++ay[$0]}; print $0}' a.txt ## 在末尾追加重复的次数 >jcf7180003470556_1 2 7 >jcf7180003470556_2 3 8 >jcf7180003470552_1 4 9 6 >jcf7180003470546_1 5 3 >jcf7180003470558_1 6 2 >jcf7180003470556_3 7 1 >jcf7180003470550_1 8 5 >jcf7180003470558_2 10 4 3
。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2021-11-17 R语言中如何清除向量中的NA、返回非NA的索引、返回指定项的索引