
linux 中实现批量抽取指定的行
001、测试数据

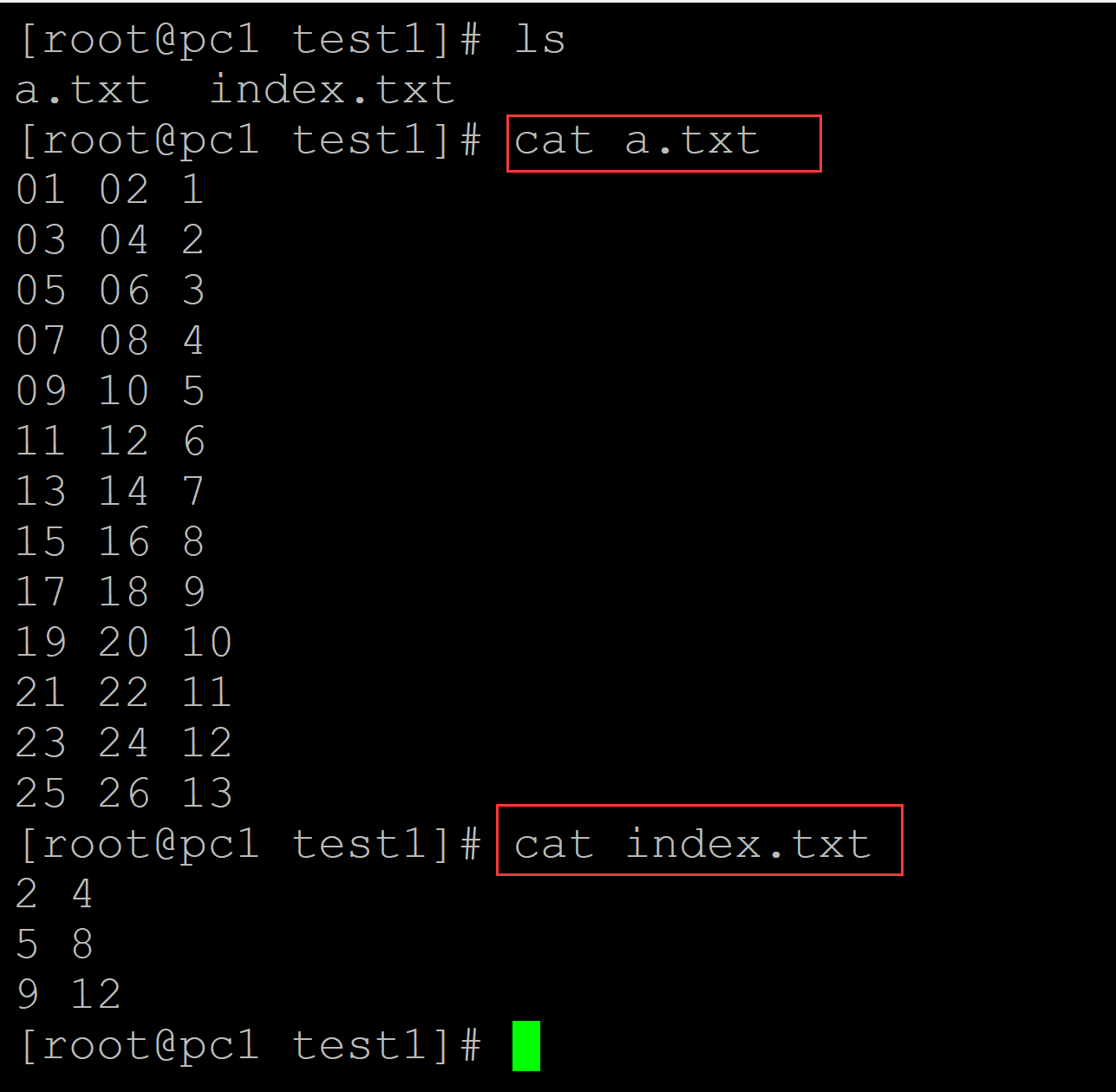
[root@pc1 test1]# ls a.txt index.txt [root@pc1 test1]# cat a.txt ## 测试文件 01 02 1 03 04 2 05 06 3 07 08 4 09 10 5 11 12 6 13 14 7 15 16 8 17 18 9 19 20 10 21 22 11 23 24 12 25 26 13 [root@pc1 test1]# cat index.txt ## 抽取索引 2 4 5 8 9 12
002、方法1 借助循环 + sed实现
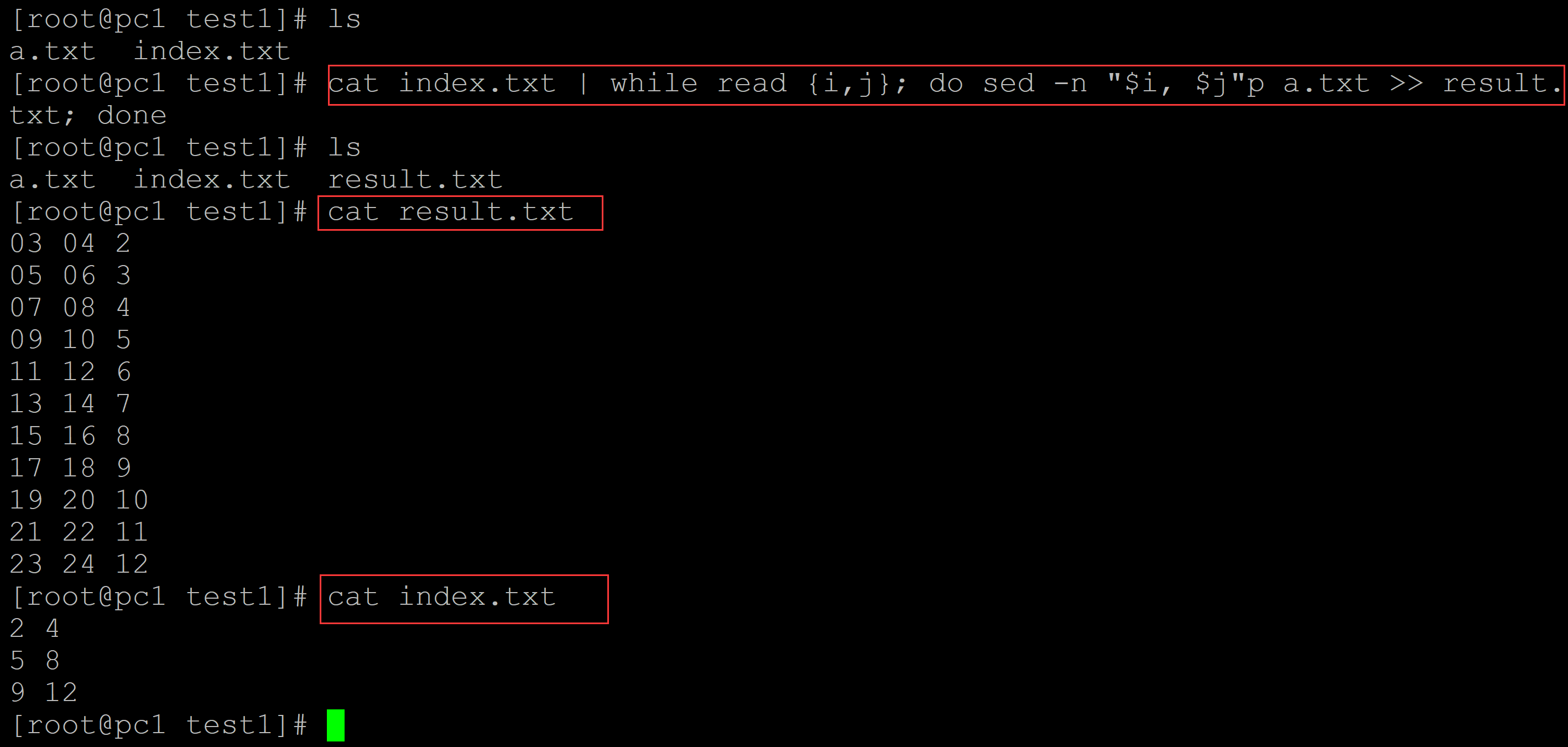
[root@pc1 test1]# ls a.txt index.txt ## 批量抽取 [root@pc1 test1]# cat index.txt | while read {i,j}; do sed -n "$i, $j"p a.txt >> result.txt; done [root@pc1 test1]# ls a.txt index.txt result.txt [root@pc1 test1]# cat result.txt ## 结果文件 03 04 2 05 06 3 07 08 4 09 10 5 11 12 6 13 14 7 15 16 8 17 18 9 19 20 10 21 22 11 23 24 12 [root@pc1 test1]# cat index.txt ## 索引行 2 4 5 8 9 12
003、方法2 循环 + awk实现
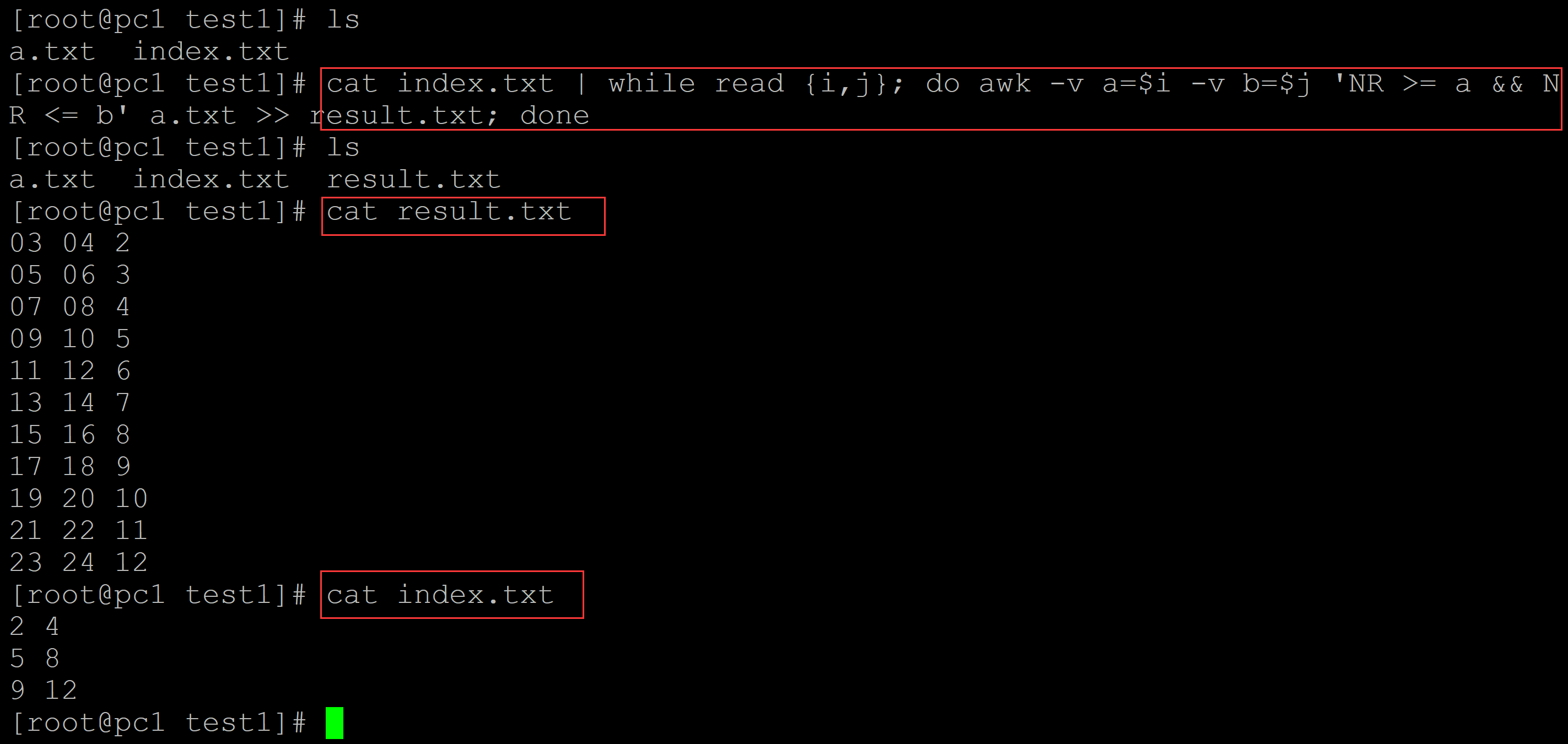
[root@pc1 test1]# ls a.txt index.txt ## 循环 + awk实现 [root@pc1 test1]# cat index.txt | while read {i,j}; do awk -v a=$i -v b=$j 'NR >= a && NR <= b' a.txt >> result.txt; done [root@pc1 test1]# ls a.txt index.txt result.txt [root@pc1 test1]# cat result.txt ## 结果文件 03 04 2 05 06 3 07 08 4 09 10 5 11 12 6 13 14 7 15 16 8 17 18 9 19 20 10 21 22 11 23 24 12 [root@pc1 test1]# cat index.txt ## 索引文件 2 4 5 8 9 12
004、方法3
a、
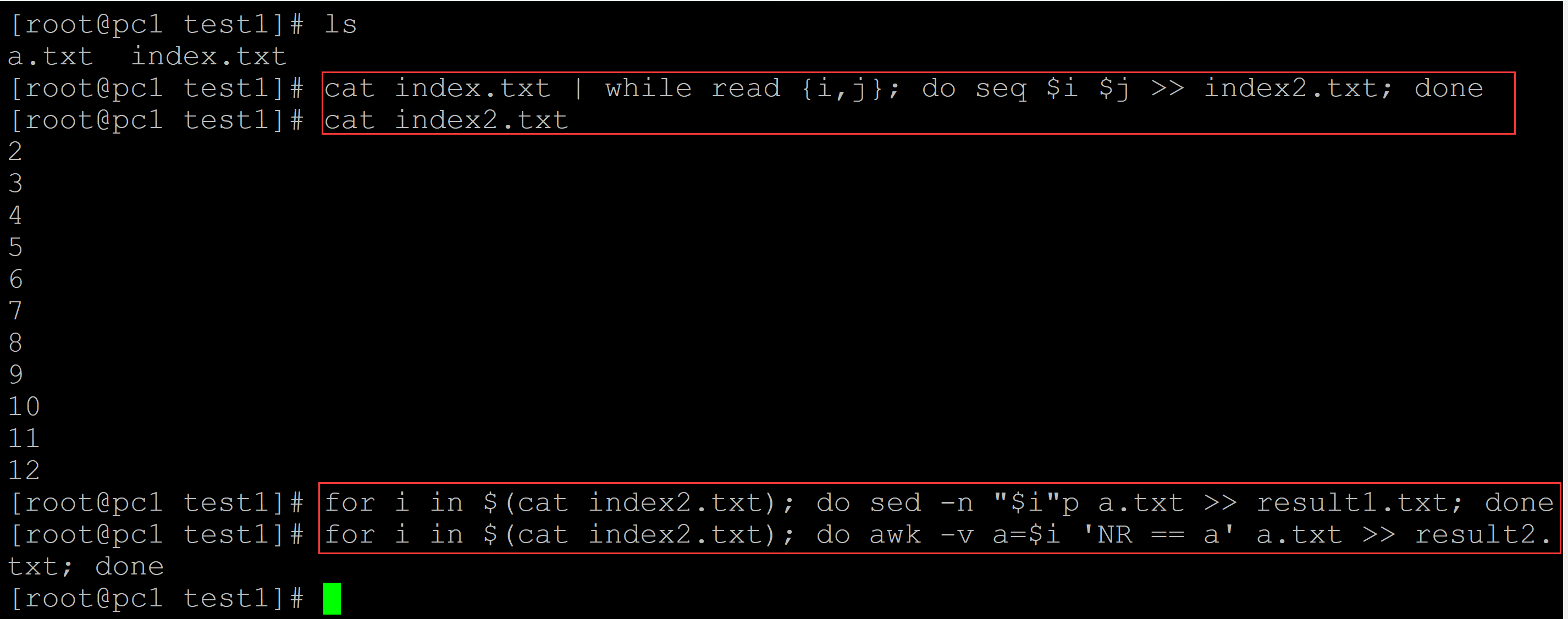
[root@pc1 test1]# ls a.txt index.txt [root@pc1 test1]# cat index.txt | while read {i,j}; do seq $i $j >> index2.txt; done ## 将索引值展开 [root@pc1 test1]# cat index2.txt 2 3 4 5 6 7 8 9 10 11 12 ## 对展开的索引值进行迭代 [root@pc1 test1]# for i in $(cat index2.txt); do sed -n "$i"p a.txt >> result1.txt; done [root@pc1 test1]# for i in $(cat index2.txt); do awk -v a=$i 'NR == a' a.txt >> result2.txt; done
b、 查看结果
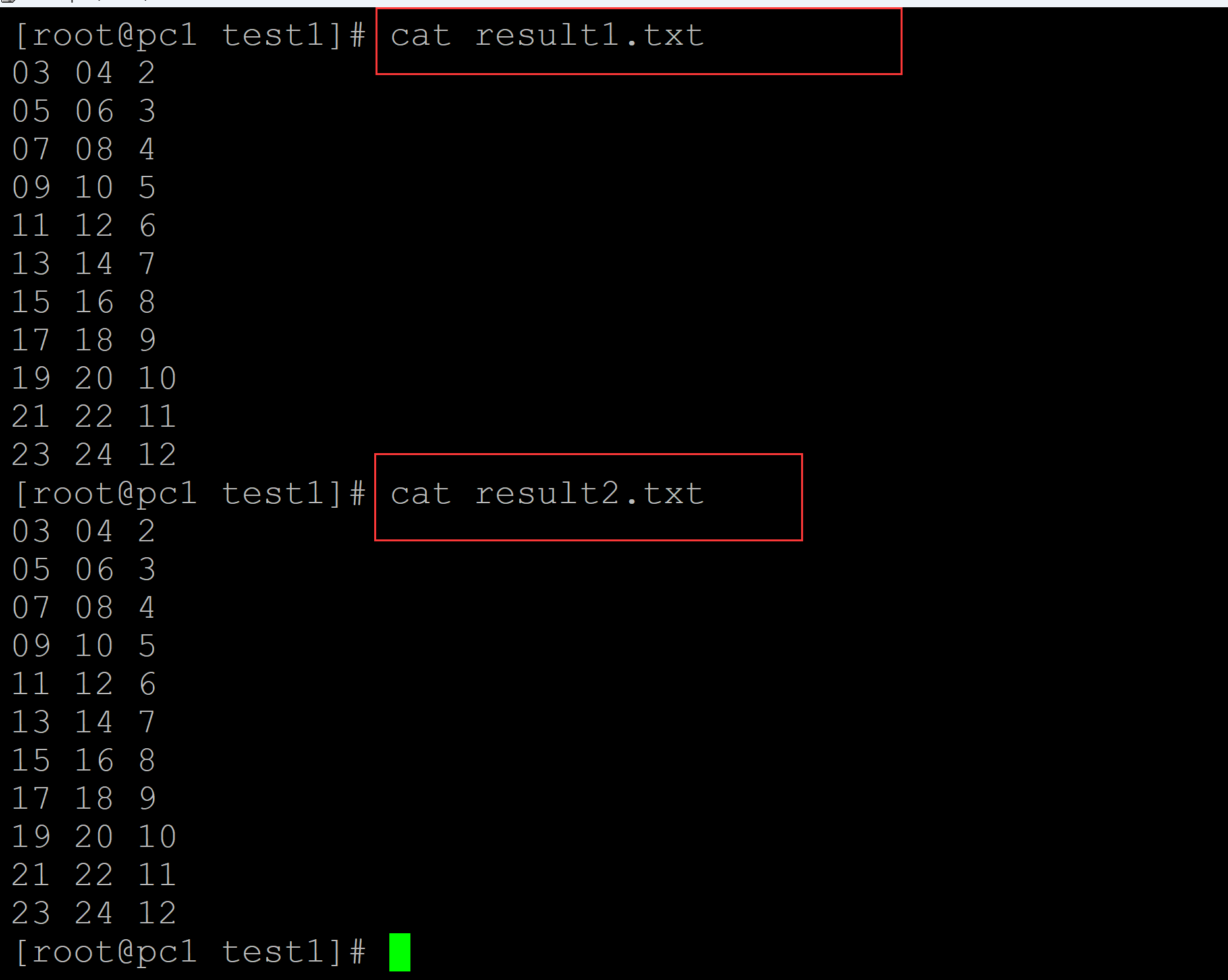
以上均需要对 a.txt进行多次读取,文件大时,速度太慢。
005、方法4
a、展开原始索引
[root@pc1 test1]# ls a.txt index.txt [root@pc1 test1]# cat index.txt ## 索引文件 2 4 7 8 11 12 ## 展开原始索引 [root@pc1 test1]# cat index.txt | while read {i,j}; do seq $i $j >> index2.txt; done [root@pc1 test1]# ls a.txt index2.txt index.txt [root@pc1 test1]# cat index2.txt ## 查看展开结果 2 3 4 7 8 11 12
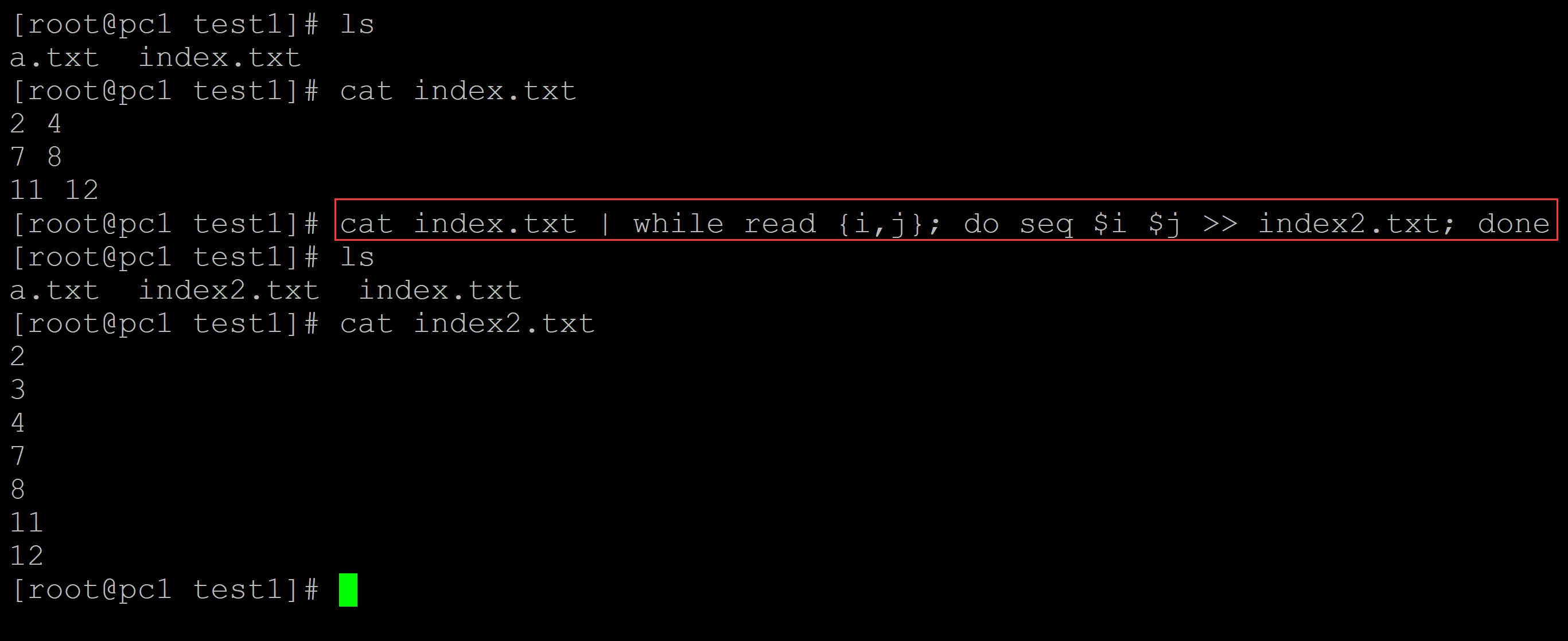
b、将展开的索引到原始文件行数之间的值全部补充为0
[root@pc1 test1]# ls a.txt index2.txt index.txt [root@pc1 test1]# cat index2.txt 2 3 4 7 8 11 12 [root@pc1 test1]# cat index2.txt | cat - <(wc -l < a.txt) | awk '{if(NR == 1) {a = $0 - 0 - 1; for (i = 1; i <= a; i++) {print "0"};print $0; tmp = $0} else if ($0 - tmp != 1){a = $0 - tmp - 1; for (i = 1; i <= a; i++) {print "0"}; print $0; tmp = $0 } else {print $0; tmp = $0}}' > index3.txt [root@pc1 test1]# cat index3.txt ## 将空缺的位置补充为0 0 2 3 4 0 0 7 8 0 0 11 12 13
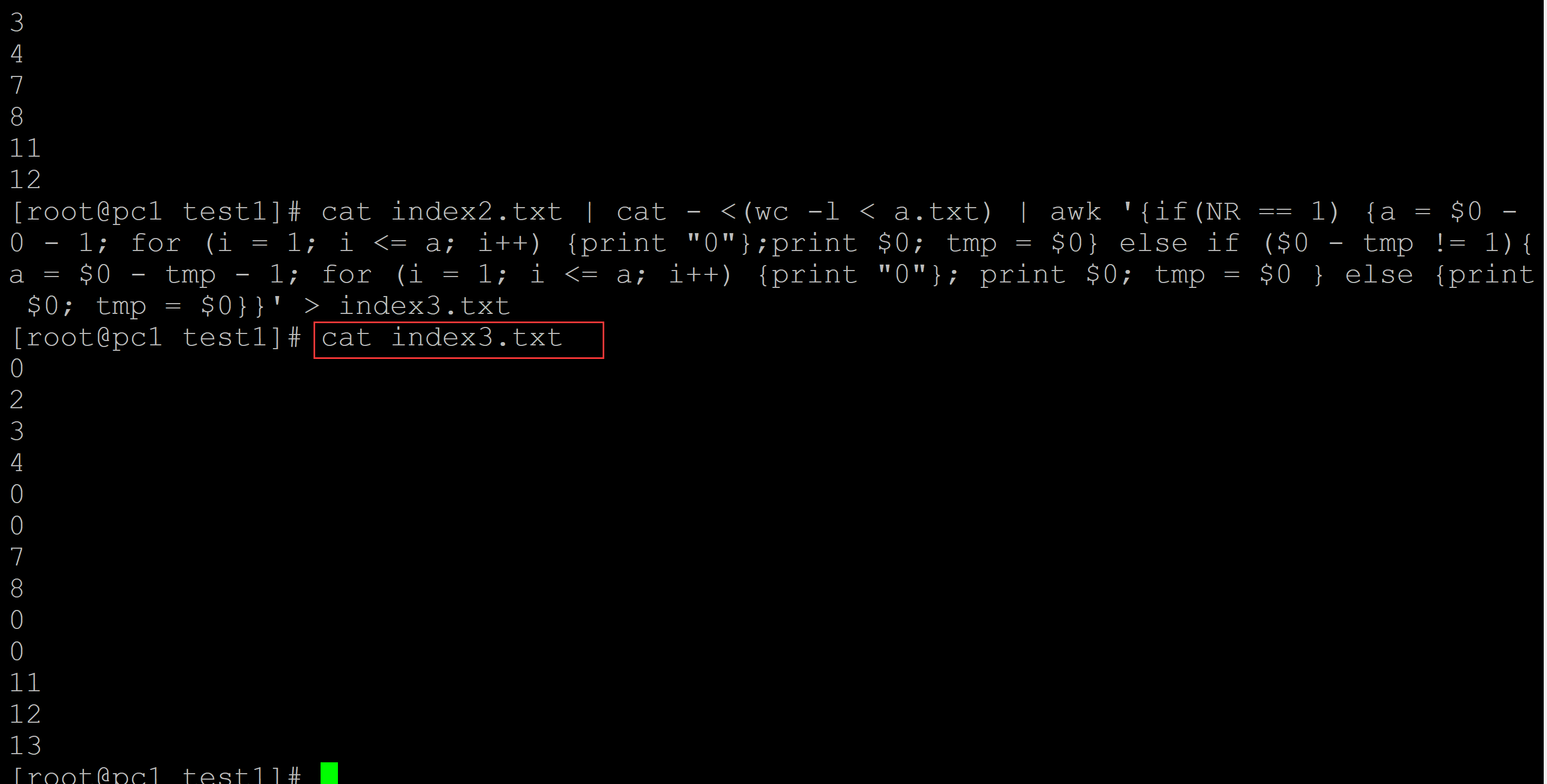
c、借助index3.txt提取数据
[root@pc1 test1]# ls a.txt index2.txt index3.txt index.txt [root@pc1 test1]# paste index3.txt a.txt | awk '$1 != 0' | cut -f 2- ## 借助index3批量提取 03 04 2 05 06 3 07 08 4 13 14 7 15 16 8 21 22 11 23 24 12 25 26 13
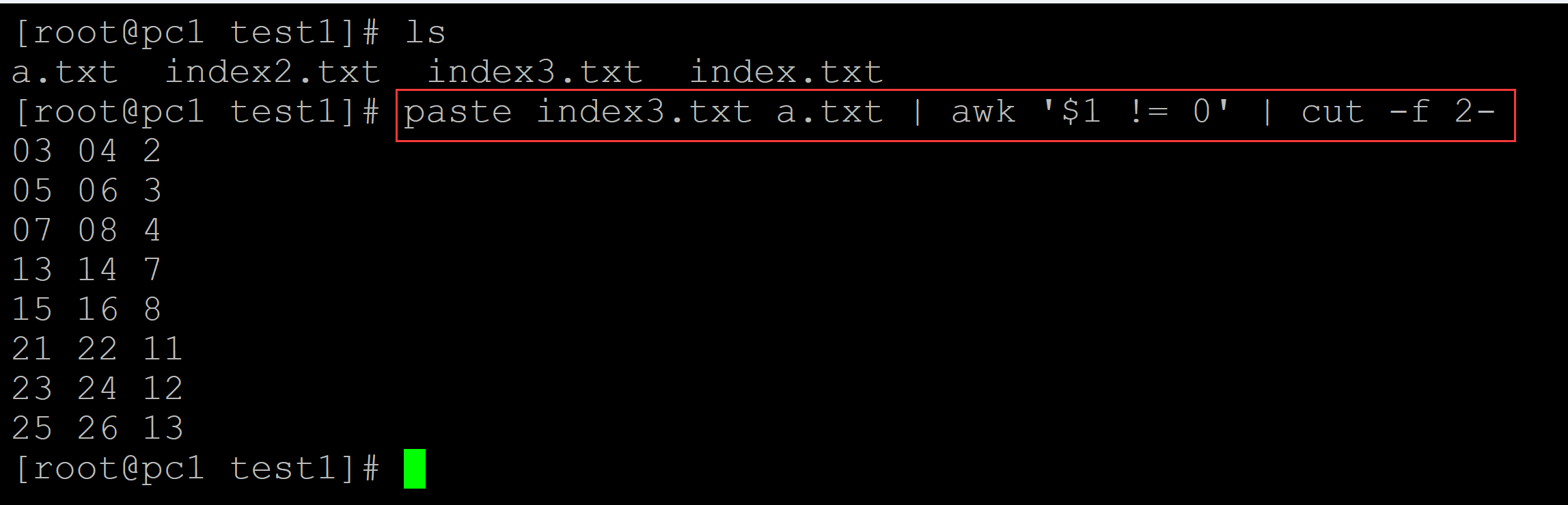
。
方法6: 借助awk双文件和数组
awk '{if(NR == FNR) {ay[$1]} else {if(FNR in ay) {print $0}}}' index2.txt a.txt ## awk双文件处理和数组
a、
[root@pc1 test2]# ls a.txt index.txt [root@pc1 test2]# cat a.txt 01 02 1 03 04 2 05 06 3 07 08 4 09 10 5 11 12 6 13 14 7 15 16 8 17 18 9 19 20 10 21 22 11 23 24 12 25 26 13 [root@pc1 test2]# cat index.txt 2 4 5 6 8 11 ## 展开索引 [root@pc1 test2]# cat index.txt | while read {i,j}; do seq $i $j >> index2.txt; done
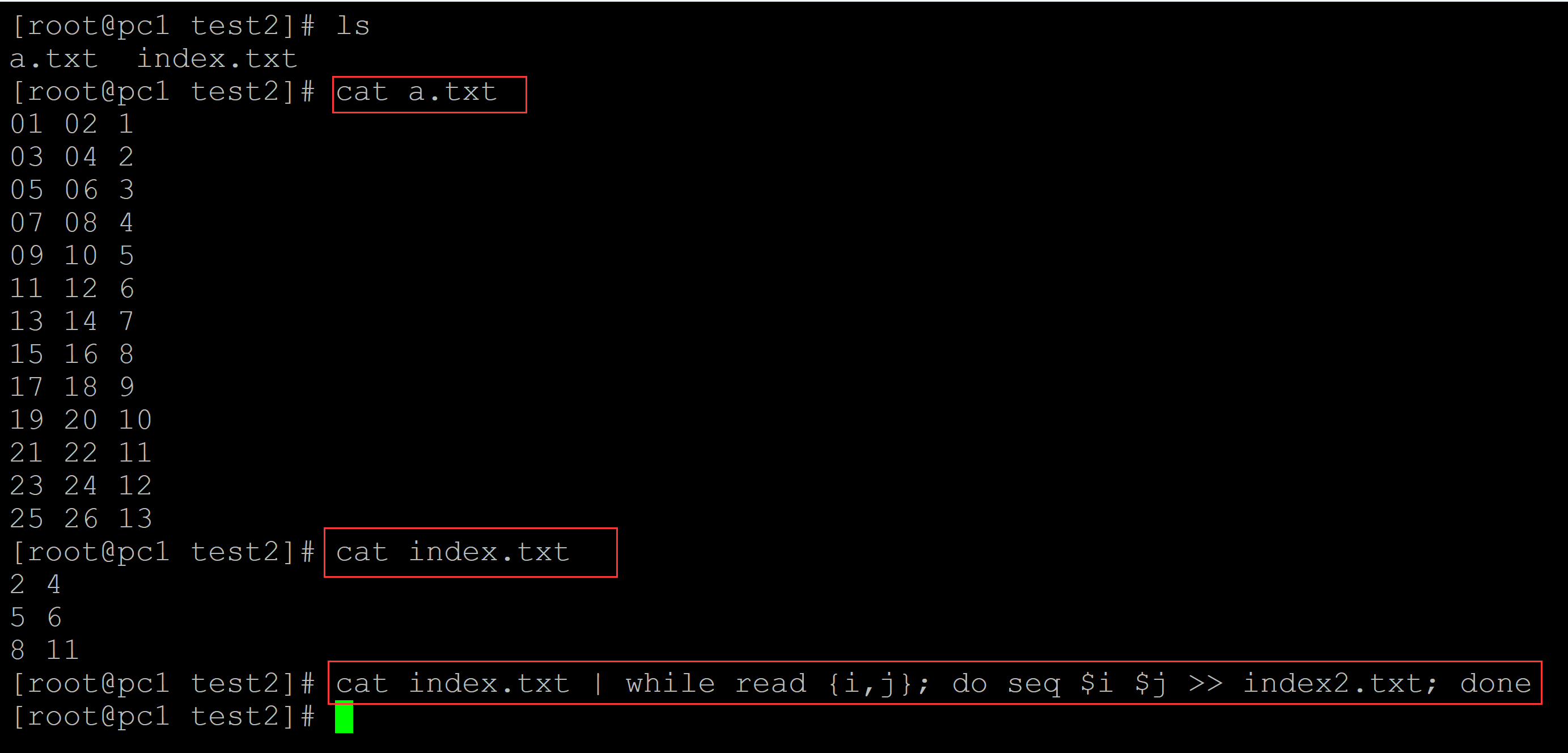
b\
[root@pc1 test2]# ls a.txt index2.txt index.txt [root@pc1 test2]# cat index2.txt 2 3 4 5 6 8 9 10 11
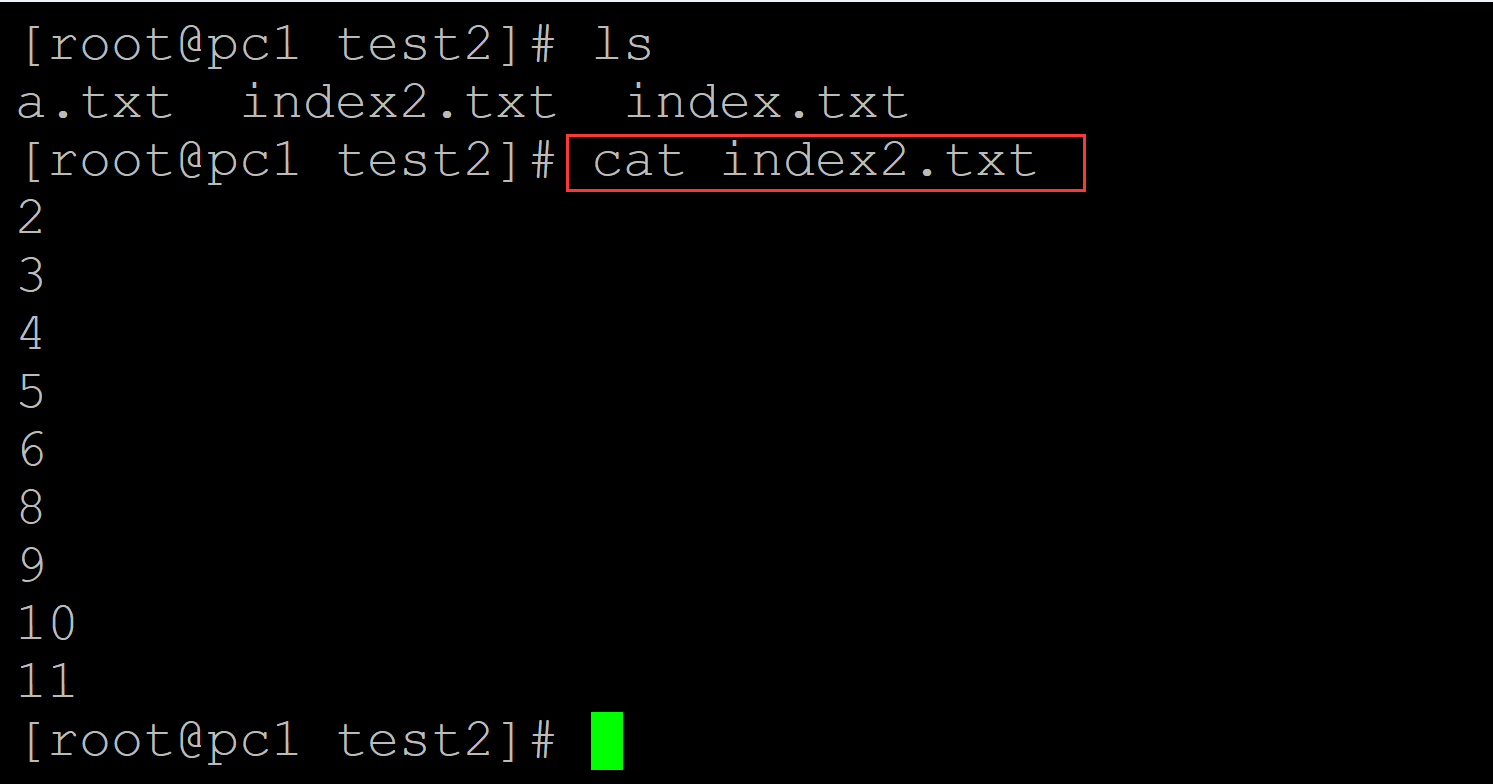
c\
[root@pc1 test2]# cat a.txt 01 02 1 03 04 2 05 06 3 07 08 4 09 10 5 11 12 6 13 14 7 15 16 8 17 18 9 19 20 10 21 22 11 23 24 12 25 26 13 [root@pc1 test2]# awk '{if(NR == FNR) {ay[$1]} else {if(FNR in ay) {print $0}}}' index2.txt a.txt 03 04 2 ## awk双文件 及 数组 05 06 3 07 08 4 09 10 5 11 12 6 15 16 8 17 18 9 19 20 10 21 22 11
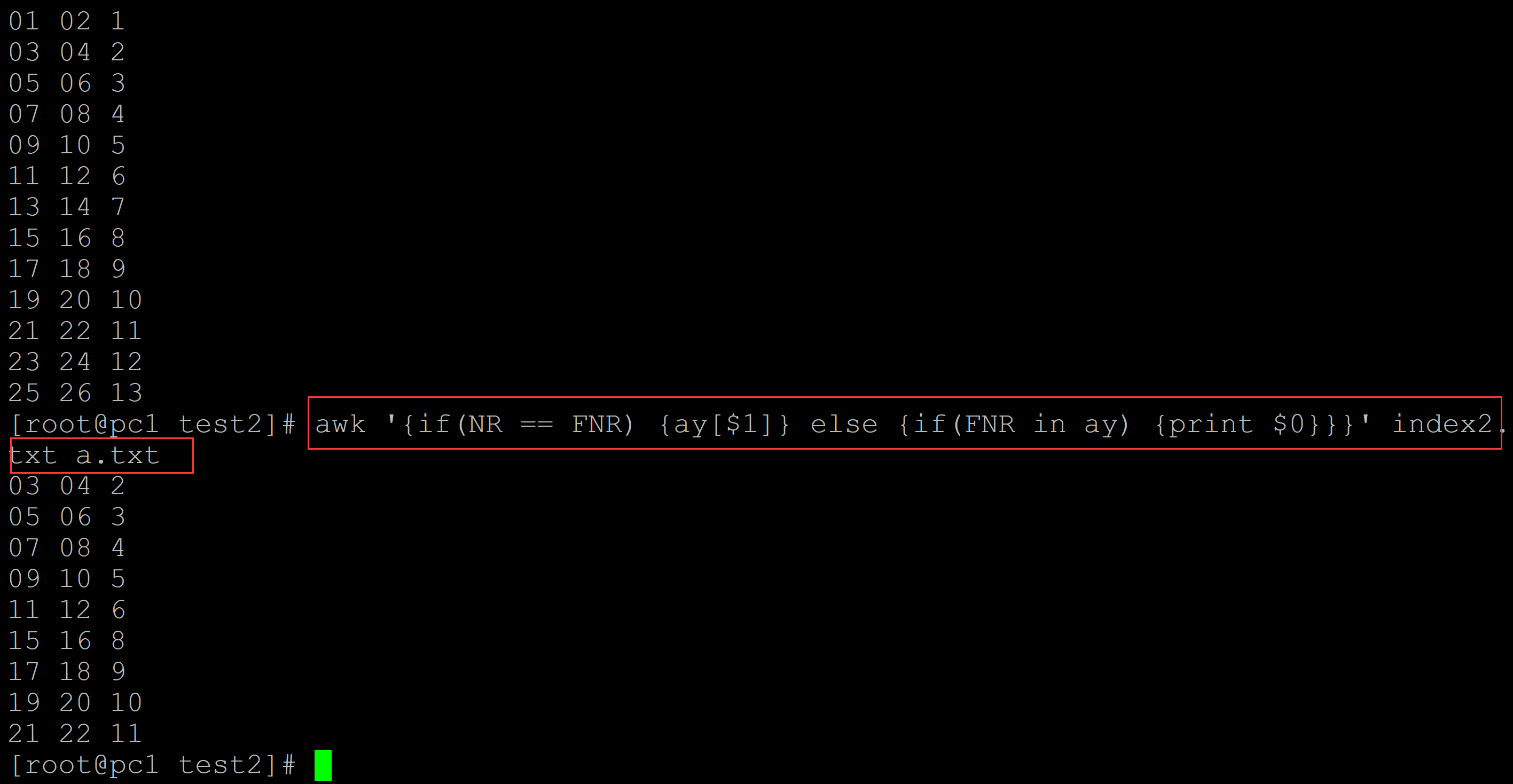
。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2020-10-11 linux 中大小写转换
2020-10-11 linux系统删除开头几个字符或者结尾几个字符
2020-10-11 linux grep多条件匹配数据
2020-10-11 linux grep匹配指定位数数字
2020-10-11 ModuleNotFoundError: No module named 'scipy' 报错解决记录