
linux 中实现输出匹配字符之后或之前的若干行
001、输出匹配字符之后的若干行
a、

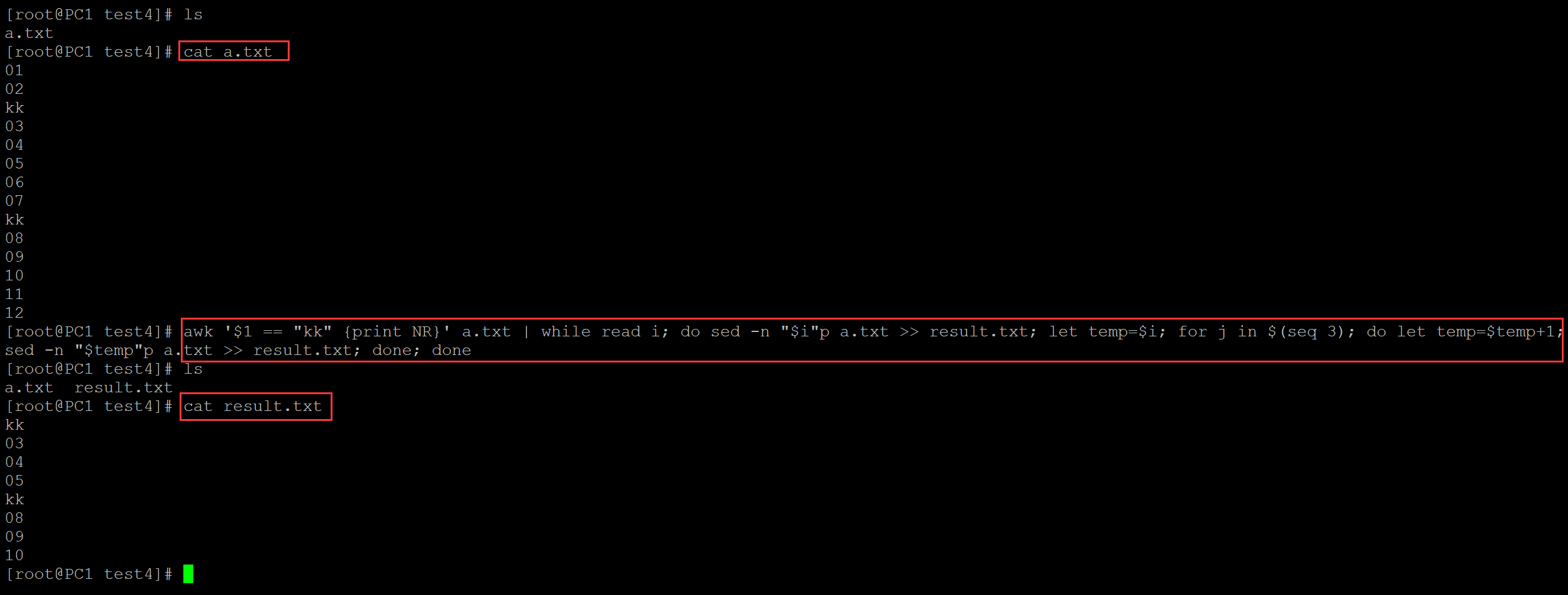
[root@PC1 test4]# ls a.txt [root@PC1 test4]# cat a.txt ## 测试数据 01 02 kk 03 04 05 06 07 kk 08 09 10 11 12 ## 输出匹配字符之后的3行 [root@PC1 test4]# awk '$1 == "kk" {print NR}' a.txt | while read i; do sed -n "$i"p a.txt >> result.txt; let temp=$i; for j in $(seq 3); do let temp=$temp+1; sed -n "$temp"p a.txt >> result.txt; done; done [root@PC1 test4]# ls a.txt result.txt [root@PC1 test4]# cat result.txt ## 结果文件 kk 03 04 05 kk 08 09 10
b、awk + 循环实现
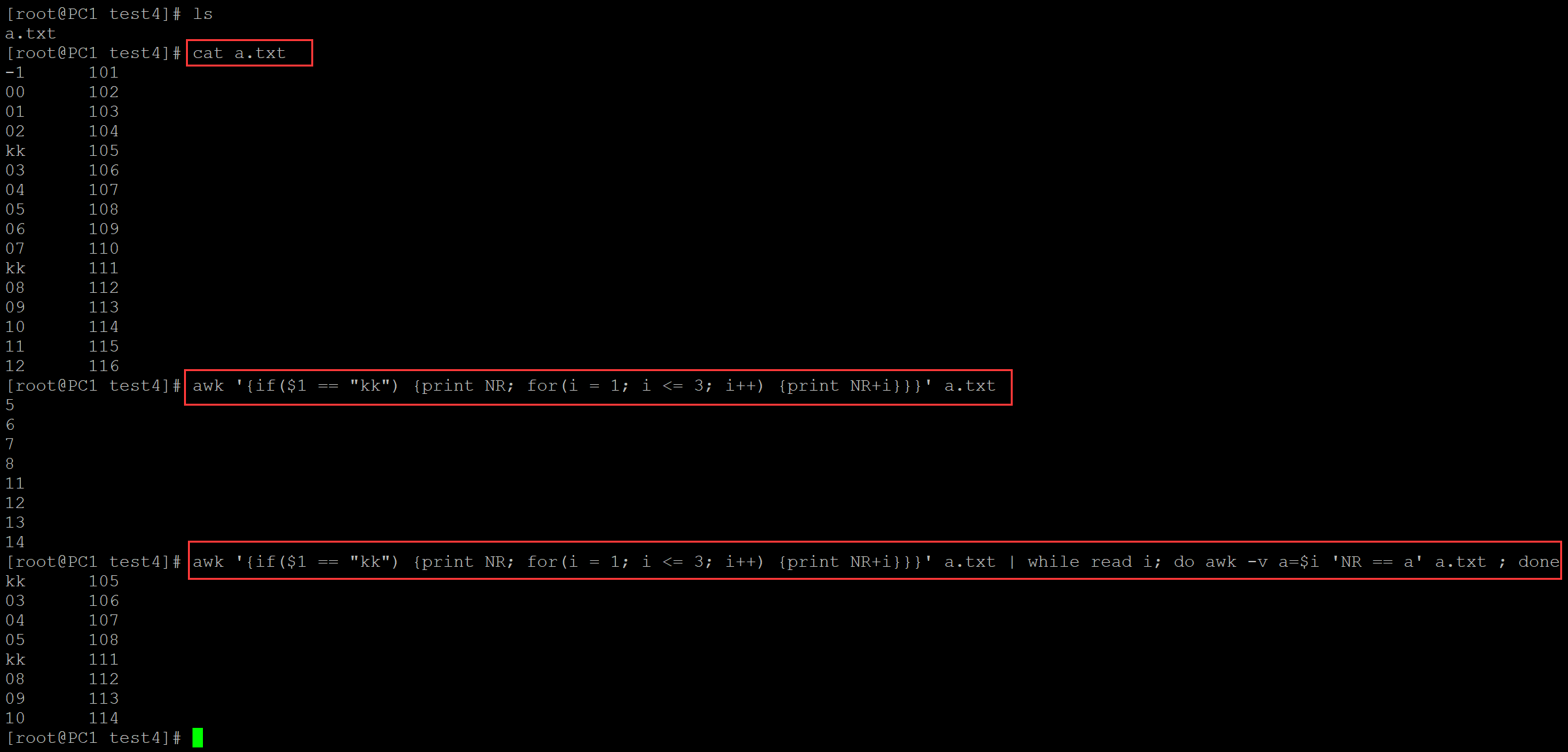
[root@PC1 test4]# ls a.txt [root@PC1 test4]# cat a.txt -1 101 00 102 01 103 02 104 kk 105 03 106 04 107 05 108 06 109 07 110 kk 111 08 112 09 113 10 114 11 115 12 116 [root@PC1 test4]# awk '{if($1 == "kk") {print NR; for(i = 1; i <= 3; i++) {print NR+i}}}' a.txt 5 6 7 8 11 12 13 14 [root@PC1 test4]# awk '{if($1 == "kk") {print NR; for(i = 1; i <= 3; i++) {print NR+i}}}' a.txt | while read i; do awk -v a=$i 'NR == a' a.txt ; done kk 105 03 106 04 107 05 108 kk 111 08 112 09 113 10 114
002、输出匹配字符之前的若干行
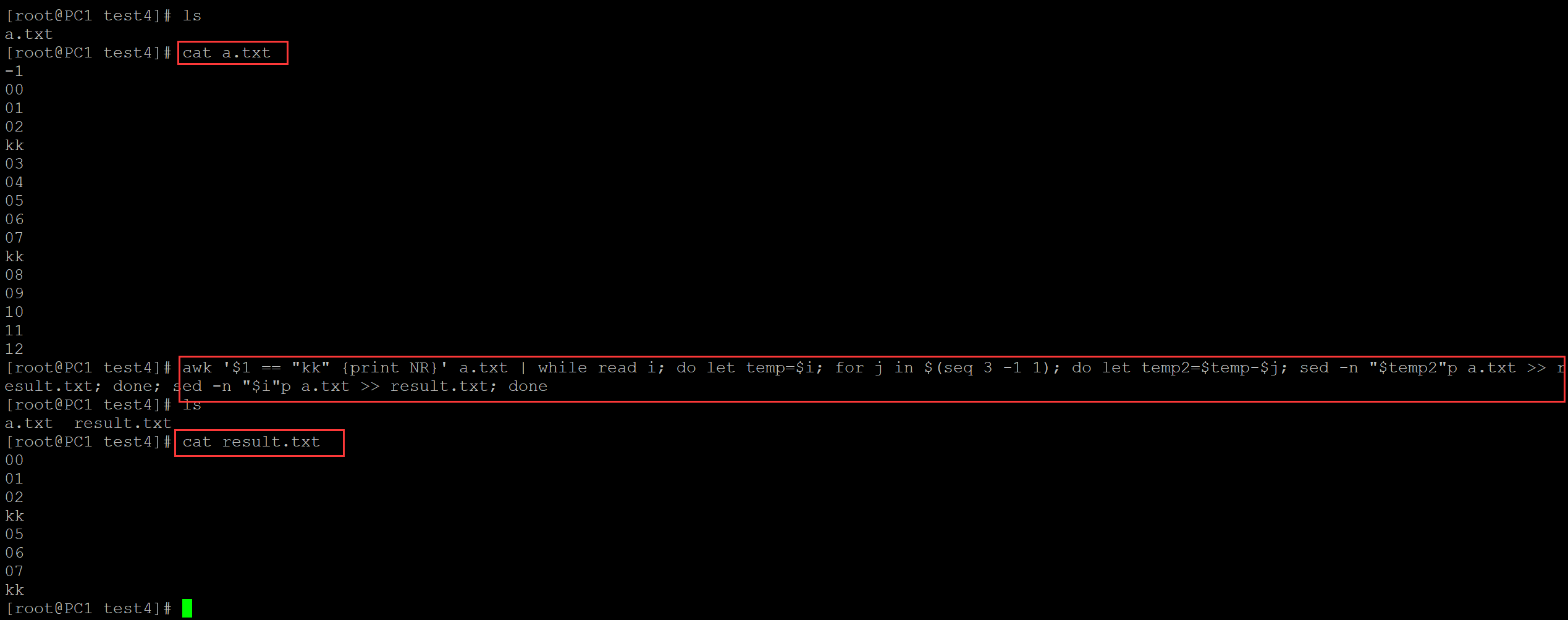
[root@PC1 test4]# ls a.txt [root@PC1 test4]# cat a.txt ## 测试文件 -1 00 01 02 kk 03 04 05 06 07 kk 08 09 10 11 12 ## 输出匹配字符之前的3行 [root@PC1 test4]# awk '$1 == "kk" {print NR}' a.txt | while read i; do let temp=$i; for j in $(seq 3 -1 1); do let temp2=$temp-$j; sed -n "$temp2"p a.txt >> result.txt; done; sed -n "$i"p a.txt >> result.txt; done [root@PC1 test4]# ls a.txt result.txt [root@PC1 test4]# cat result.txt ## 结果文件 00 01 02 kk 05 06 07 kk
awk + 循环实现:
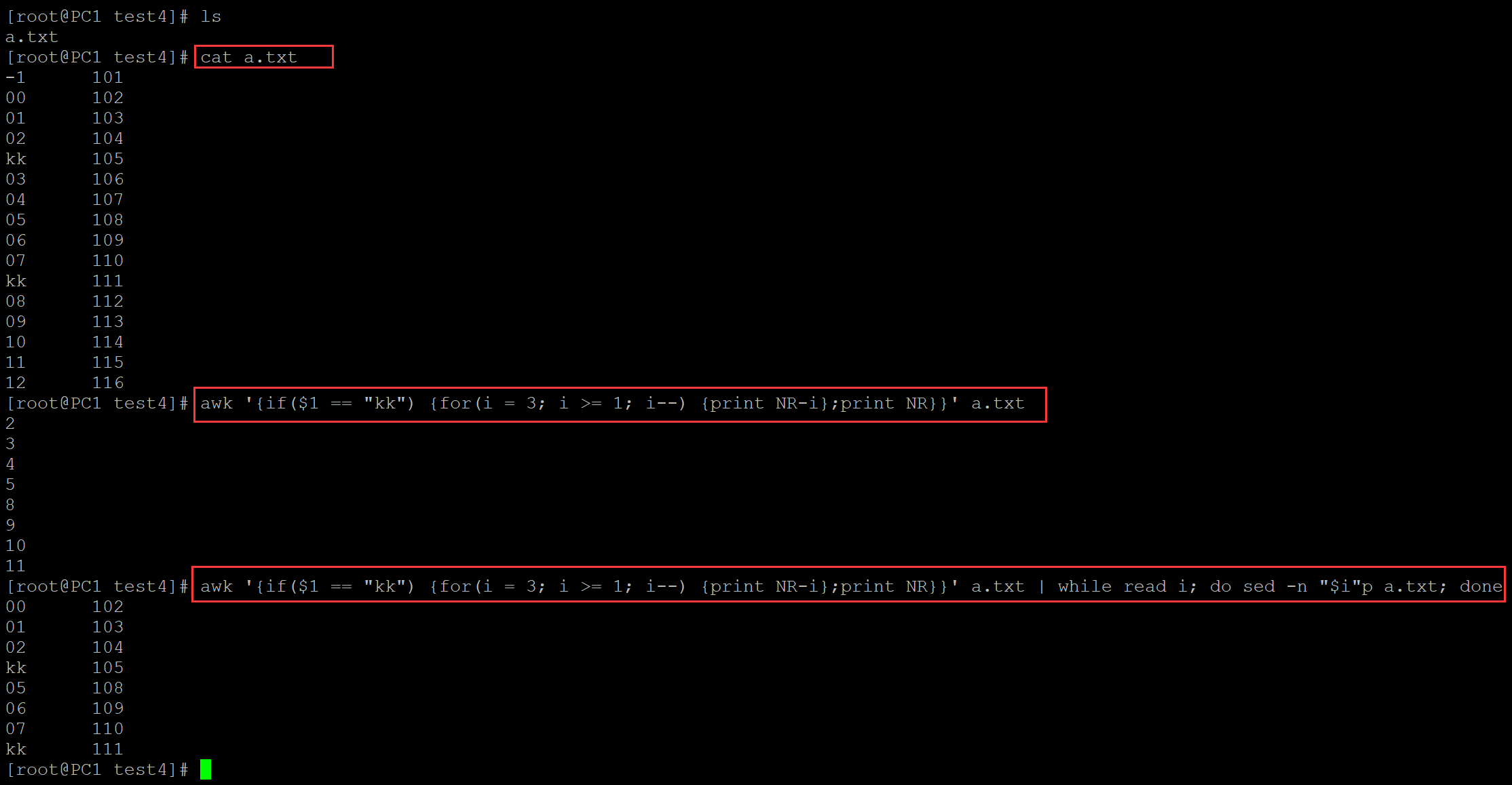
[root@PC1 test4]# ls a.txt [root@PC1 test4]# cat a.txt ## 测试数据 -1 101 00 102 01 103 02 104 kk 105 03 106 04 107 05 108 06 109 07 110 kk 111 08 112 09 113 10 114 11 115 12 116 [root@PC1 test4]# awk '{if($1 == "kk") {for(i = 3; i >= 1; i--) {print NR-i};print NR}}' a.txt 2 3 4 5 8 9 10 11 ## 输出匹配字符之前的3行 [root@PC1 test4]# awk '{if($1 == "kk") {for(i = 3; i >= 1; i--) {print NR-i};print NR}}' a.txt | while read i; do sed -n "$i"p a.txt; done 00 102 01 103 02 104 kk 105 05 108 06 109 07 110 kk 111
分类:
linux shell



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2022-06-04 python 中实现文本中字符串的替换
2022-06-04 python中如何删除文本中指定的列
2021-06-04 c语言中同时为两个数组排序
2021-06-04 c语言 12-5
2021-06-04 c语言中具有结构体成员的结构体
2021-06-04 c语言中利用结构体计算两点之间的距离。
2021-06-04 c语言 12-4