
linux 中根据指定列 删除重复行
001、

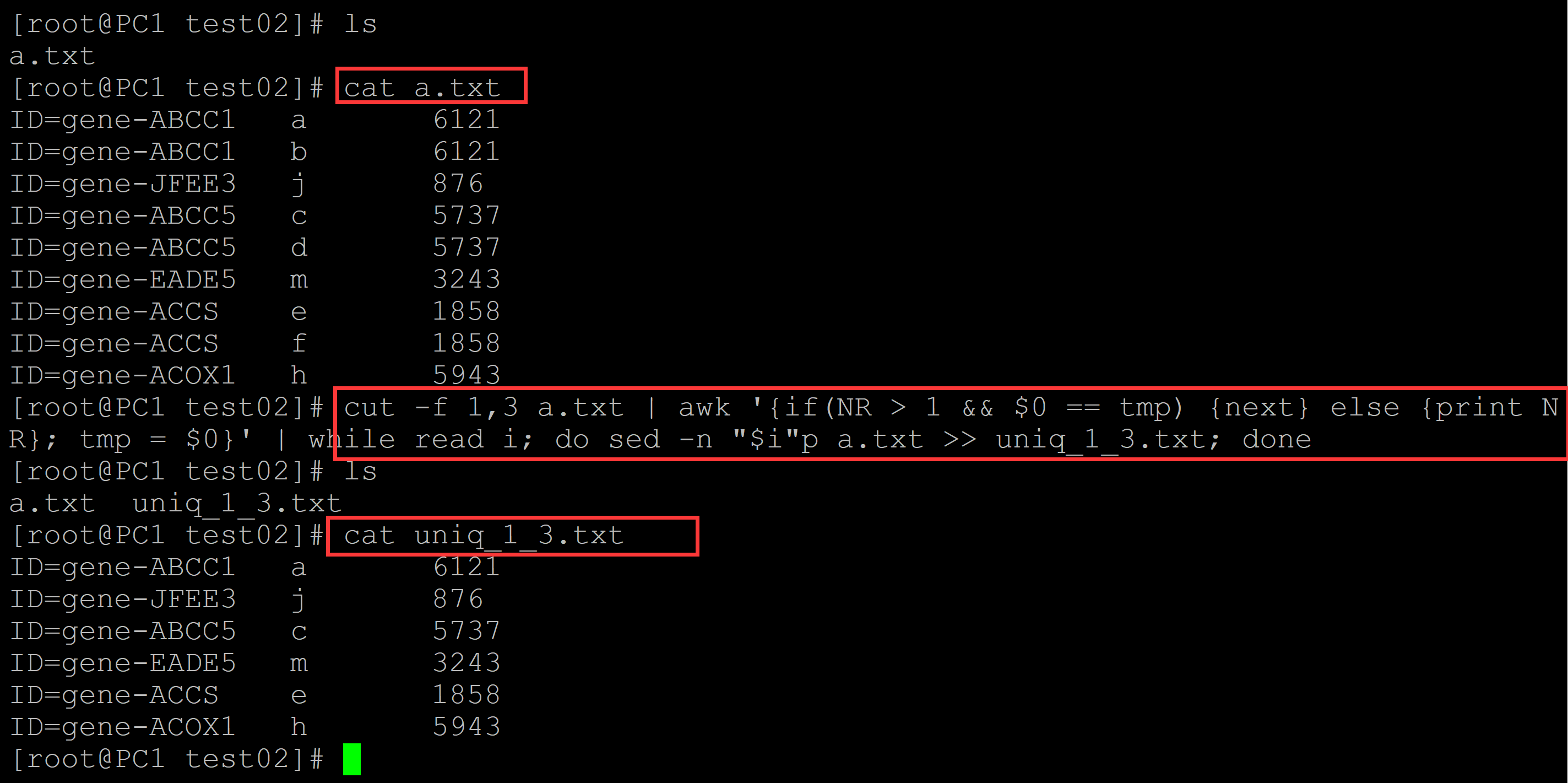
[root@PC1 test02]# ls a.txt [root@PC1 test02]# cat a.txt ## 测试数据 ID=gene-ABCC1 a 6121 ID=gene-ABCC1 b 6121 ID=gene-JFEE3 j 876 ID=gene-ABCC5 c 5737 ID=gene-ABCC5 d 5737 ID=gene-EADE5 m 3243 ID=gene-ACCS e 1858 ID=gene-ACCS f 1858 ID=gene-ACOX1 h 5943 ## 删除1,3列重复的行 [root@PC1 test02]# cut -f 1,3 a.txt | awk '{if(NR > 1 && $0 == tmp) {next} else {print NR}; tmp = $0}' | while read i; do sed -n "$i"p a.txt >> uniq_1_3.txt; done [root@PC1 test02]# ls a.txt uniq_1_3.txt [root@PC1 test02]# cat uniq_1_3.txt ID=gene-ABCC1 a 6121 ID=gene-JFEE3 j 876 ID=gene-ABCC5 c 5737 ID=gene-EADE5 m 3243 ID=gene-ACCS e 1858 ID=gene-ACOX1 h 5943
。
分类:
linux shell



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2022-07-06 硬盘接口、协议、总线
2021-07-06 plink格式中如何提取map文件重复的位点
2021-07-06 R语言中order函数,数值型和字符型的差异