30-Scala-集合操作
1. 基本介绍
1.1 集合分类
Scala 中的集合分为两种,一种是可变的集合,另一种是不可变的集合。
- 可变的集合可以在原集合上进行添加、更新及删除元素。
- 不可变集合一旦被创建便不能被改变,添加、更新及删除操作返回的是新的集合,老集合保持不变。
在 Scala 中,默认使用的都是 immutable 集合。如果要使用 mutable 集合,需要在程序中引入。
import scala.collection.mutable
scala> val mutableSet=mutable.Set(1,2,3)
mutableSet: scala.collection.mutable.Set[Int] = Set(1, 2, 3)
scala> val mutableSet=Set(1,2,3)
mutableSet: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
直接使用 Set(1,2,3) 创建的是 immutable 集合。这是因为当不引入任何包的时候,Scala 会默认导入以下几个包:

Predef 对象中包含了 Set、Map 等的定义。

1.2 类层次结构
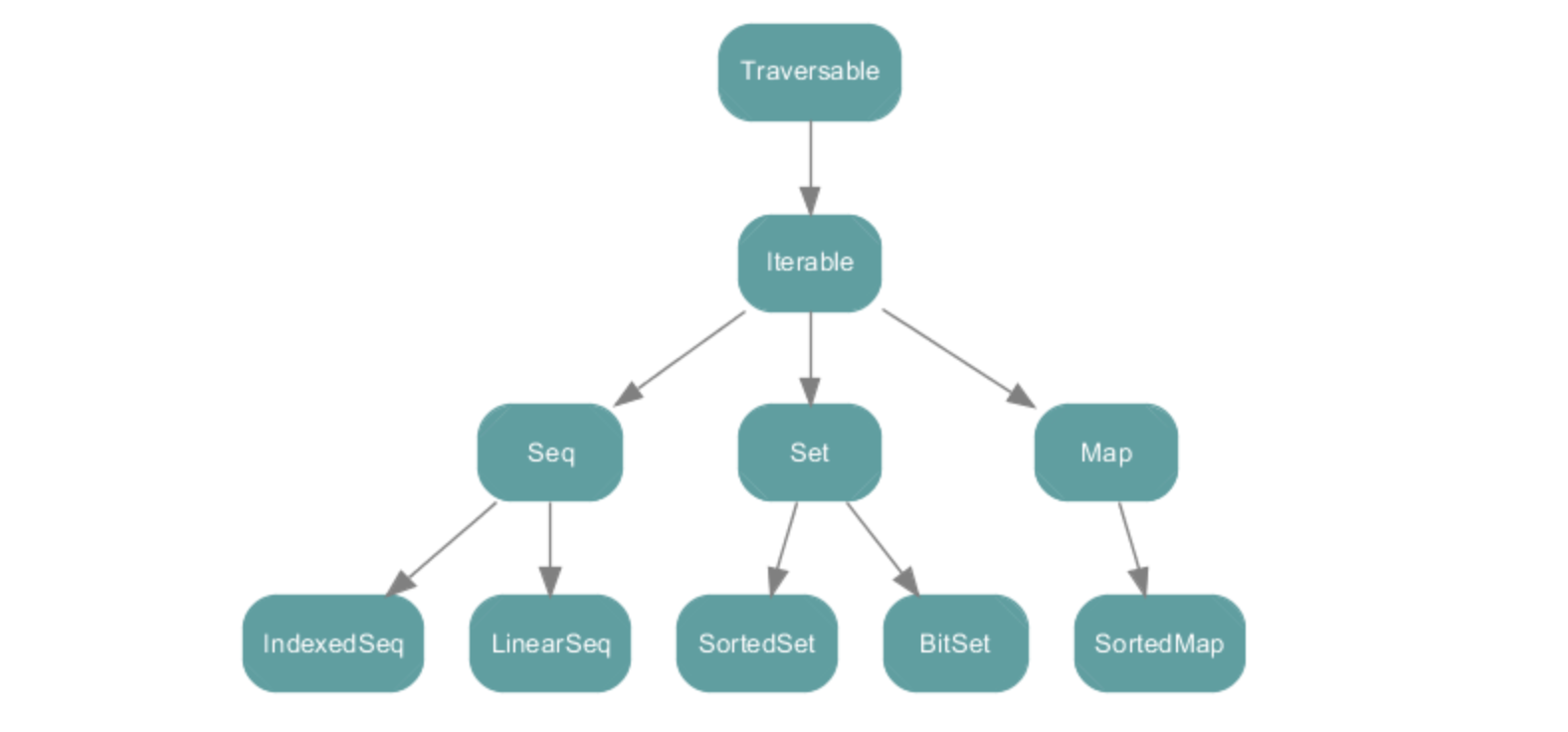
(1)scala.collection 包中的集合类层次结构
(2)scala.collection.immutable 包中的类层次结构
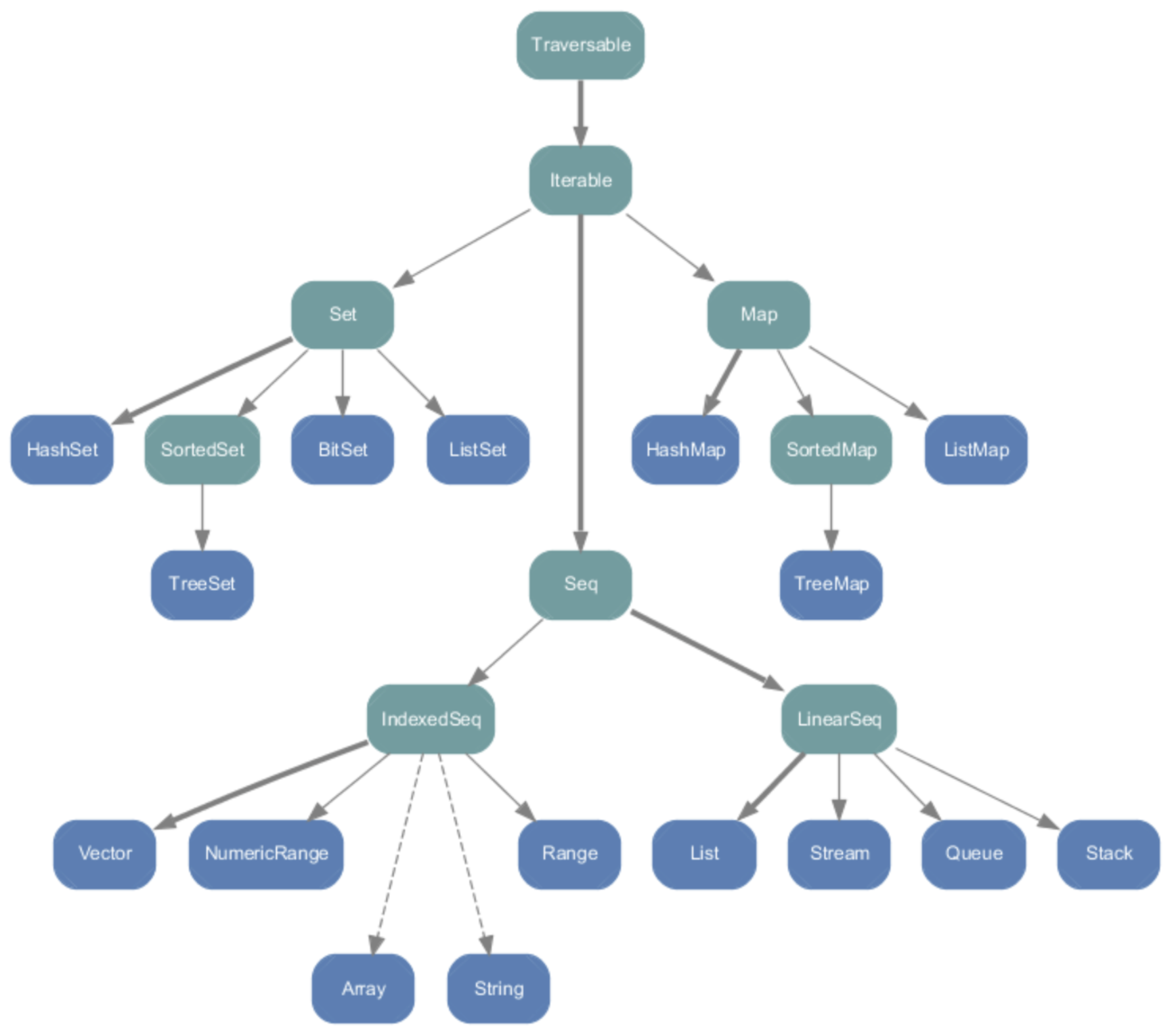
- Set、Map 是 Java 中也有的集合;Seq 是 Java 没有的,我们发现 List 归属到 Seq 了,因此这里的 List 就和 Java 不是同一个概念了;
- 前面在 for 循环时候有一个 1 to 3,就是 IndexedSeq 下的 Range
- String 也是属于 IndexedSeq
- 我们发现经典的数据结构比如 Queue 和 Stack 被归属到 LinearSeq(线性序列)
- 大家注意 Scala 中的 Map 体系有一个 SortedMap,说明 Scala 的 Map 可以支持排序
- IndexedSeq 和 LinearSeq 的区别
- IndexedSeq 是通过索引来查找和定位,因此速度快,比如 String 就是一个索引集合,通过索引即可定位;
- LinearSeq 是线型的,即有头尾的概念,这种数据结构一般是通过遍历来查找。
(3)scala.collection.mutable 包中的类层次结构

2. 数组
2.1 定长 Array
在 Scala 中,Array 代表的含义与 Java 中类似,也是长度不可改变的数组,但内容可以修改。此外,由于 Scala 与 Java 都是运行在 JVM 中,双方可以互相调用,因此 Scala 数组的底层实际上是 Java 数组。例如字符串数组在底层就是 Java 的 String[],整数数组在底层就是 Java 的 Int[]。
(1)声明方式一:val arr1 = new Array[Int](10) 声明一个长度为 10,泛型为 Int 类型的数组;这种方式必须指定具体的泛型类型。
object ArrayTest {
def main(args: Array[String]): Unit = {
//(1)数组定义
val arr01 = new Array[Int](4)
println(arr01.length) // 4
//(2)数组赋值
//(2.1)修改某个元素的值
arr01(3) = 10
//(2.2)采用方法的形式给数组赋值
arr01.update(0, 1)
//(3)遍历数组
//(3.1)查看数组
println(arr01.mkString(","))
//(3.2)普通遍历
for (i <- arr01) {
println(i)
}
//(3.3)简化遍历
def printx(elem: Int): Unit = {
println(elem)
}
arr01.foreach(printx)
// arr01.foreach( (x) => {println(x)} )
// arr01.foreach(println(_))
arr01.foreach(println)
//(4)增加元素(由于创建的是不可变数组,增加元素,其实是产生新的数组)
println(arr01)
val ints: Array[Int] = arr01 :+ 5
println(ints)
}
}
(2)声明方式二:val arr1 = Array(1, 2) 在定义数组时,直接赋初始值;使用 Array 伴生对象的 apply 方法创建数组对象。
object ArrayTest {
def main(args: Array[String]): Unit = {
var arr02 = Array(1, 3, "boo")
println(arr02.length)
for (i <- arr02) {
println(i)
}
}
}
2.2 变长 ArrayBuffer
语法:
val arr01 = ArrayBuffer[Any](1, 2, 5)
// - [Any] 存放任意数据类型
// - (3, 2, 5) 初始化好的三个元素
// - ArrayBuffer 需要引入 scala.collection.mutable.ArrayBuffer
案例:
object ArrayBufferTest {
def main(args: Array[String]): Unit = {
//(1)创建并初始赋值可变数组
val arr01 = ArrayBuffer[Any](1, 2, 5)
println(s"\n${arr01.length}") // 3
println("arr01.hash=" + arr01.hashCode())
//(2)增加元素
//(2.1)追加数据
arr01.+=(3)
arr01 += 4
//(2.2)向数组最后追加数据
// def append(elems: A*)
arr01.append(7, 9)
//(2.3)向指定的位置插入数据
// def insert(n: Int, elems: A*)
arr01.insert(0, 6, 8)
println("arr01.hash=" + arr01.hashCode())
//(3)修改元素,修改第 2 个元素的值
arr01(5) = 0
println("--------------------------")
for (i <- arr01) print(s"$i ") // 6 8 1 2 5 0 4 7 9
println(s"\n${arr01.length}") // 9
}
}
2.3 多维数组
// 二维数组中有 3 个一维数组,每个一维数组中有 4 个元素
val arr = Array.ofDim[Double](3,4)
2.4 可变与不可变互转
- arr1.toBuffer
- 不可变数组转可变数组
- 返回结果才是一个可变数组,arr1 本身没有变化
- arr2.toArray
- 可变数组转不可变数组
- 返回结果才是一个不可变数组,arr2 本身没有变化
3. 元组
元组也是可以理解为一个容器,可以存放各种相同或不同类型的数据。说的简单点,就是将多个无关的数据封装为一个整体,称为元组。需要注意的是:同一元组中最大只能有 22 个元素,如需扩展可以使用元组的嵌套。
Map 中的键值对其实就是元组,只不过元组的元素个数为 2,称之为“对偶”。
语法 · 示例说明:
object TupleTest {
def main(args: Array[String]): Unit = {
//(1)声明元组的方式:(元素1, 元素2, 元素3)
val tuple: (Int, String, Boolean) = (3, "boo", true)
//(2)访问元组
//(2.1)通过元素的顺序进行访问,调用方式:_<seq>
println(tuple._1)
println(tuple._2)
println(tuple._3)
//(2.2)通过索引访问数据
println(tuple.productElement(2))
//(2.3)通过迭代器访问数据
for (elem <- tuple.productIterator) {
println(elem)
}
//(3)Map 中的键值对其实就是元组,只不过元组的元素个数为 2,称之为对偶
val map1 = Map("a" -> 1, "b" -> 2, "c" -> 3)
val map2 = Map(("a", 1), ("b", 2), ("c", 3))
map1.foreach(tuple => println(s"${tuple._1} = ${tuple._2}"))
map2.foreach(tuple => println(s"${tuple._1} = ${tuple._2}"))
//(4)元组的拉链操作
val arr1: Array[Int] = Array(1, 2, 5)
val arr2: Array[String] = Array("o", "a", "b")
val mapZip: Array[(String, Int)] = arr2.zip(arr1)
// ArrayBuffer((o,11), (a,22), (b,55))
println(mapZip.toBuffer)
// 因为数组中每个元组的元素内容对称,可以使用toMap转化成Map集合
val map = mapZip.toMap
// Map(o -> 1, a -> 2, b -> 5)
println(map)
}
}
4. List
Scala 中的 List 和 Java 中的 List 不一样,在 Java 中 List 是一个接口,真正存放数据是实现类 ArrayList,而 Scala 的 List 可以直接存放数据,就是一个 object,默认情况下 Scala 的 List 是不可变的,List 属于序列 Seq。
4.1 不可变 List
(1)集合创建
// object List extends SeqFactory[List]
// 声明一个不可变集合
// val List = scala.collection.immutable.List
val list = List(1,2,3)
// 声明一个空集合
// val Nil = scala.collection.immutable.Nil
val emptyList = Nil
(2)元素访问
// 1 是索引,表示取出第 2 个元素
val value1 = list1(1)
(3)集合操作。因为 List 是类似于定长数组的结构,所以向集合中增加元素,会返回新的集合对象。原来的列表对象的内容并没有变化。
object ListTest2 {
def main(args: Array[String]): Unit = {
val list1 = List(1, 2, 3, "abc")
// :+ 运算符表示在列表的最后面增加数据
val list2 = list1 :+ 4
// List(1, 2, 3, abc, 4)
println(list2)
// :+ 运算符表示在列表的最前面增加数据
val list3 = 5 +: list1
// List(5, 1, 2, 3, abc)
println(list3)
}
}
不可变列表 List 是位于 scala.collection.immutable 中,在 Scala 中列表要么为空(Nil 表示空列表),要么是一个 head 元素加上一个 tail 列表。
:: 操作符是将给定的头和尾创建一个新的列表,例如 9 :: 2 表示 9 是 head 而 2 是 tail,返回的新的列表 List(9,2) ,需要注意的是 :: 操作符是右结合的,如 9 :: 5 :: 2 :: Nil 相当于 9 :: (5 :: (2 :: Nil)),即它是从右向左开始将 :: 操作符两边的 head 和 tail 结合的,最后返回的就是 List(9,5,2)。
object ListTest3 {
def main(args: Array[String]): Unit = {
//(1)创建一个 List(数据有顺序,可重复)
val org: List[Int] = List(1, 2, 3, 4, 5)
val sub: List[Char] = List('a', 'b', 'c')
//(2):: 表示向集合中新建集合添加元素。运算时,集合对象一定要放置在最右边,运算规则,从右向左。
val list1 = 1 :: 2 :: 3 :: 4 :: sub
println(list1) // List(1, 2, 3, 4, a, b, c)
val list2 = org :: sub
println(list2) // List(List(1, 2, 3, 4, 5), a, b, c)
val list3 = org :: Nil
println(list3) // List(List(1, 2, 3, 4, 5))
//(3)::: 表示集合间合并。将一个整体拆成一个一个的个体,称为扁平化。
val list4 = org ::: sub
println(list4) // List(1, 2, 3, 4, 5, a, b, c)
}
}
4.2 可变 ListBuffer
object ListBufTest {
def main(args: Array[String]): Unit = {
//(1)创建一个可变集合
val buffer = ListBuffer(1, 2, 3, 4)
//(2)向集合中添加数据
buffer.+=(5)
buffer.append(6)
buffer.insert(1, 2)
//(3)打印集合数据
buffer.foreach(println)
//(4)修改数据
buffer(1) = 6
buffer.update(1, 7)
//(5)删除数据
buffer.-(5)
buffer.-=(5)
buffer.remove(5)
}
}
5. Queue
队列是一个有序列表,在底层可以用数组或是链表来实现,遵循先入先出的原则。在 Scala 中,有 scala.collection.mutable.Queue 和 scala.collection.immutable.Queue。一般来说,我们在开发中通常使用可变集合中的队列。
object QueueTest {
def main(args: Array[String]): Unit = {
// 1. 创建队列
val q1 = new scala.collection.mutable.Queue[Any]
println(q1) // Queue()
// 2. 入队
q1 += 20
println(q1) // Queue(20)
q1 ++= List(2, 4, 6)
println(q1) // Queue(20, 2, 4, 6)
q1 += List(1, 2, 3)
println(q1) // Queue(20, 2, 4, 6, List(1, 2, 3))
q1 += 67
// 3. 出队
val deq = q1.dequeue()
println(s"deq=$deq, q1=$q1") // deq=20, q1=Queue(2, 4, 6, List(1, 2, 3))
// 4. 查看队列元素
println(q1.head) // 2
println(q1.last) // 67
// 返回除了第一个以外剩余的元素
println(q1.tail) // Queue(4, 6, List(1, 2, 3), 67)
println(q1.tail.tail) // Queue(6, List(1, 2, 3), 67)
}
}
6. Map
Scala 中的 Map 和 Java 类似,也是一个散列表,它存储的内容也是键值对 KV 映射。Scala 中不可变的 Map 是有序的,可变的 Map 是无序的。Scala 中,有可变 Map(scala.collection.mutable.Map)和不可变Map(scala.collection.immutable.Map)。
6.1 构造 Map 映射
object MapTest {
def main(args: Array[String]): Unit = {
// 1. 默认情况下(即没有引入其它包的情况下),创建的 Map 是不可变映射
val map1 = Map("Nayeon" -> 1, "Jeongyeon" -> 5, "1&2" -> "2yeon")
// Scala 中的不可变 Map 是有序的,构建 Map 中的元素底层是 Tuple2 类型。
println(map1) // Map(Nayeon -> 1, Jeongyeon -> 5, 1&2 -> 2yeon)
// 2. 创建可变Map
val map2 = scala.collection.mutable.Map("name" -> "ljq", "age" -> 24, "gender" -> 'f')
println(map2) // Map(age -> 24, name -> ljq, gender -> f)
// 3. 创建一个空的可变Map
val mutableMap = new scala.collection.mutable.HashMap[String, Int]
// 4. 创建一个空的不可变Map
val immutableMap: Map[String, Int] with Object = new scala.collection.immutable.HashMap[String, Int]
// 5. 对偶方式直接创建Map。即创建包含键值对的二元组,和第一种方式等价,只是形式上不同而已。
val map = Map(("A", 1), ("B", 2), ("C", 3))
}
}
6.2 Map 取值方式
object MapTest {
def main(args: Array[String]): Unit = {
val map = scala.collection.mutable.Map(("A", 1), ("B", 2), ("C", 3))
// 1. 通过 map(key) 获取,如果 key 存在,则返回对应的值,不存在则抛出异常
val value1 = map("A")
println(value1)
// Exception in thread "main" java.util.NoSuchElementException: key not found: D
// val value2 = map("D")
// 2. 通过 contains(key) 检查是否存在 key
println(map.contains("D"))
// 3. 通过 map.get(key).get 获取,返回一个Option对象,要么是 Some,要么是 None
val value3 = map.get("A")
println(s"${value3} => ${value3.get}") // Some(1) => 1
val value4 = map.get("D")
println(value4) // None
// value4.get // Exception in thread "main" java.util.NoSuchElementException: None.get
// 4. 通过 getOrElse(key) 获取,如果 key 存在,返回对应的值,不存在则返回默认值
val value5 = map.getOrElse("D", 4)
println(value5) // 4
}
}
6.3 增删改 Map 元素
object MapTest {
def main(args: Array[String]): Unit = {
val map = Map(("A", 1), ("B", 2), ("C", 3))
// 1. 新增
map += ("D" -> 4)
println(map) // Map(D -> 4, A -> 1, C -> 3, B -> 2)
map += ("B" -> 1101)
println(map) // Map(D -> 4, A -> 1, C -> 3, B -> 1101)
map += ("E" -> 5, "F" -> 6)
println(map) // Map(D -> 4, A -> 1, C -> 3, F -> 6, E -> 5, B -> 1101)
// 2. 删除
map -= ("A", "B")
println(map) // Map(D -> 4, C -> 3, F -> 6, E -> 5)
// 3. 更新
map("E") = 818
map += ("F" -> 8)
map.foreach(kv => print(s"$kv ")) // (D,4) (C,3) (F,8) (E,818)
}
}
7. Set
Set 是不重复元素的集合。不保留顺序,默认是以哈希集实现。默认情况下,Scala 使用的是不可变集合,如果你想使用可变集合,需要引用 scala.collection.mutable.Set。
object SetTest {
def main(args: Array[String]): Unit = {
// 1. 创建不可变集合
val set1 = Set(1, 'a', 3, 4, 5)
println(set1) // Set(5, 1, 97, 3, 4)
// 2. 创建可变集合
val set2 = scala.collection.mutable.Set(1, 2, 3, 4, 5)
println(set2) // Set(1, 5, 2, 3, 4)
// 3. 元素添加
set2.add(6)
set2.+=(7)
set2 += 8
println(set2) // Set(1, 5, 2, 6, 3, 7, 4, 8)
// 4. 元素删除,删除不存在的不会报错
set2.remove('a')
set2 -= 1
println(set2) // Set(5, 2, 6, 3, 7, 4, 8)
// 5. 查看元素
println(s"head = ${set2.head}") // head = 5
println(s"last = ${set2.last}") // last = 8
println(s"tail = ${set2.tail}") // tail = Set(2, 6, 3, 7, 4, 8)
}
}
更多操作:

8. 集合操作
高阶函数除了帮助我们在实现 API 时减少代码重复,还有另一个重要的用处是将高阶函数本身放在 API 当中来让调用方代码更加精简。如下操作函数都是 Scala 集合 API 中的公共函数,它减少的是 API 使用方的代码重复。
8.1 映射&过滤
a. map
将集合中的每一个元素通过指定功能(函数)映射(转换)成新的结果集合,其实就是所谓的将函数作为参数传递给另外一个函数,这是函数式编程的特点。
以 HashSet 为例说明:def map[B](f: (A) => B): HashSet[B],map 是一个高阶函数(可以接收一个函数的函数,就是高阶函数),可以接收函数 f: (A) => B,[B] 是泛型,HashSet[B] 就是返回的新的集合。
object MapOpTest {
def main(args: Array[String]): Unit = {
val d1: Double = test(sum, 11.01)
println(d1) // 22.02
val d2: Double = test(d => d + 13, 6.7)
println(d2) // 19.7
val d3: Double = test(_ + 1, 6.7)
println(d3) // 7.7
// 把函数赋给一个变量
val f1 = myPrint _
f1() // 把函数赋给一个变量: val <name> = <funcName> _
val list = List(1, 2, 3)
val list2 = list.map(multiple)
println(list2) // List(2, 4, 6)
}
def myPrint(): Unit = println("把函数赋给一个变量: val <name> = <funcName> _")
def multiple(n: Int): Int = n << 1
/**
* test2是个高阶函数,入参是一个函数
*
* @param f 一个入参为空、返回值为空的函数
*/
def test2(f: () => Unit) = {}
/**
* test就是一个高阶函数
*
* @param f 表示一个函数,该函数入参Double,返回Double
* @param n1 普通参数
* @return
*/
def test(f: Double => Double, n1: Double) = f(n1)
def sum(d: Double): Double = d + d
}
b. flatmap
flat 即压扁,压平,扁平化,效果就是将集合中的每个元素的子元素映射到某个函数并返回新的集合。
object FlatMapOpTest {
def main(args: Array[String]): Unit = {
val mix3 = List("Nayeon", "Jeongyeon", "Jihyo")
val mix3Up = mix3.flatMap(s => s.toUpperCase)
println(mix3Up) // List(N, A, Y, E, O, N, J, E, O, N, G, Y, E, O, N, J, I, H, Y, O)
}
}
c. filter
将符合要求的数据(筛选)放置到新的集合中。
object FilterOpTest {
def main(args: Array[String]): Unit = {
val mix3 = List("Nayeon", "Jeongyeon", "Jihyo")
val filteredList = mix3.filter(name => name.startsWith("J"))
println(filteredList) // List(Jeongyeon, Jihyo)
}
}
8.2 简化/折叠/扫描
a. reduce
Reduce 简化(归约) 通过指定的逻辑将集合中的数据进行聚合,从而减少数据,最终获取结果。
- reduceRight
def reduceRight[B >: A](op: (A, B) => B): B- 从右边开始执行将得到的结果返回给第 2 个参数,然后继续和下一个元素运行,将得到的结果继续返回给第 2 个参数,依次继续。
- reduceLeft
def reduceLeft[B >: A](f: (B, A) => B): B- 从左边开始执行将得到的结果返回给第 1 个参数,然后继续和下一个元素运行,将得到的结果继续返回给第 1 个参数,依次继续。
示例代码:
object FlatMapOpTest {
def main(args: Array[String]): Unit = {
val list = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
// (1,2) (3,3) (6,4) (10,5) (15,6) (21,7) (28,8) (36,9)
val sum1 = list.reduceLeft(sum)
println()
// (8,9) (7,17) (6,24) (5,30) (4,35) (3,39) (2,42) (1,44)
val sum2 = list.reduceRight(sum)
println()
println(s"sum1=$sum1, sum2=$sum2") // sum1=45, sum2=45
val min: Int = list.reduceLeft(minVal)
println(s"min=$min") // min=1
}
def sum(n1: Int, n2: Int): Int = {
print(s"($n1,$n2) ")
n1 + n2
}
def minVal(n1: Int, n2: Int): Int = if (n1 < n2) n1 else n2
}
b. fold
fold 函数将上一步返回的值作为函数的第一个参数继续传递参与运算,直到集合中的所有元素被遍历。
def foldLeft[B](z: B)(@deprecatedName('f) op: (B, A) => B): B = {
var acc = z
var these = this
while (!these.isEmpty) {
acc = op(acc, these.head)
these = these.tail
}
acc
}
override def foldRight[B](z: B)(op: (A, B) => B): B = reverse.foldLeft(z)((right, left) => op(left, right))
示例代码:
object FoldMapOpTest {
def main(args: Array[String]): Unit = {
val list = List(1, 2, 3, 4)
def minus(n1: Int, n2: Int): Int = n1 - n2
val left = list.foldLeft(5)(minus)
val right = list.foldRight(5)(minus)
println(s"foldLeft: $left, foldRight: $right") // foldLeft: -5, foldRight: 3
// foldLeft 缩写
val r1 = (5 /: list)(minus)
// foldRight 缩写
val r2 = (list :\ 5)(minus)
println(s"r1=$r1, r2=$r2") // r1=-5, r2=3
}
/**
* 统计sentence中各个字母出现的次数
*/
def exercise2(sentence: String): Unit = {
def charCount(cntMap: mutable.Map[Char, Int], c: Char): mutable.Map[Char, Int] = {
cntMap + (c -> (cntMap.getOrElse(c, 0) + 1))
}
val cntMap = sentence.foldLeft(mutable.Map[Char, Int]())(charCount)
println(cntMap)
}
/**
* 将sentence中各个字符,存放到一个ArrayBuffer中
*/
def exercise1(sentence: String): Unit = {
val arrBuf = new ArrayBuffer[Char]
sentence.foldLeft(arrBuf)(putArray)
println(arrBuf)
def putArray(arr: ArrayBuffer[Char], c: Char): ArrayBuffer[Char] = {
arr.append(c)
arr
}
}
}
c. scan
scan 扫描,即对某个集合的所有元素做 fold 操作,但是会把产生的所有中间结果放置于一个集合中保存。
object ScanMapOpTest {
def main(args: Array[String]): Unit = {
def minus(n1: Int, n2: Int): Int = {
print(s"($n1,$n2) ")
n1 - n2
}
// (1000,1) (999,2) (997,3) (994,4) (990,5) (985,6) (979,7) (972,8) (964,9) (955,10)
val ret1 = (1 to 10).scanLeft(1000)(minus)
println()
// (10,1000) (9,-990) (8,999) (7,-991) (6,998) (5,-992) (4,997) (3,-993) (2,996) (1,-994)
val ret2 = (1 to 10).scanRight(1000)(minus)
println()
// ret1 = Vector(1000, 999, 997, 994, 990, 985, 979, 972, 964, 955, 945)
// ret2 = Vector(995, -994, 996, -993, 997, -992, 998, -991, 999, -990, 1000)
println(s"ret1 = $ret1, ret2 = $ret2")
}
}
8.3 合并/迭代
- 在开发中,当我们需要将两个集合进行对偶元组合并,可以使用拉链 zip。
- 通过 iterator 方法从集合获得一个迭代器后,再通过 while 循环和 for 表达式对集合进行遍历。iterator 的构建实际是 AbstractIterator 的一个匿名子类,该 AbstractIterator 子类提供了 hasNext/next 等方法。
示例代码:
object ZipAndIteratorOpTest {
def main(args: Array[String]): Unit = {
val list1 = List(1, 2, 3)
val list2 = List(2, 4, 6)
val list12 = list1.zip(list2)
println(list12) // List((1,2), (2,4), (3,6))
for (item <- list12) print(s"(${item._1},${item._2}) ") // (1,2) (2,4) (3,6)
val iterator = list1.iterator
while (iterator.hasNext) {
println(iterator.next())
}
val iterator2 = list2.iterator
for (item <- iterator2) {
println(item)
}
}
}
zip 注意事项:
- 拉链的本质就是两个集合的合并操作,合并后每个元素是一个对偶元组 tuple2;
- 如果两个集合个数不对应,会造成数据丢失;
- 集合不限于 List,也可以是其它集合,如 Array;
- 如果要取出合并后的各个对偶元组的数据,可以遍历。
8.4 流/视图
Stream 是一个集合。这个集合可以用于存放无穷多个元素,但是这无穷个元素并不会一次性生产出来,而是需要用到多大的区间,就会动态的生产,末尾元素遵循 lazy 规则(即:要使用结果才进行计算的) 。
object StreamOpTest {
def main(args: Array[String]): Unit = {
val stream1 = numsForm(1)
println(stream1) // Stream(1, ?)
println(s"head=${stream1.head}") // head=1
println(s"tail=${stream1.tail}") // tail=Stream(2, ?)
}
def numsForm(n: BigInt): Stream[BigInt] = n #:: numsForm(n + 1)
}
说明:
- Stream 集合存放的数据类型是 BigInt;
- numsForm 是自定义的一个函数,函数名是程序员指定的,后续元素生成的规则也是手动指定的;
- 创建的集合的第一个元素是 n,后续元素生成的规则是 n + 1,当然这个规则我们可以自行设计,比如我们也可以设计一个斐波拉契数列,每次使用 tail 获取下一个值;
- 如果使用 Stream 集合,就不能使用 last 属性,否则集合就会进行无限循环!
Stream 的懒加载特性,也可以对其他集合应用 view 方法来得到类似的效果,具有如下特点:
- view 方法产出一个总是被懒执行的集合;
- view 不会缓存数据,每次都要重新计算,比如遍历 view 时。
object ViewOpTest {
def main(args: Array[String]): Unit = {
def eq(i: Int): Boolean = {
print(s"$i ")
i.toString.equals(i.toString.reverse)
}
println("\n===== common =====\n")
// 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
val ret1 = (1 to 24).filter(eq)
println(s"\n$ret1\n") // Vector(1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22)
println("\n====== view ======\n")
val ret2 = (1 to 24).view.filter(eq)
println(s"\n$ret2\n") // SeqViewF(...)
// 1 [1] 2 [2] 3 [3] 4 [4] 5 [5] 6 [6] 7 [7] 8 [8] 9 [9] 10 11 [11] 12 13 14 15 16 17 18 19 20 21 22 [22] 23 24
for (item <- ret2) {
print(s"[$item] ")
}
}
}
8.5 并行计算
Scala 为了充分使用多核 CPU,提供了并行集合(有别于前面的串行集合),用于多核环境的并行计算。
主要用到的算法:
- Divide and conquer 分治算法,Scala 通过 splitters(分解器)、combiners(组合器)等抽象层来实现,主要原理是将计算工作分解很多任务,分发给一些处理器去完成,并将它们处理结果合并返回;
- Work stealin 算法,主要用于任务调度负载均衡,通俗点讲就是当完成自己的所有任务之后,发现其他人还有活没干完,主动(或被安排)帮他人一起干,这样达到尽早干完的目的。
示例:
object ParallelOpTest {
def main(args: Array[String]): Unit = {
(1 to 5).foreach(print(_)) // 12345
println()
(1 to 5).par.foreach(print(_)) // 43521
println()
val result1 = (0 to 100).map { case _ => Thread.currentThread.getName }.distinct
val result2 = (0 to 100).par.map { case _ => Thread.currentThread.getName }.distinct
// Vector(main)
println(result1)
// ParVector(
// scala-execution-context-global-14, scala-execution-context-global-18,
// scala-execution-context-global-15, scala-execution-context-global-20,
// scala-execution-context-global-12, scala-execution-context-global-19,
// scala-execution-context-global-13, scala-execution-context-global-16,
// scala-execution-context-global-22, scala-execution-context-global-11,
// scala-execution-context-global-21, scala-execution-context-global-17)
println(result2)
}
}
9. 操作符即方法
摘自《Scala编程-第4版》5.4节
Scala 给它的基础类型提供了一组丰富的操作符。前面也提到过,这些操作符实际上只是普通方法调用的漂亮语法。例如,1 + 2 实际上跟 1.+(2) 是一回事。换句话说,Int 类包含了一个名为 + 的方法,接收一个 Int 参数,返回 Int 的结果。
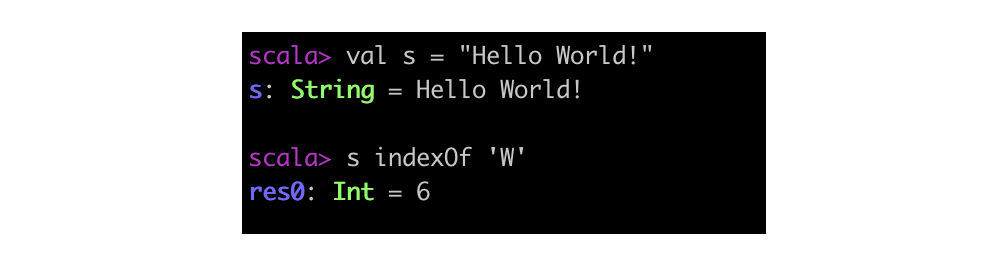
+ 符号是一个操作符,更确切地说是一个「中缀操作符」。操作符表 示法并不局限于那些在其他语言中看上去像操作符的那些方法。可以在操作符表示法中使用任何方法。例如,String 类有一个 indexOf 方法,接收一个 Char 参数。这个 indexOf 方法检索字符串中给定字符首次出现的位置,返回位置下标,如果没有找到,则返回 -1。你可以像操作符那样使用 indexOf:
除此之外,String 还提供了一个重载的 indexOf 方法,接收两个参数,分别是要查找的字符和开始检索的下标位置(之前提到的另外那个 indexOf 方法从下标 0 开始检索,也就是从 String 的最开始算起)。 虽然这个 indexOf 方法接收两个参数,但也可以用操作符表示法。不过只要是用操作符表示法来调用多个参数的方法,都必须将这些参数放在 () 里。以下是展示如何把两个参数的 indexOf 方法当作操作符来使用的例子:

任何方法都可以是操作符。在 Scala 中,操作符并不是特殊的语法,任何方法都可以是操作符。当你写下 s.indexOf('o') 时,indexOf 并不是操作符;但当你写 下 s indexOf 'o' 时,indexOf 就是操作符了,因为你用的是操作符表示法。
至此,你已经看到了「中缀操作符表示法」的若干示例,中缀操作符表示法意味着被调用的方法名位于对象和你想传入的参数中间,比如 7 + 2。Scala 还提供了另外两种操作符表示法:前缀和后缀。
- 在「前缀表示法」中,需要将方法名放在你要调用的方法的对象前面,比如
-7中的-; - 在「后缀表示法」中,需要将方法名放在对象之后,比如
7 toLong中的toLong。
跟中缀操作符表示法(操作符接收两个操作元,一个在左一个在右)不同,前缀和后缀操作符是一元的(unary):它们只接收一个操作元。
在前缀表示法中,操作元位于操作符的右侧。前缀操作符的例子有 -2.0、!found 和 0xFF 等。跟中缀操作符类似,这些前缀操作符也是调用方法的一种简写。不同的是,方法名称是 unary_ 加上操作符。举例来说,Scala 会把 -2.0 这样的表达式转换成如下的方法调用:(2.0).unary_-。

唯一能被用作前缀操作符的是 +、-、! 和 ~。因此,如果你定义了 一个名为 unary_! 的方法,可以对满足类型要求的值或变量使用前缀操作符表示法,比如 !p。不过如果你定义一个名为 unary_* 的方法,就不能用前缀操作符表示法了,因为 * 并不是可以用作前缀操作符的四个标识符之一。可以像正常的方法调用那样调用 p.unary_*,但如果你尝试 用 *p 这样的方式来调用,Scala 会当作 *.p 来解析,这大概并不是你想要的效果...
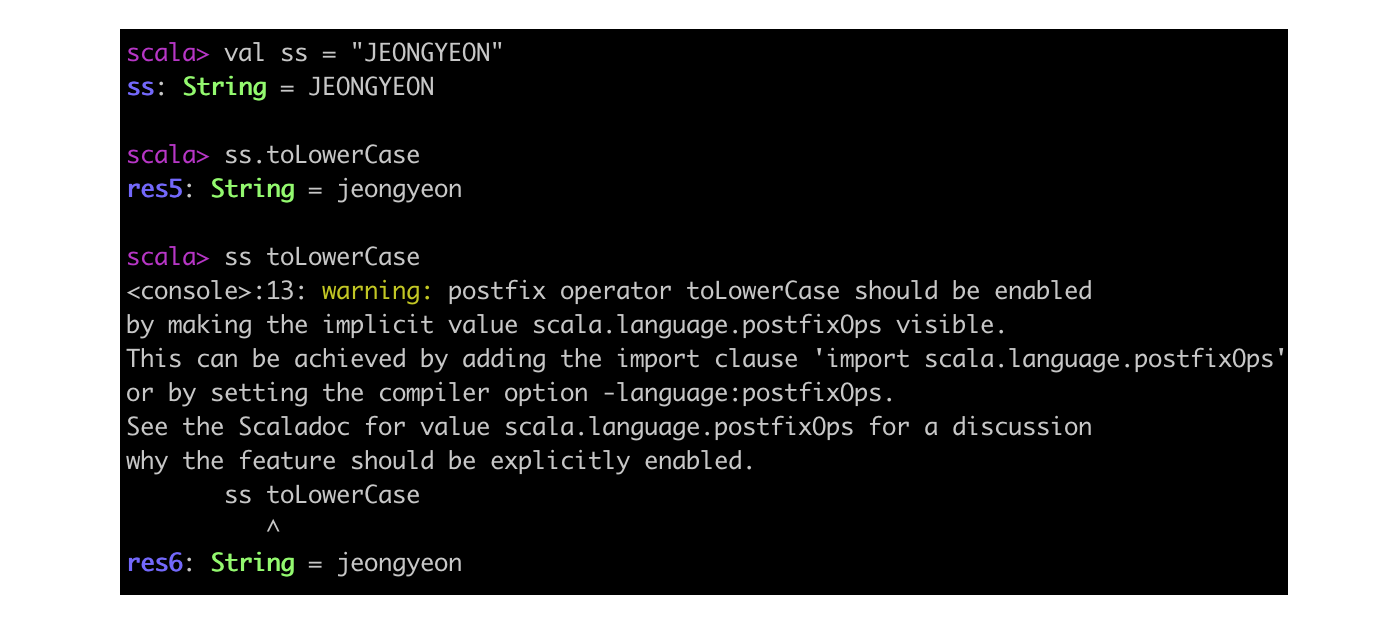
后缀操作符是那些不接收参数并且在调用时没有用英文句点圆括号的方法。在 Scala 中,可以在方法调用时省去空的圆括号。从约定俗成的角度讲,如果方法有副作用的时候保留空的圆括号,比如 println();,而在方法没有副作用时则可以省掉这组圆括号,比如对 String 调用 toLowerCase 时。在后一种不带参数的场景(无副作用)下,可以选择去掉句点, 使用后缀操作符表示法。如下,toLowerCase 被当作后缀操作符作用在了操作元 s 上。
示例:
object Test {
def main(args: Array[String]): Unit = {
val n = new MyNumber(1101)
n + 3
println(n.value)
n --
n ok
println(n.value)
~n
println(n.value)
}
}
class MyNumber(var value: Int) {
// 中置操作符
def +(that: Int): Unit = value += that
// 后置操作符
def -- = value -= 1
// 后置操作符
def ok = println("yesOk")
// 前置操作符
def unary_~ = value = value * (-1)
}
