
python中实现 DNA一致性序列计算
001、

[root@pc1 test02]# ls a.fa test.py [root@pc1 test02]# cat a.fa ## 测试fasta >Rosalind_1 ATCCAGCT >Rosalind_2 GGGCAACT >Rosalind_3 ATGGATCT >Rosalind_4 AAGCAACC >Rosalind_5 TTGGAACT >Rosalind_6 ATGCCATT >Rosalind_7 ATGGCACT [root@pc1 test02]# cat test.py ## 计算程序 #!/usr/bin/env python # -*- coding: utf-8 -*- in_file = open("a.fa", "r") length = 0 for i in in_file: length += 1 if length == 2: length = len(i.strip()) break in_file.close() print(length) dict1 = {} list1 = [dict1.fromkeys(("A", "C", "G", "T"),0) ] * length list2 = [ dict(i) for i in list1 ] in_file = open("a.fa", "r") for i in in_file: if i[0] != ">": i = i.strip() for j in range(len(i)): if i[j] == "A": list2[j]["A"] += 1 if i[j] == "C": list2[j]["C"] += 1 if i[j] == "G": list2[j]["G"] += 1 if i[j] == "T": list2[j]["T"] += 1 in_file.close() dict2 = {"A":"", "C":"", "G":"", "T":""} for i in list2: for j in i: if j == "A": dict2["A"] += (" " + str(i["A"])) if j == "C": dict2["C"] += (" " + str(i["C"])) if j == "G": dict2["G"] += (" " + str(i["G"])) if j == "T": dict2["T"] += (" " + str(i["T"])) for i,j in dict2.items(): print(i, j) [root@pc1 test02]# python3 test.py ## 统计结果 8 A 5 1 0 0 5 5 0 0 C 0 0 1 4 2 0 6 1 G 1 1 6 3 0 1 0 0 T 1 5 0 0 0 1 1 6
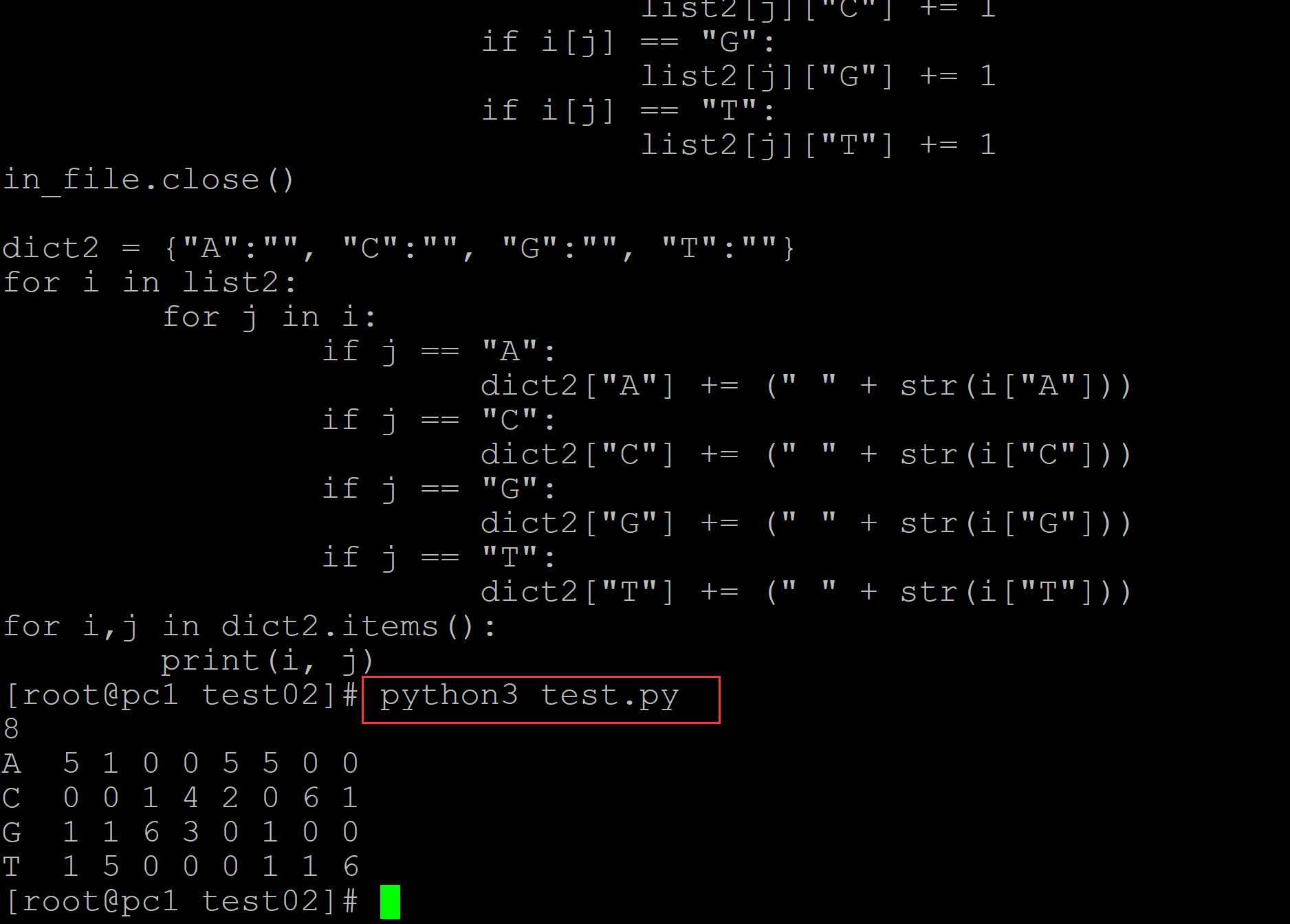
。
002、补充:
[root@PC1 test01]# ls a.fa test.py [root@PC1 test01]# cat a.fa ## 测试fasta文件 ATCCAGCT GGGCAACT ATGGATCT AAGCAACC TTGGAACT ATGCCATT ATGGCACT [root@PC1 test01]# cat test.py ## 测试程序 #!/usr/bin/env python3 # -*- coding: utf-8 -*- import sys import re import os in_file = open("a.fa", "r") out_file = open("result.txt", "w") length = len(in_file.readlines()[1].strip()) in_file.close() dict1 = dict() list1 = [dict1.fromkeys(("A", "C", "G", "T"), 0)] * length list1 = [dict(i) for i in list1] in_file = open("a.fa", "r") for i in in_file: i = i.strip() for j in range(length): if i[j] == "A": list1[j]["A"] += 1 if i[j] == "C": list1[j]["C"] += 1 if i[j] == "G": list1[j]["G"] += 1 if i[j] == "T": list1[j]["T"] += 1 in_file.close() for i in list1: print(i) for i in list1: for j in i: if i[j] == max(i.values()): print(j, end = " ") break print("") dict2 = {"A":"", "C":"", "G":"", "T":""} for i in list1: for j in i: if j == "A": dict2["A"] += str(i[j]) if j == "C": dict2["C"] += str(i[j]) if j == "G": dict2["G"] += str(i[j]) if j == "T": dict2["T"] += str(i[j]) for i in dict2: print(i, dict2[i]) [root@PC1 test01]# python3 test.py ## 运行结果 {'A': 5, 'C': 0, 'G': 1, 'T': 1} {'A': 1, 'C': 0, 'G': 1, 'T': 5} {'A': 0, 'C': 1, 'G': 6, 'T': 0} {'A': 0, 'C': 4, 'G': 3, 'T': 0} {'A': 5, 'C': 2, 'G': 0, 'T': 0} {'A': 5, 'C': 0, 'G': 1, 'T': 1} {'A': 0, 'C': 6, 'G': 0, 'T': 1} {'A': 0, 'C': 1, 'G': 0, 'T': 6} A T G C A A C T ## 序列一致性结果 A 51005500 C 00142061 G 11630100 T 15000116
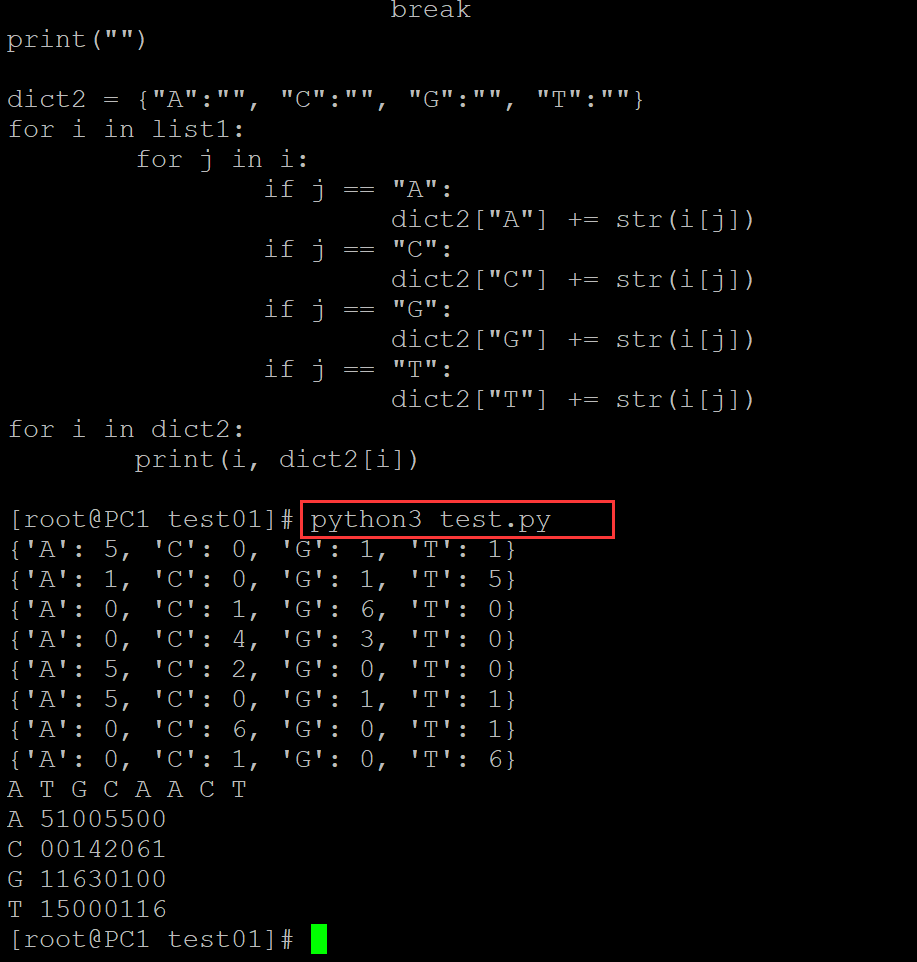
。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律