
linux 中根据指定列的重复或者唯一输出文本
001、 输出第一列中没有重复的文本

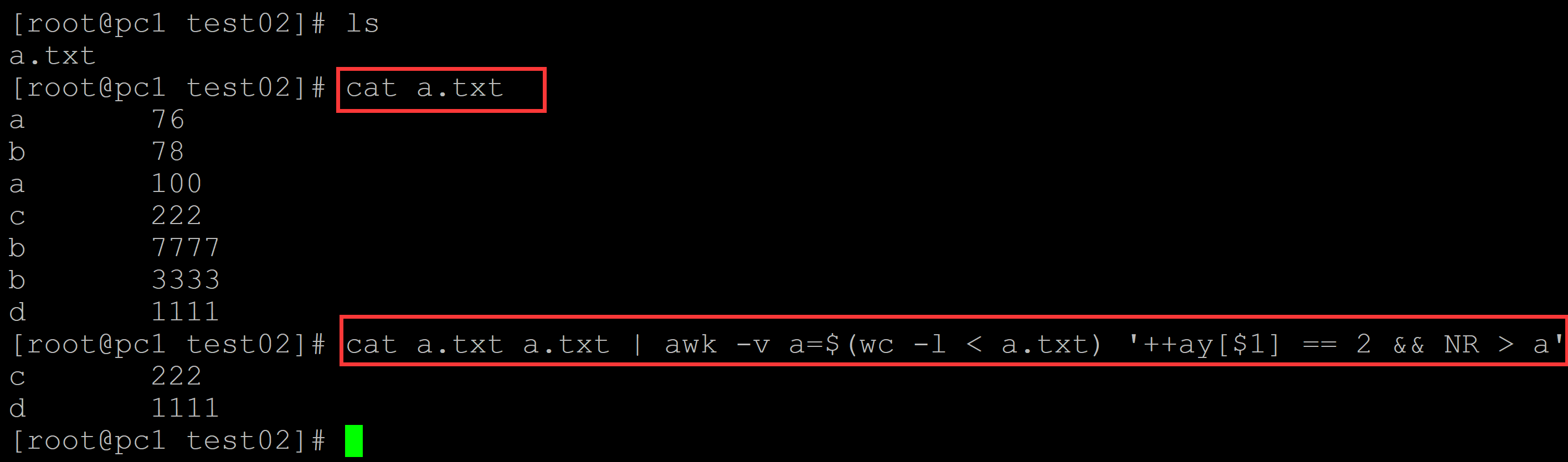
[root@pc1 test02]# ls a.txt [root@pc1 test02]# cat a.txt ## 测试数据 a 76 b 78 a 100 c 222 b 7777 b 3333 d 1111 ## 先把文本叠加一次, 然后引入文本行数变量; 如果重复多次,在叠加后的文本的后半部分,计数最少是3开始,依据此进行过滤 [root@pc1 test02]# cat a.txt a.txt | awk -v a=$(wc -l < a.txt) '++ay[$1] == 2 && NR > a' c 222 d 1111
002、输出指定列有重复的文本
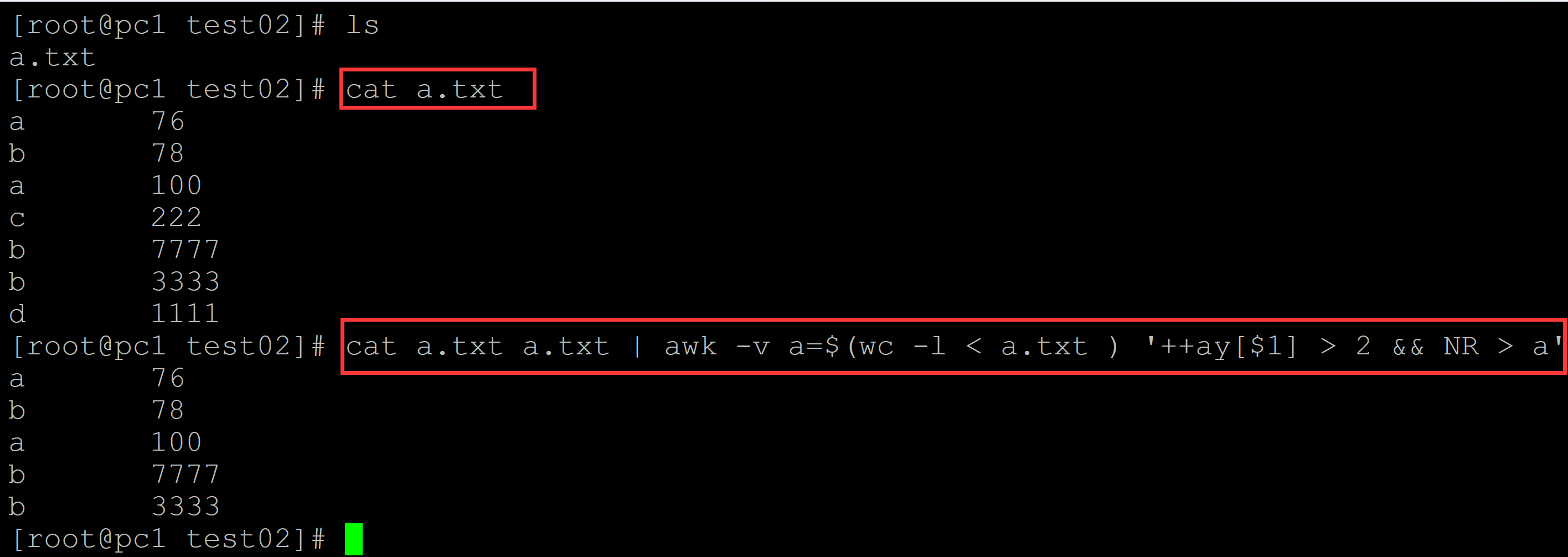
[root@pc1 test02]# ls a.txt [root@pc1 test02]# cat a.txt ## 测试数据 a 76 b 78 a 100 c 222 b 7777 b 3333 d 1111 ## 先把文本叠加一次; 然后记录文本行数; 在叠加后的文本的后半部分,最低的计数是3,据此提取重复 [root@pc1 test02]# cat a.txt a.txt | awk -v a=$(wc -l < a.txt ) '++ay[$1] > 2 && NR > a' a 76 b 78 a 100 b 7777 b 3333
。
分类:
linux shell



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2021-10-23 R脚本中使用命令行 进行传参
2021-10-23 Bareword "mp4" not allowed while "strict subs" in use at (user-supplied code). ubuntu
2021-10-23 Package libxml-2.0 was not found in the pkg-config search path
2021-10-23 Package libcurl was not found in the pkg-config search path.
2021-10-23 linux系统中目录和普通文件无法使用颜色区分解决方法
2021-10-23 ll: command not found
2020-10-23 linux系统中du命令