
R语言中统计频数分布
1、测试数据
test <- c(5.3, 5.6, 0.7, 0.6, 1.3, 2.8, 2.9, 2.1, 2.4, 3.7, 4.2, 4.9, 4.7, 4.8, 4.2)

2、生成统计节点
breaks <- seq(0, 6, length.out = 7) ## 生成统计节点 breaks test.break = cut(test, breaks) ##按照统计节点归类数据 test.break class(test.break) length(test.break)

3、统计频数频率、密度
freq <- table(test.break) freq densi <- freq / length(test) densi

4、画直方图
a、频数图
hist(test, breaks = breaks,labels = T)
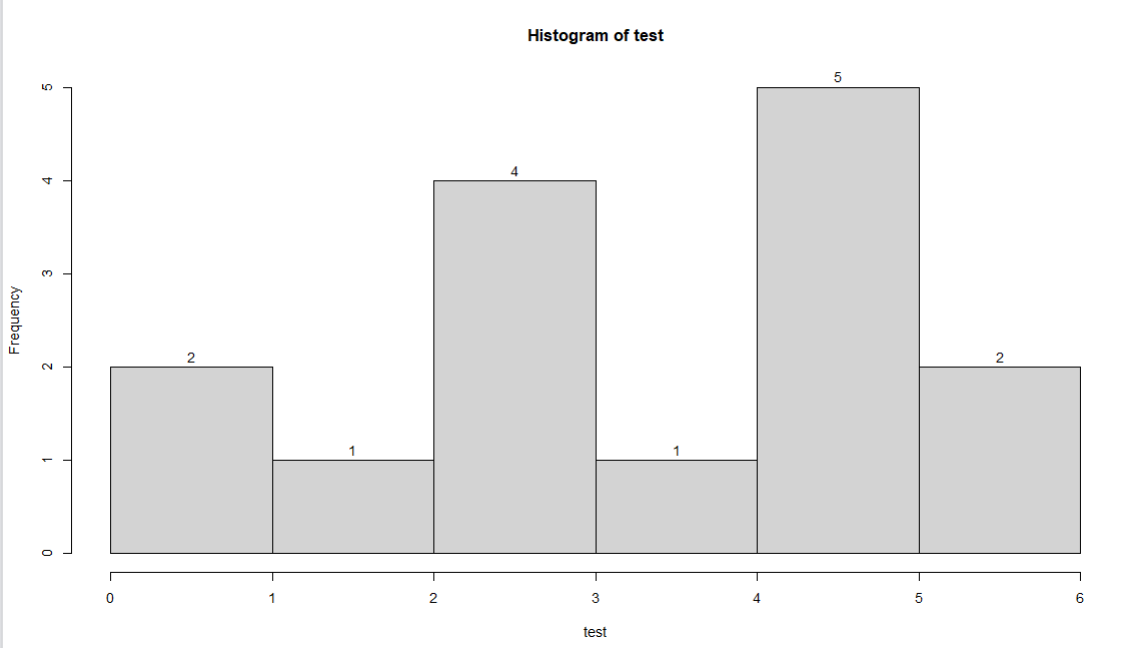
b、密度图
hist(test, breaks = breaks,labels = T, freq = F)




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2020-11-05 什么是端口?
2020-11-05 linux系统中防火墙管理工具iptables
2020-11-05 linux系统中nmcli命令、查看、添加、删除、编辑网络会话