21-Hive运算符&函数
1. Hive 内置运算符
整体上,Hive 支持的运算符可以分为三大类:关系运算、算术运算、逻辑运算。
官方参考文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
也可以使用下述方式查看运算符的使用方式:
-- 显示所有的函数和运算符
show functions;
-- 查看运算符或者函数的使用说明
describe function +;
-- 使用 extended 可以查看更加详细的使用说明
describe function extended +;
从 Hive 0.13.0 开始,select 查询语句 FROM 关键字是可选的(例如 SELECT 1+1),因此可以使用这种方式来练习测试内置的运算符、函数的功能。除此之外,还可以通过创建一张虚表 dual 来满足于测试需求。
-- 1、创建表 dual
create table dual(id string);
-- 2、加载一个文件dual.txt(内容为一个空格)到 dual 表中
-- 3、在 select 语句中使用 dual 表完成运算符、函数功能测试
select 1+1 from dual;
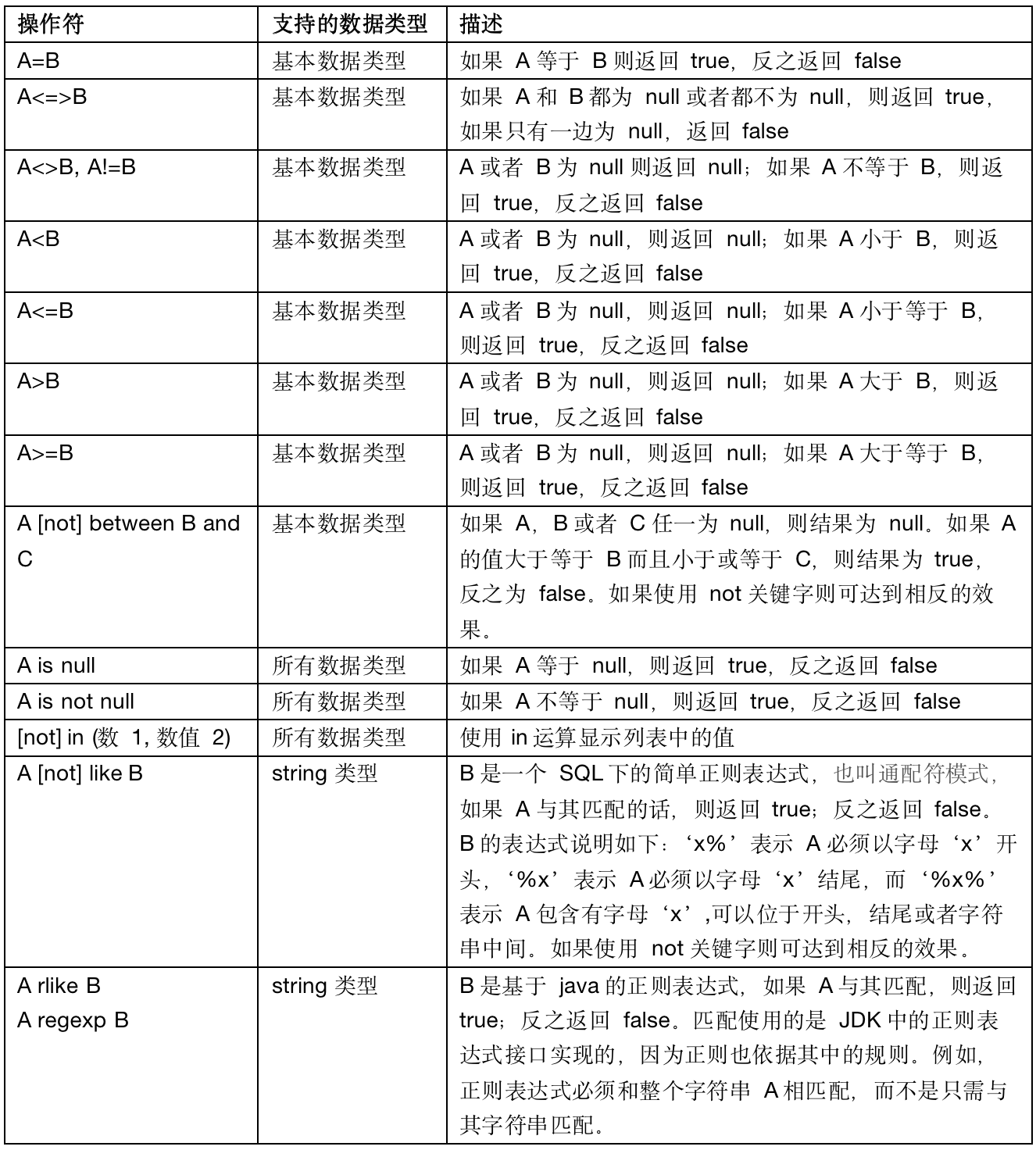
1.1 关系运算符
关系运算符是二元运算符,执行的是两个操作数的比较运算。每个关系运算符都返回 boolean 类型结果(TRUE/FALSE)。
示例:
select 1 from dual where 'tree' is null;
select 1 from dual where 'tree' is not null;
-- like:_ 表示任意单个字符、% 表示任意数量字符
select 1 from dual where 'tree' like 'tr_';
select 1 from dual where 'tree' like 'tr%';
select 1 from dual where 'tree' not like 'hadoo_';
select 1 from dual where not 'tree' like 'hadoo_';
-- rlike:确定字符串是否匹配正则表达式,是 REGEXP_LIKE() 的同义词
select 1 from dual where 'tree' rlike '^t.*e$';
select 1 from dual where '123456' rlike '^\\d+$';
select 1 from dual where '123456xy' rlike '^\\d+$';
-- regexp:功能与 rlike 相同,用于判断字符串是否匹配正则表达式
select 1 from dual where 'tree' regexp '^t.*e$';
1.2 算数运算符
算术运算符操作数必须是数值类型。分为一元运算符和二元运算符:一元运算符,只有一个操作数;二元运算符有两个操作数,运算符在两个操作数之间。
- 加法操作:+
- 减法操作:-
- 乘法操作:*
- 除法操作:/
- 取整操作:div
- 取余操作:%
- 位与操作:&
- 位或操作:|
- 位异或操作:^
- 位取反操作: ~
示例:
-- 取整操作: 给出将A除以B所得的整数部分,例如17 div 3得出5
select 17 div 3;
-- 取余操作: 也叫做取模,A除以B所得的余数部分
select 17 % 3;
-- 位与操作: A和B按位进行与操作的结果,与表示两个都为1则结果为1
select 4 & 8 from dual; -- 4转换二进制:0100 8转换二进制:1000
select 6 & 4 from dual; -- 4转换二进制:0100 6转换二进制:0110
-- 位或操作: A和B按位进行或操作的结果,或表示有一个为1则结果为1
select 4 | 8 from dual;
select 6 | 4 from dual;
-- 位异或操作: A和B按位进行异或操作的结果,异或表示两个不同则结果为1
select 4 ^ 8 from dual;
select 6 ^ 4 from dual;
1.3 逻辑运算符
- 与操作:A AND B
- 或操作:A OR B
- 非操作:NOT A 、!A
- 在:A IN (val1, val2, ...)
- 不在:A NOT IN (val1, val2, ...)
- 逻辑是否存在:[NOT] EXISTS (subquery)
示例:
-- 与操作: A AND B
select 1 from dual where 3>1 and 2>1;
-- 或操作: A OR B
select 1 from dual where 3>1 or 2!=2;
-- 非操作: NOT A 、!A
select 1 from dual where not 2>1;
select 1 from dual where !2=1;
-- 在: A IN (val1, val2, ...) 如果A等于任何值,则为TRUE。
select 1 from dual where 11 in (11,22,33);
-- 不在: A NOT IN (val1, val2, ...) 如果A不等于任何值,则为TRUE。
select 1 from dual where 11 not in (22,33,44);
-- 逻辑是否存在: [NOT] EXISTS (subquery)
-- 将主查询的数据放到子查询中做条件验证,根据验证结果(TRUE/FALSE)来决定主查询的数据结果是否得以保留。
select A.* from A
where exists (select B.id from B where A.id = B.id);
2. Hive 函数基础
Hive 内建了不少函数,用于满足用户不同使用需求,提高 SQL 编写效率:
- 使用
show functions查看当下可用的所有函数; - 通过
describe function extended <funcname>来查看函数的使用方式。
2.1 函数概述及分类标准
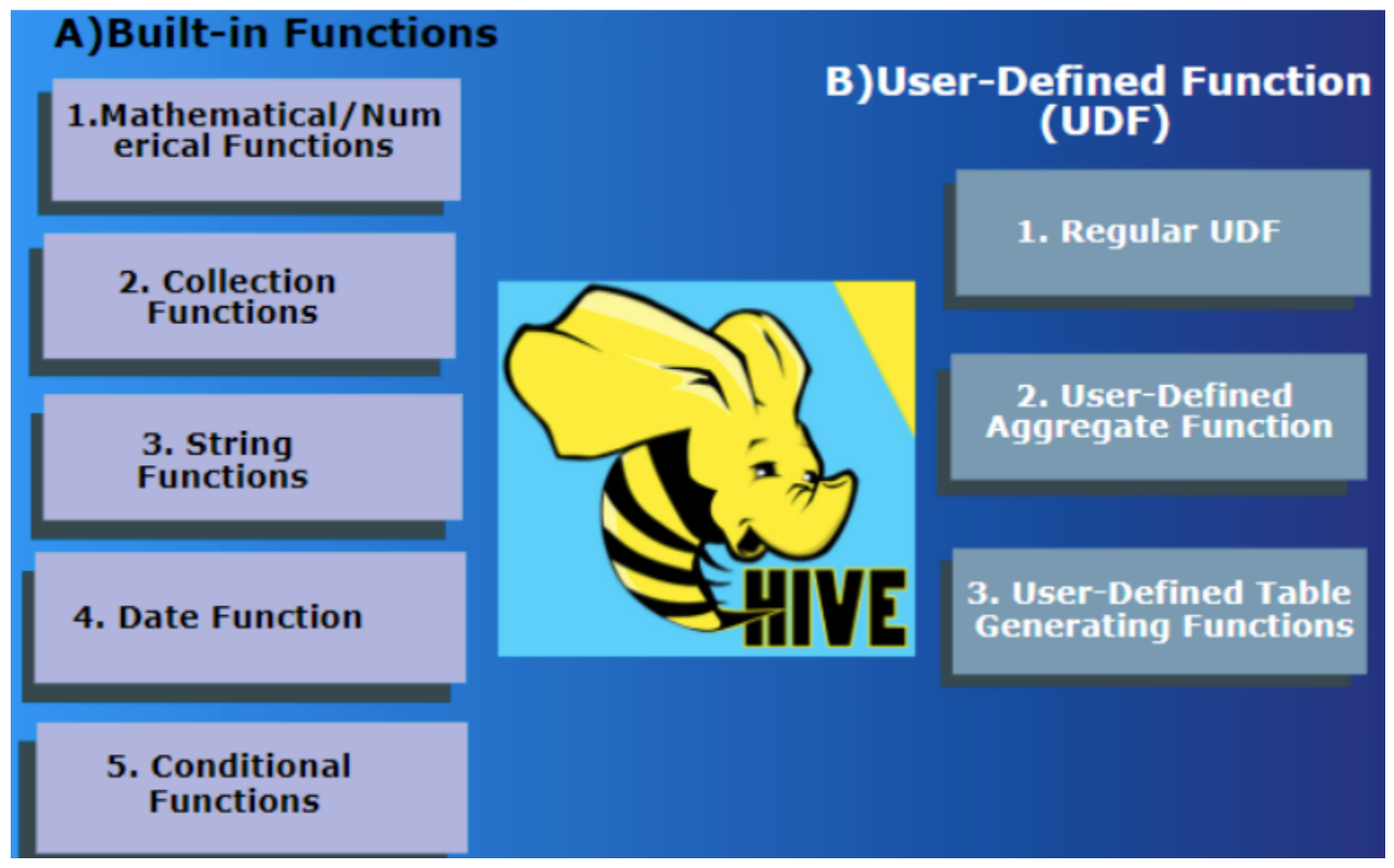
Hive 的函数分为两大类:内置函数(Built-in Functions)、用户定义函数 UDF(User-Defined Functions)
- 内置函数可分为:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等;
- 用户定义函数根据输入输出的行数可分为 3 类:UDF、UDAF、UDTF。
UDF 分类标准 — 根据函数输入输出的行数

- UDF(User-Defined-Function)普通函数,一进一出
- UDAF(User-Defined Aggregation Function)聚合函数,多进一出
- UDTF(User-Defined Table-Generating Functions)表生成函数,一进多出
UDF 分类标准 · 扩大化
UDF 分类标准本来针对的是用户自己编写开发实现的函数。UDF 分类标准可以扩大到 Hive 的所有函数中,包括「内置函数」和「用户自定义函数」。
因为不管是什么类型的函数,一定满足于输入输出的要求,那么从输入几行和输出几行上来划分没有任何问题。所以千万不要被 UD(User-Defined)这两个字母所迷惑,造成视野的狭隘!
比如 Hive 官方文档中,针对聚合函数的标准就是内置的 UDAF 类型。

2.2 Hive 内置函数
内置函数(Build-in)指的是 Hive 开发实现好,直接可以使用的函数,也叫做内建函数。
内置函数根据应用归类整体可以分为 8 大类,我们将对其中重要的、使用频率高的函数使用进行详细讲解。
a. 字符串函数

示例:
describe function extended find_in_set;
select find_in_set('Jeongyeon', 'Nayeon,Jeongyeon,MoMo,Sana,Jihyo');
-- 字符串长度函数:length(str | binary)
select length('jeongyeon');
-- 字符串反转函数:reverse
select reverse('jeongyeon');
-- 字符串连接函数:concat(str1, str2, ... strN)
select concat('nayeon', 'jeongyeon');
-- 带分隔符字符串连接函数:concat_ws(separator, [string | array(string)]+)
select concat_ws('.', 'www', array('tree6x7', 'io'));
-- 字符串截取函数:substr(str, pos[, len]) 或 substring(str, pos[, len])
-- pos是从1开始的索引,如果为负数则倒着数
select substr('jeongyeon', -2);
select substr('jeongyeon', 2, 2);
-- 字符串转大写函数:upper,ucase
select upper('jeongyeon');
select ucase('jeongyeon');
-- 字符串转小写函数:lower,lcase
select lower('JEONGYEON');
select lcase('JEONGYEON');
-- 去空格函数:trim 去除左右两边的空格
select trim(' jeongyeon ');
-- 左边去空格函数:ltrim
select ltrim(' jeongyeon ');
-- 右边去空格函数:rtrim
select rtrim(' jeongyeon ');
-- 字符串A中的子字符串B(全局)替换为C
select replace('jeongyeon', 'o', 'O')
-- 字符串是否符合正则表达式
select 'dfsaaaa' regexp 'dfsa+'
-- 正则表达式替换函数:regexp_replace(str, regexp, rep)
select regexp_replace('100-200', '(\\d+)', 'num');
-- 正则表达式解析函数:regexp_extract(str, regexp[, idx]) 提取正则匹配到的指定组内容
select regexp_extract('100-200', '(\\d+)-(\\d+)', 2);
-- URL解析函数:parse_url 注意要想一次解析出多个 可以使用parse_url_tuple这个UDTF函数
select parse_url('http://www.tree6x7.io/path/p1.php?query=1', 'HOST');
-- 空格字符串函数:space(n) 返回指定个数空格
select space(4);
-- 重复字符串函数:repeat(str, n) 重复str字符串n次
select repeat('angela', 2);
-- 首字符ascii函数:ascii
select ascii('angela');
-- 替换null值:若A的值不为null,则返回A,否则返回B。
select nvl(null, 1);
-- 左补足函数:lpad
select lpad('hi', 5, '????????'); -- ???hi
select lpad('hi', 1, '??');
-- 右补足函数:rpad
select rpad('hi', 5, '??');
-- 分割字符串函数: split(str, regex)
select split('apache hive', '\\s+');
-- 集合查找函数: find_in_set(str,str_array)
select find_in_set('a', 'abc,b,ab,c,def');
-- 分割字符串函数: split(str, regex)
select split('apache hive', '\\s+');
-- json解析函数:get_json_object(json_txt, path)
select get_json_object(
'[{"website":"www.tree6x7.io","name":"liujiaqi"}, {"website":"cloud.tree6x7.io","name":"carbondata 中文文档"}]',
'$.[1].name'); -- $表示json对象
b. 日期函数

示例:
-- 获取当前UNIX零时区的时间戳: unix_timestamp
select unix_timestamp();
-- 日期转UNIX零时区的时间戳: unix_timestamp
select unix_timestamp('2011-12-07 13:01:03');
-- 指定格式日期转UNIX零时区的时间戳: unix_timestamp
select unix_timestamp('20111207 13:01:03', 'yyyyMMdd HH:mm:ss');
-- UNIX时间戳转日期函数: (从 1970-01-01 00:00:00 UTC 到指定时间的秒数)到零时区的时间格式
select from_unixtime(1618238391);
select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss');
-- 补充:from_utc_timestamp(ts, timezone)|to_utc_timestamp(ts, timezone)
select from_utc_timestamp(cast(1659946088 as bigint)*1000, 'GMT+8');
-- 获取当前时间戳 current_timestamp(考虑到系统当前时区)
-- 同一查询中对current_timestamp的所有调用均返回相同的值
select current_timestamp();
-- 获取当前日期
select current_date();
-- 日期比较函数: datediff 日期格式要求'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd',且 param1-param2
select datediff('2012-12-08', '2012-05-09');
-- 日期增加函数: date_add
select date_add('2012-02-28', 10);
-- 日期减少函数: date_sub
select date_sub('2012-01-1', 10);
-- 抽取日期函数: to_date
select to_date('2009-07-30 04:17:52');
-- 日期转年函数: year
select year('2009-07-30 04:17:52');
-- 日期转月函数: month
select month('2009-07-30 04:17:52');
-- 日期转天函数: day
select day('2009-07-30 04:17:52');
-- 日期转小时函数: hour
select hour('2009-07-30 04:17:52');
-- 日期转分钟函数: minute
select minute('2009-07-30 04:17:52');
-- 日期转秒函数: second
select second('2009-07-30 04:17:52');
-- 日期转周函数: weekofyear 返回指定日期所示年份第几周
select weekofyear('2009-07-30 04:17:52');
-- 将标准日期解析成指定格式字符串: date_format
select date_format('2023-07-24','yyyy年-MM月-dd日')
c. 数学函数

示例:
-- 取整函数: round 返回double类型的整数值部分(遵循四舍五入)
select round(3.1415926);
-- 指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926, 4);
-- 向下取整函数: floor
select floor(3.1415926);
select floor(-3.1415926);
-- 向上取整函数: ceil
select ceil(3.1415926);
select ceil(-3.1415926);
-- 取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
-- 指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);
-- 二进制函数: bin(BIGINT a)
select bin(18);
-- 进制转换函数: conv(BIGINT num, int from_base, int to_base)
select conv(17, 10, 16);
-- 绝对值函数: abs
select abs(-3.9);
d. 集合函数

示例:
-- 声明array的函数: array(val1, val2, ...) 根据输入的参数构建数组
select array('1', '2', '3', '4');
-- 声明map的函数: map(key1, val1, key2, val2, ...)
select map('a', 1, 'b', 2, 'c', 3);
-- 声明struct的属性和值: named_struct(...)
select named_struct('name','liujiaqi', 'age',25, 'weight',80);
-- 集合元素size函数: size(Map<K.V>) size(Array<T>)
select size(`array`(11, 22, 33));
select size(`map`('id', 10086, 'name', 'zhangsan', 'age', 18));
-- 取map集合keys函数: map_keys(Map<K.V>),返回数组
select map_keys(`map`('id', 10086, 'name', 'zhangsan', 'age', 18));
-- 取map集合values函数: map_values(Map<K.V>),返回数组
select map_values(`map`('id', 10086, 'name', 'zhangsan', 'age', 18));
-- 判断数组是否包含指定元素: array_contains(Array<T>, value)
select array_contains(`array`(11, 22, 33), 11);
select array_contains(`array`(11, 22, 33), 66);
-- 数组排序函数: sort_array(Array<T>)
select sort_array(`array`(12, 2, 32));
e. 条件函数

示例:
-- 使用之前创建好的student表数据
select *
from student
limit 3;
describe function extended isnull;
-- if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1 = 2, 100, 200);
select if(sex = '男', 'M', 'W')
from student
limit 3;
-- 空判断函数: isnull( a )
select isnull('tree');
select isnull(null);
-- 非空判断函数: isnotnull ( a )
select isnotnull('tree');
select isnotnull(null);
-- 空值转换函数: nvl(T value, T default_value)
select nvl('tree', 'ljq');
select nvl(null, 'ljq');
-- 非空查找函数: COALESCE(T v1, T v2, ...) 返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL
select COALESCE(null, 11, 22, 33);
select COALESCE(null, null, null, 33);
select COALESCE(null, null, null);
-- 条件转换函数: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
select case sex when '男' then 'male' else 'female' end
from student
limit 3;
-- nullif( a, b ): 如果a = b,则返回NULL,否则返回一个
select nullif(11, 11);
select nullif(11, 12);
-- assert_true(condition) 如果'condition'不为真,则引发异常,否则返回null
SELECT assert_true(11 >= 0);
SELECT assert_true(-1 >= 0);
f. 类型转换函数
主要用于显式的数据类型转换:
-- 任意数据类型之间转换 cast
select cast(12.14 as bigint);
select cast(12.14 as string);
select cast('hello' as int);
g. 数据脱敏函数
主要完成对数据脱敏转换功能,屏蔽原始数据,主要如下:

示例:
-- mask
-- 默认是将查询回的数据,大写字母转换为 X,小写字母转换为 x,数字转换为 n。
select mask('abc123DEF');
-- 自定义替换的字母
select mask('abc123DEF', '-', '.', '^');
-- mask_first_n(string str[, int n]
-- 对前n个进行脱敏替换
select mask_first_n('abc123DEF', 4);
-- mask_last_n(string str[, int n])
select mask_last_n('abc123DEF', 4);
-- mask_show_first_n(string str[, int n])
-- 除了前n个字符,其余进行掩码处理
select mask_show_first_n('abc123DEF', 4);
-- mask_show_last_n(string str[, int n])
select mask_show_last_n('abc123DEF', 4);
-- mask_hash(string|char|varchar str)
-- 返回字符串的hash编码
select mask_hash('abc123DEF');
h. 其他杂项函数

示例:
-- 如果你要调用的Java方法所在的jar包不是Hive自带的,可以使用 add jar 添加进来
-- Hive调用Java方法: java_method(class, method[, arg1[, arg2..]])
select java_method('java.lang.Math', 'max', 11, 22);
-- 反射函数: reflect(class, method[, arg1[, arg2..]])
select reflect('java.lang.Math', 'max', 11, 22);
-- 取哈希值函数: hash
select hash('allen');
-- current_user()、logged_in_user()、current_database()、version()
-- SHA-1加密: sha1(string/binary)
select sha1('allen');
-- SHA-2家族算法加密: sha2(string/binary, int) (SHA-224, SHA-256, SHA-384, SHA-512)
select sha2('allen', 224);
select sha2('allen', 512);
-- crc32加密
select crc32('allen');
-- MD5加密: md5(string/binary)
select md5('allen');
-- 补充聚合函数
-- collect_list: 收集并形成list集合,结果不去重
select sex, collect_list(job) from employee group by sex;
-- collect_set: 收集并形成set集合,结果去重
select sex, collect_set(job) from employee group by sex;
2.3 Hive 用户自定义函数
虽然说 Hive 内置了很多函数,但是不见得一定可以满足于用户各种各样的分析需求场景。为了解决这个问题,Hive 推出来用户自定义函数功能,让用户实现自己希望实现的功能函数。
用户自定义函数简称 UDF,源自于英文 User-Defined Function。自定义函数总共有 3 类,是根据函数输入输出的行数来区分的,分别是:
(1)UDF 普通函数
UDF 函数通常被叫做普通函数,最大的特点是一进一出,也就是输入一行输出一行。比如 round 取整函数,接收一行数据,输出的还是一行数据。
(2)UDAF 聚合函数
UDAF 函数通常把它叫做聚合函数,A 所代表的单词就是 Aggregation 聚合的意思。最大的特点是多进一出,也就是输入多行输出一行。比如 count、sum 这样的函数。
-- count 统计检索到的总行数
-- sum 求和
-- avg 求平均
-- min 最小值
-- max 最大值
-- collect_set(col) 数据收集函数(去重)
-- collect_list(col) 数据收集函数(不去重)
select collect_set(sex) from student_local;
-- ["男","女"]
select collect_list(sex) from student_local;
-- ["男","女","女","男","男","男","女","女","女","男","男","女","男","女","男","男","女","女","女","男","男","男"]
(3)UDTF 表生成函数
UDTF 函数通常把它叫做表生成函数,T 所代表的单词是 Table-Generating 表生成的意思。最大的特点是一进多出,也就是输入一行输出多行。之所以叫做表生成函数,原因在于这类型的函数作用返回的结果类似于表(多行数据嘛),同时 UDTF 函数也是我们接触比较少的函数。
2.4 案例: 手机号加密
a. 需求描述
在企业中处理数据的时候,对于敏感数据往往需要进行脱敏处理。比如手机号。我们常见的处理方式是将手机号中间 4 位进行 **** 处理。
Hive 中没有这样的函数可以直接实现功能,虽然可以通过各种函数的嵌套调用最终也能实现,但是效率不高,现要求自定义开发实现 Hive 函数,满足上述需求。
- 能够对输入数据进行非空判断、手机号位数判断;
- 能够实现校验手机号格式,把满足规则的进行处理;
- 对于不符合手机号规则的数据直接返回,不处理。
b. 实现步骤
- 写一个 Java 类,继承 UDF,并重载 evaluate 方法,在方法中实现函数的业务逻辑;
- 重载意味着可以在一个 Java 类中实现多个函数功能;
- 程序打成 jar 包,上传 HS2 服务器本地或者 HDFS;
- 客户端命令行中添加 jar 包到 Hive 的 classpath:
add JAR /.../xxx.jar; - 注册成为临时函数(给 UDF 命名):
create temporary function 函数名 as 'UDF类全路径'; - HQL 中使用函数。
c. 具体实现
(1)新建 Maven 项目 · pom 依赖
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hive-udf</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
(2)编写业务代码 · UDF 类
package org.example.udf;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author tree6x7
* @description Hive自定义函数UDF 实现对手机号中间4位进行****加密
* @createTime 2023/7/14
*/
public class EncryptPhoneNumber extends UDF {
/**
* 重载evaluate方法 实现函数的业务逻辑
*
* @param phoNum 未加密手机号
* @return 加密后的手机号字符串
*/
public String evaluate(String phoNum) {
String encryptPhoNum = null;
// 手机号不为空 并且为11位
if (StringUtils.isNotEmpty(phoNum) && phoNum.trim().length() == 11) {
// 判断数据是否满足中国大陆手机号码规范
String regex = "^(1[3-9]\\d{9}$)";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(phoNum);
// 进入这里都是符合手机号规则的
if (m.matches()) {
// 使用正则替换 返回加密后数据 被'()'包起来的才算一组
encryptPhoNum = phoNum.trim().replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2");
} else {
// 不符合手机号规则 数据直接原封不动返回
encryptPhoNum = phoNum;
}
} else {
// 不符合11位 数据直接原封不动返回
encryptPhoNum = phoNum;
}
return encryptPhoNum;
}
}
(3)IDEA 中使用集成的 Maven 插件进行打包,这里会把依赖一起打入 jar 包;
(4)把 jar 包上传到 Hiveserver2 服务运行所在机器的 Linux 系统,上传 HDFS 文件系统也可以,后续路径指定清楚即可;
(5)在客户端中使用命令把 jar 包添加至 classpath;
0: jdbc:hive2://hadoop102:10000> add jar /home/liujiaqi/hive-udf-1.0-SNAPSHOT.jar
(6)注册临时函数(通俗来说就是给用户编写的函数起个名字);
0: jdbc:hive2://hadoop102:10000> create temporary function encrypt_phonenum as 'org.example.udf.EncryptPhoneNumber';
(7)注册成功,使用 UDF。
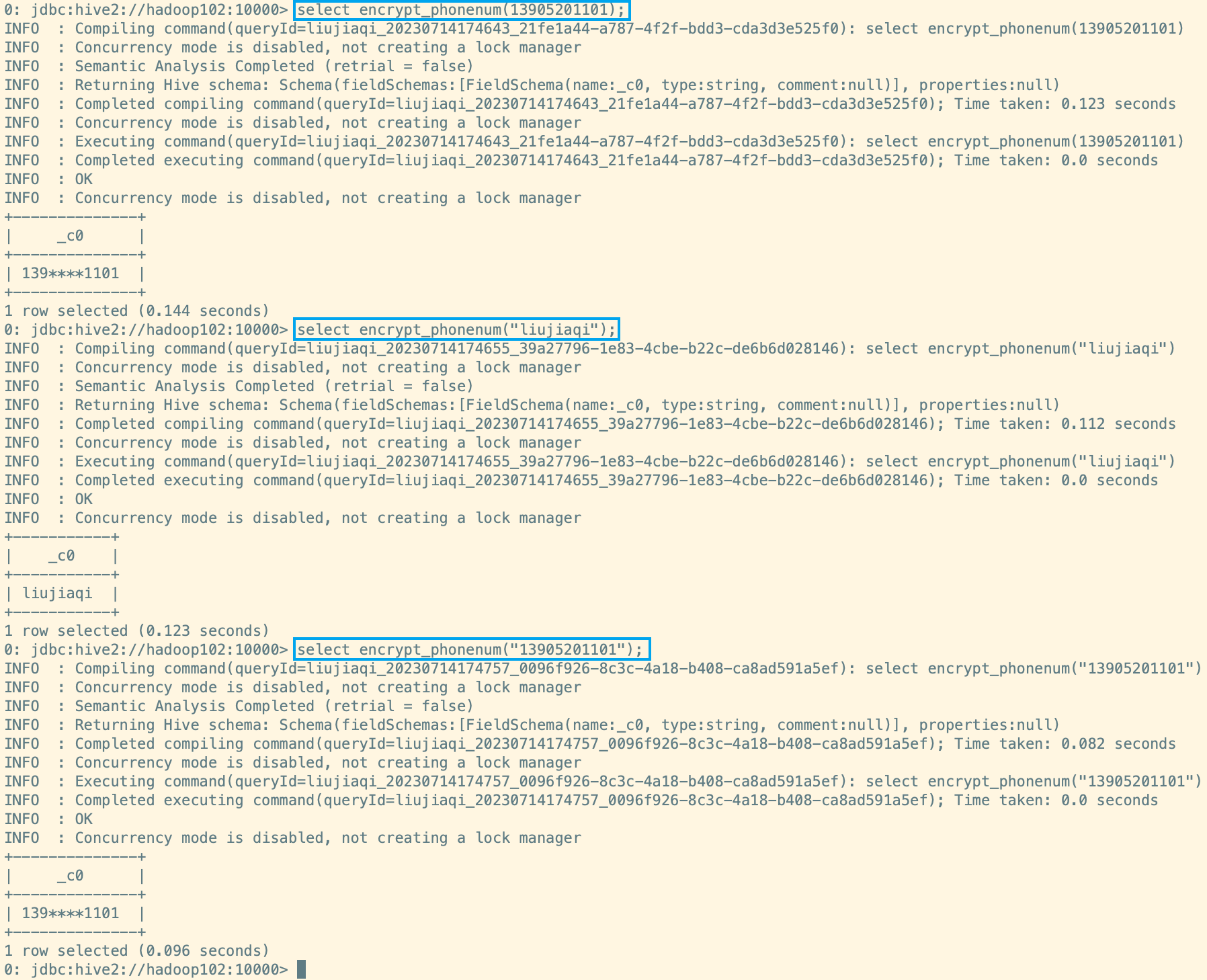
(8)删除临时函数
0: jdbc:hive2://hadoop102:10000> drop temporary function encrypt_phonenum;
【注】临时函数只跟会话有关系,跟库没有关系。只要创建临时函数的会话不断,在当前会话下,任意一个库都可以使用,其他会话全都不能使用。
d. 注册函数2
上面案例的实现方式是「临时注册」,还可以创建永久函数。
- 永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用;
- 永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上;
- 永久函数使用的时候,需要在指定的库里面操作,或者在其他库里面使用的话加上“库名.”。
操作如下:
(1)创建永久函数
因为 add jar 本身也是临时生效,所以在创建永久函数的时候,需要制定路径(并且因为元数据的原因,这个路径还得是 HDFS 上的路径)。
create function my_len2
as "com.atguigu.hive.udf.MyUDF"
using jar "hdfs://hadoop102:8020/udf/myudf.jar";
(2)即可在 HQL 中使用自定义的永久函数
select
ename,
my_len2(ename) ename_len
from emp;
(3)删除永久函数
drop function my_len2;
3. Hive 函数高阶
3.1 UDTF · explode 函数
a. 功能
对于 UDTF 表生成函数,很多人难以理解什么叫做输入一行,输出多行。
为什么叫做表生成?能够产生表吗?
下面就来看下 Hive 内置的一个非常著名的 UDTF 函数,名字叫做 explode 函数,中文戏称之为“爆炸函数”,可以炸开数据。
explode 函数接收 map 或 array 类型的数据作为参数,然后把参数中的每个元素炸开变成一行数据。一个元素一行。这样的效果正好满足于输入一行输出多行。
explode 函数在关系型数据库中本身是不该出现的。因为他的出现本身就是在操作不满足第一范式的数据(每个属性都不可再分)。本身已经违背了数据库的设计原理,但是在面向分析的数据库或者数据仓库中,这些规范可以发生改变。

b. 语法
一般情况下,explode 函数直接使用即可,也可以根据需要结合 Lateral View 侧视图使用。
explode(array)将 array 列表里的每个元素生成一行;explode(map)将 map 里的每一对元素作为一行,其中 key 为一列,value 为一列。posexplode(array)将 explode 的每行结果还附带索引;inline(ARRAY<STRUCT<f1:T1,...,fn:Tn>>)结构体列表中每个结构体生成一行(属性名对应成列名)
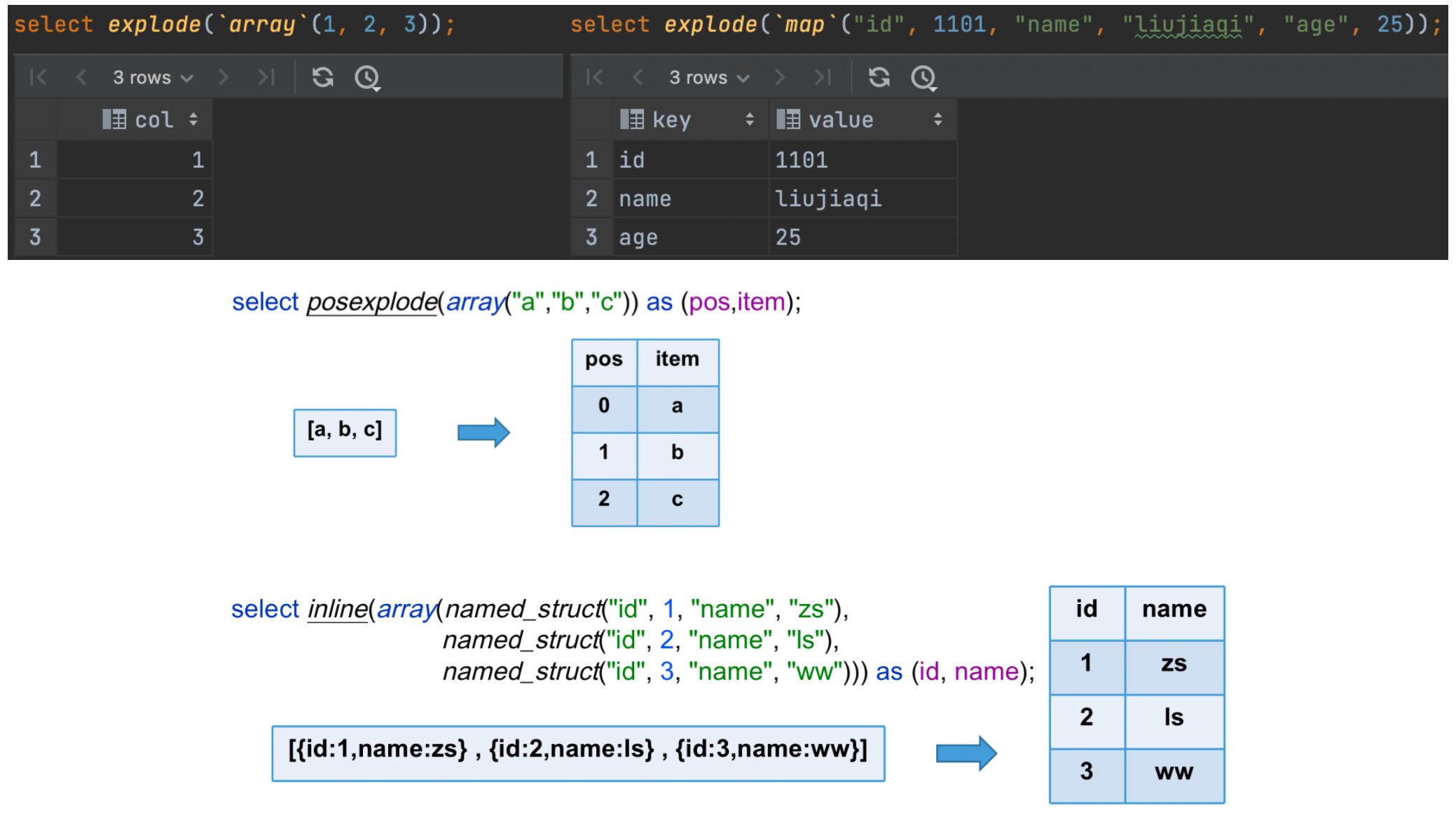
c. 案例
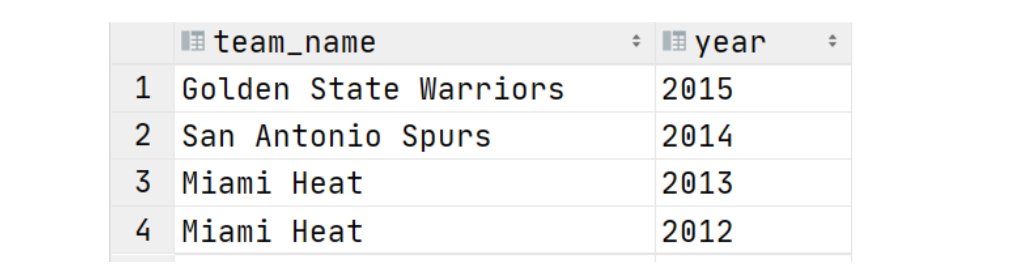
有一份数据 The_NBA_Championship.txt,关于部分年份的 NBA 总冠军球队名单:

第 1 个字段表示的是球队名称,第 2 个字段是获取总冠军的年份,字段之间以 , 分割;获取总冠军年份之间以 | 进行分割。
使用 Hive 建表映射数据并对数据拆分,要求拆分之后数据如下所示并根据年份倒序排序:
(1)建表
create table the_nba_championship
(
team_name string,
champion_year array<string>
) row format delimited
fields terminated by ','
collection items terminated by '|';
(2)加载数据文件到表中
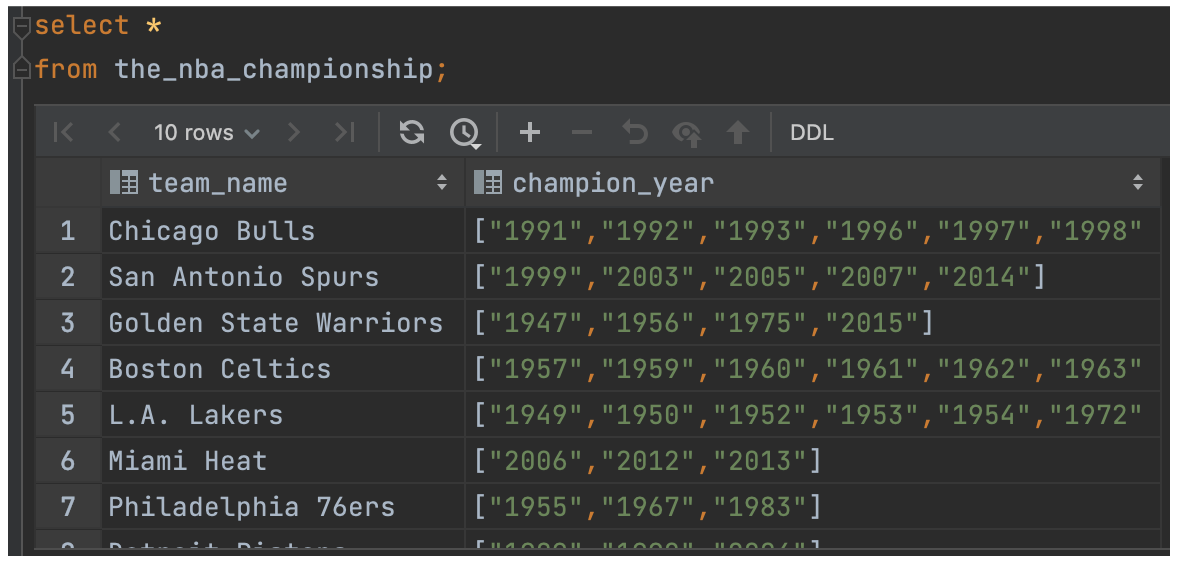
load data local inpath '/home/liujiaqi/hivedata/The_NBA_Championship.txt' into table the_nba_championship;
(3)验证数据是否加载成功
(4)使用 explode 函数对 champion_year 进行拆分

(5)explode 使用限制
在 select 条件中,如果只有 explode 函数表达式,程序执行是没有任何问题的。但是如果在 select 条件中,除了 explode 外还包含其他字段,就会报错:org.apache.hadoop.hive.ql.parse.SemanticException:UDTF's are not supported outside the SELECT clause, nor nested in expressions。
如何理解这个错误呢?为什么在 select 的时候,explode 的旁边不支持其他字段的同时出现?
【原因】explode 函数属于 UDTF 表生成函数,explode 执行返回的结果可以理解为一张虚拟的表,其数据来源于源表。在 select 中只查询源表数据没有问题,只查询 explode 生成的虚拟表数据也没问题。但不能在只查询源表的时候,想既返回源表字段又返回 explode 生成的虚拟表字段。通俗点讲就是,有两张表,不能只查一张表却又想返回分别属于两张表的字段。
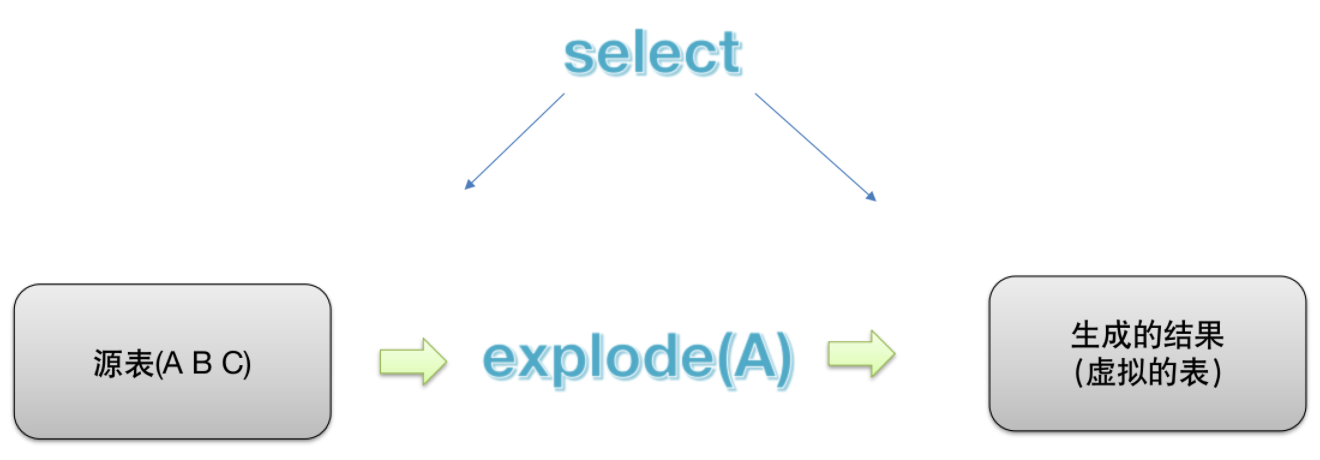
【解决】从 SQL 层面上来说上述问题的解决方案是:对两张表进行 join 关联查询。Hive 专门提供了语法 Lateral View 侧视图,专门用于搭配 explode 这样的 UDTF 函数,以满足上述需要。
select ... from 源表 lateral view UDTF(要炸开的字段名) 虚表别名 as 炸开后的字段别名;
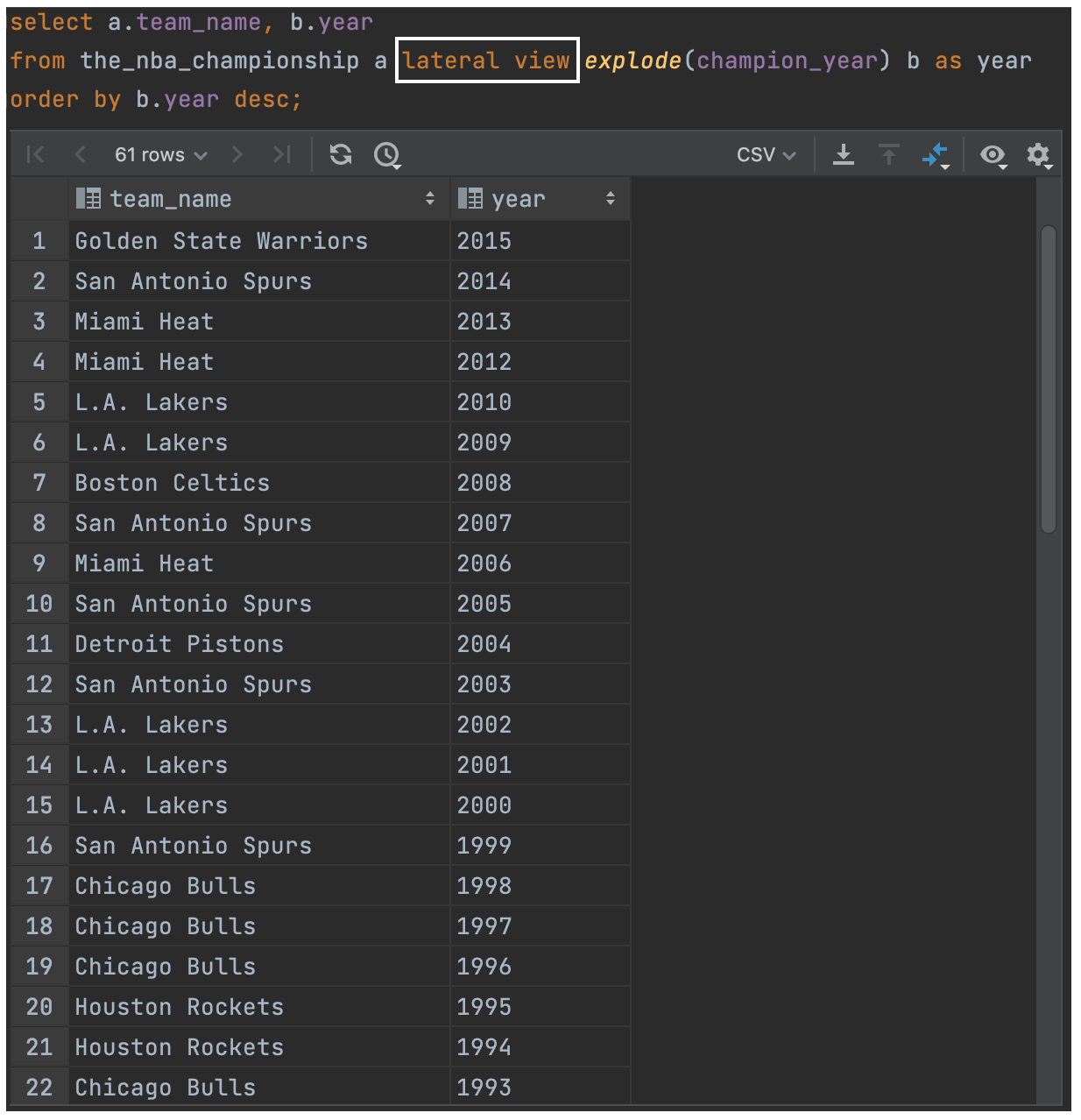
(6)explode + lateral view
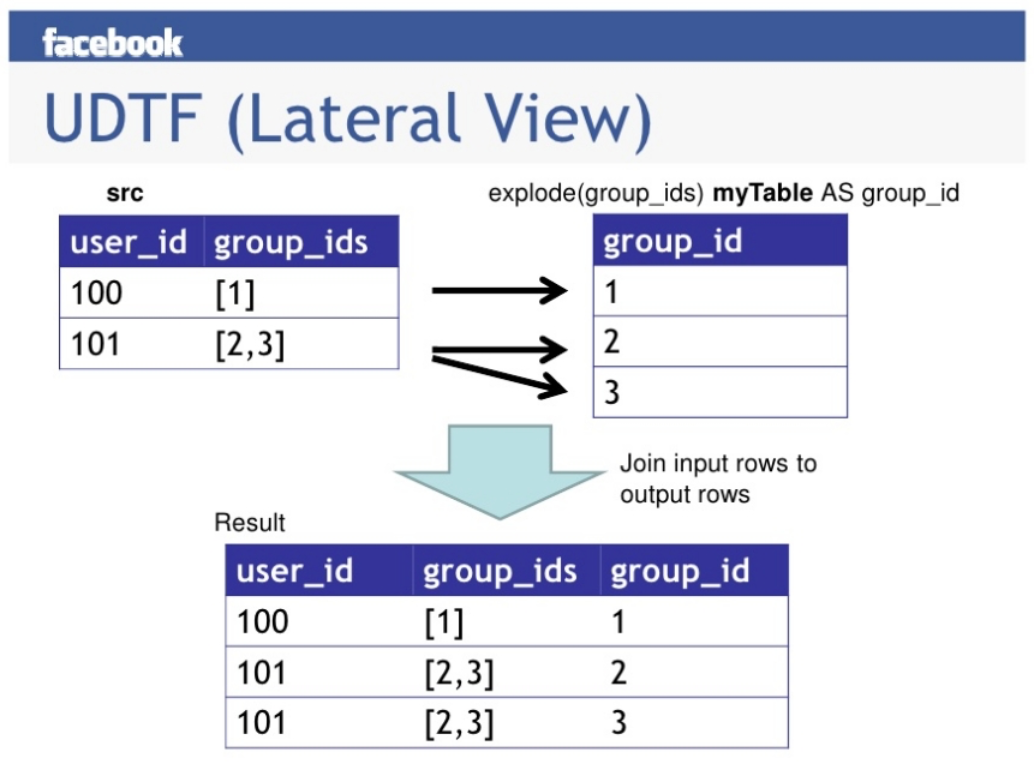
3.2 Lateral View 侧视图
Lateral View 是一种特殊的语法,主要用于搭配 UDTF 类型功能的函数一起使用,用于解决 UDTF 函数的一些查询限制的问题。
侧视图的原理是将 UDTF 的结果构建成一个类似于视图的表,然后将原表中的每一行和 UDTF 函数输出的每一行进行连接,生成一张新的虚拟表。这样就避免了 UDTF 的使用限制问题。
使用 Lateral View 时也可以对 UDTF 产生的记录设置字段名称,产生的字段可以用于 group by、order by 、limit 等语句中,不需要再单独嵌套一层子查询。一般只要使用 UDTF,就会固定搭配 Lateral View 使用。
官方链接:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LateralView
针对上述 NBA 冠军球队年份排名案例,使用 explode 函数 + Lateral View 侧视图,可以完美解决:
-- select ... from 源表 lateral view UDTF(要炸开的字段名) 虚表别名 as 炸开后的字段别名;
-- 根据年份倒序排序
select a.team_name, b.year
from the_nba_championship a lateral view explode(champion_year) b as year
order by b.year desc;
-- 统计每个球队获取总冠军的次数并根据倒序排序
select a.team_name, count(*) as nums
from the_nba_championship a lateral view explode(champion_year) b as year
group by a.team_name
order by nums desc;
3.3 Aggregation 聚合函数
聚合函数的功能是:对一组值执行计算并返回单一的值。
聚合函数是典型的输入多行输出一行,使用 Hive 的分类标准,属于 UDAF 类型函数。
通常搭配 Group By 语法一起使用,分组后进行聚合操作。
a. 基础聚合
HQL 提供了几种内置的 UDAF 聚合函数,例如 max/min/avg ... 这些我们把它称之为基础的聚合函数。
通常情况下聚合函数会与 GROUP BY 子句一起使用。如果未指定 GROUP BY 子句,默认情况下,它会汇总所有行数据。
(1)测试数据准备
-- 建表
create table student
(
num int,
name string,
sex string,
age int,
dept string
) row format delimited fields terminated by ',';
-- 加载
load data local inpath '/home/liujiaqi/hivedata/students.txt' into table student;
-- 验证
select * from student;
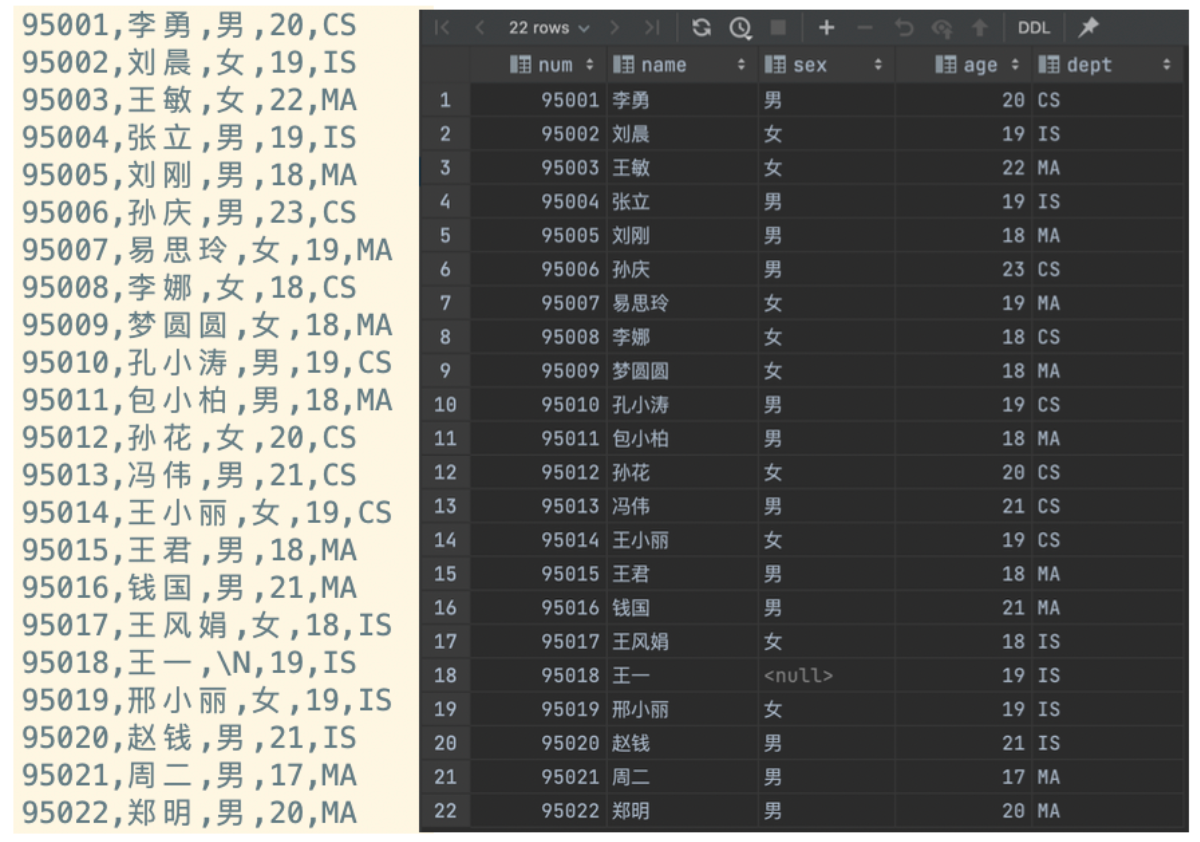
(2)聚合函数·示例
-- 场景1:没有 group by 子句的聚合操作
-- count(*) 所有行进行统计,包括NULL行
-- count(1) 所有行进行统计,包括NULL行
-- count(column) 对column中!NULL进行统计
select count(*) as cnt1, count(1) as cnt2 from student;
select count(sex) as cnt3 from student;
-- 场景2:带有 group by 子句的聚合操作 注意 group by 语法限制
select sex, count(*) as cnt from student group by sex;
-- 场景3:select 时多个聚合函数一起使用
select count(*) as cnt1, avg(age) as cnt2 from student;
-- 场景4:聚合函数和 case&when 条件转换函数、coalesce 函数、if 函数使用
select sum(CASE WHEN sex = '男' THEN 1 ELSE 0 END) from student;
select sum(if(sex = '男', 1, 0)) from student;
-- 场景5:聚合参数不支持嵌套聚合函数
-- select avg(count(*)) from student;
-- 场景6:聚合操作时针对 NULL 的处理
CREATE TABLE tmp_1
(
val1 int,
val2 int
);
INSERT INTO TABLE tmp_1 VALUES (1, 2), (null, 2), (2, 3);
-- 第二行数据 (NULL, 2) 在进行 sum(val1 + val2) 的时候会被忽略
select sum(val1), sum(val1 + val2) from tmp_1; -- output: 3 8
-- 可以使用 coalesce 函数解决
select sum(coalesce(val1, 0)),
sum(coalesce(val1, 0) + val2)
from tmp_1;
-- 场景7:配合 distinct 关键字去重聚合
-- 此场景下,会编译期间会自动设置只启动一个 reduce task 处理数据,可能造成数据拥堵。
select count(distinct sex) as cnt1
from student;
-- 可以先去重再聚合,通过子查询完成。因为先执行 distinct 的时候,可以使用多个 reduce task 来跑数据。
select count(*) as gender_uni_cnt
from (select distinct sex from student) a;
-- 场景8:找出 student 中男女学生年龄最大的及其名字
-- 这里使用了 struct 来构造数据,然后针对 struct 应用 max 找出最大元素,然后取值。
select struct(age, name) from student;
select struct(age, name).col1 from student;
select max(struct(age, name)) from student;
select sex,
max(struct(age, name)).col1 as age,
max(struct(age, name)).col2 as name
from student
group by sex;
b. 增强聚合
增强聚合包括 grouping_sets、cube、rollup 这几个函数。主要适用于 OLAP 多维数据分析模式中,多维分析中的维指的分析问题时看待问题的维度、角度。
下面通过案例更好的理解函数的功能含义(字段:月份、天、用户标识 cookieid)。

(1)GROUPING SETS
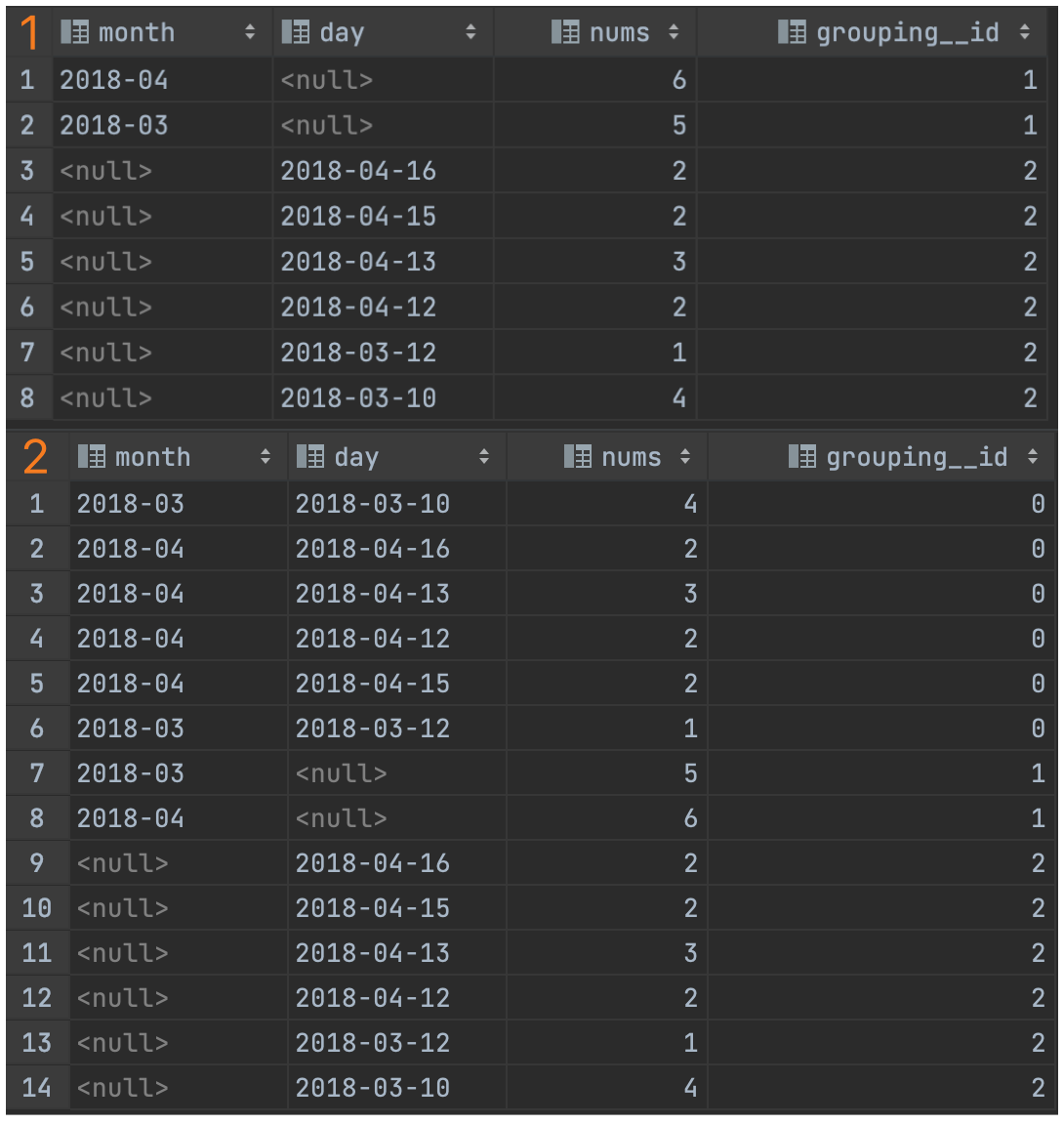
GROUPING SETS 是一种将多个 GROUP BY 逻辑写在一个 sql 语句中的便利写法。等价于将不同维度的 GROUP BY 结果集进行 UNION ALL。
GROUPING__ID 表示结果属于哪一个分组集合。
-- 示例1
-- GROUPING__ID 表示这一组结果属于哪个分组集合,根据 GROUPING SETS 中的分组条件 month,day,id=1 是代表 month,id=2 是代表 day。
SELECT month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month, day
GROUPING SETS ( month, day )
ORDER BY GROUPING__ID;
-- ||
SELECT month, NULL as day, COUNT(DISTINCT cookieid) AS nums, 1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL as month, day, COUNT(DISTINCT cookieid) AS nums, 2 AS GROUPING__ID FROM cookie_info GROUP BY day;
-- 示例2
SELECT month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month, day
GROUPING SETS ( month, day, (month, day) )
ORDER BY GROUPING__ID;
-- ||
SELECT month, NULL, COUNT(DISTINCT cookieid) AS nums, 1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL, day, COUNT(DISTINCT cookieid) AS nums, 2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month, day, COUNT(DISTINCT cookieid) AS nums, 3 AS GROUPING__ID FROM cookie_info GROUP BY month, day;
查询结果:
(2)CUBE
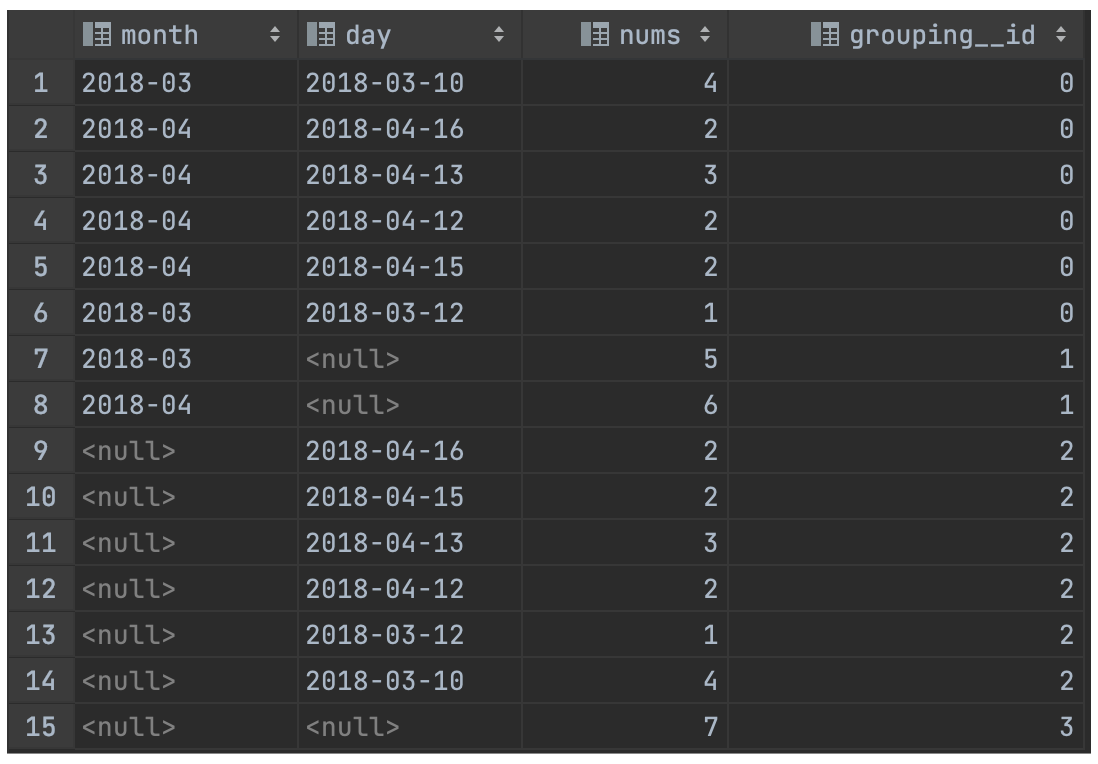
CUBE 表示根据 GROUP BY 的维度的所有组合进行聚合。
对于 CUBE 来说,如果有 N 个维度,则所有组合的总个数是:2^N。比如 cube 有 a,b,c 三个维度,则所有组合情况是:(a,b,c),(a,b),(b,c),(a,c),(a),(b),(c),()。
SELECT month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month, day
WITH CUBE
ORDER BY GROUPING__ID;
-- ||
SELECT NULL, NULL, COUNT(DISTINCT cookieid) AS nums, 0 AS GROUPING__ID FROM cookie_info
UNION ALL
SELECT month, NULL, COUNT(DISTINCT cookieid) AS nums, 1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL, day, COUNT(DISTINCT cookieid) AS nums, 2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month, day, COUNT(DISTINCT cookieid) AS nums, 3 AS GROUPING__ID FROM cookie_info GROUP BY month, day;
查询结果:
(3)ROLLUP
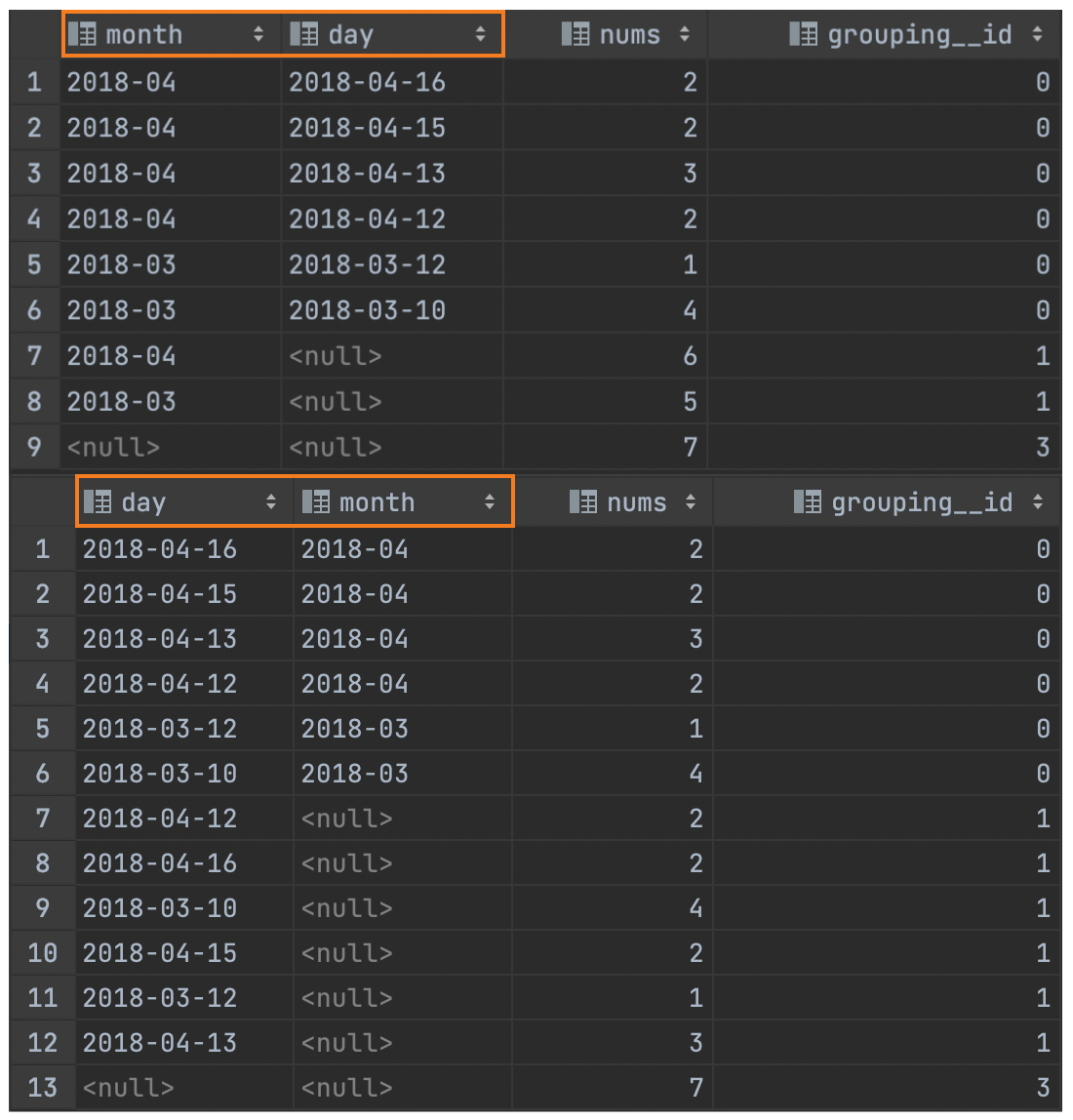
CUBE 的语法功能是根据 GROUP BY 的维度的所有组合进行聚合,而 ROLLUP 是 CUBE 的子集,以最左侧的维度为主,从该维度进行层级聚合。
比如 ROLLUP 有 a,b,c 三个维度,则所有组合情况是:((a,b,c),(a,b),(a),())。
-- 以 month 维度进行层级聚合
SELECT month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month, day
WITH ROLLUP
ORDER BY GROUPING__ID;
-- 把 month 和 day 调换顺序,以 day 维度进行层级聚合
SELECT day,
month,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY day, month
WITH ROLLUP
ORDER BY GROUPING__ID;
查询结果:
3.4 Window 窗口函数
按照功能,常用窗口可划分为如下几类:聚合函数、跨行取值函数、排名函数。
a. 概述&语法
窗口函数(Window Function)也叫做开窗函数、OLAP 函数,其最大特点是:输入值是从 SELECT 语句的结果集中的一行或多行的“窗口”中获取的。
如果函数具有 OVER 子句,则它是窗口函数。如果它缺少 OVER 子句,则它是一个普通的聚合函数。
窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过 GROUP BY 子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。
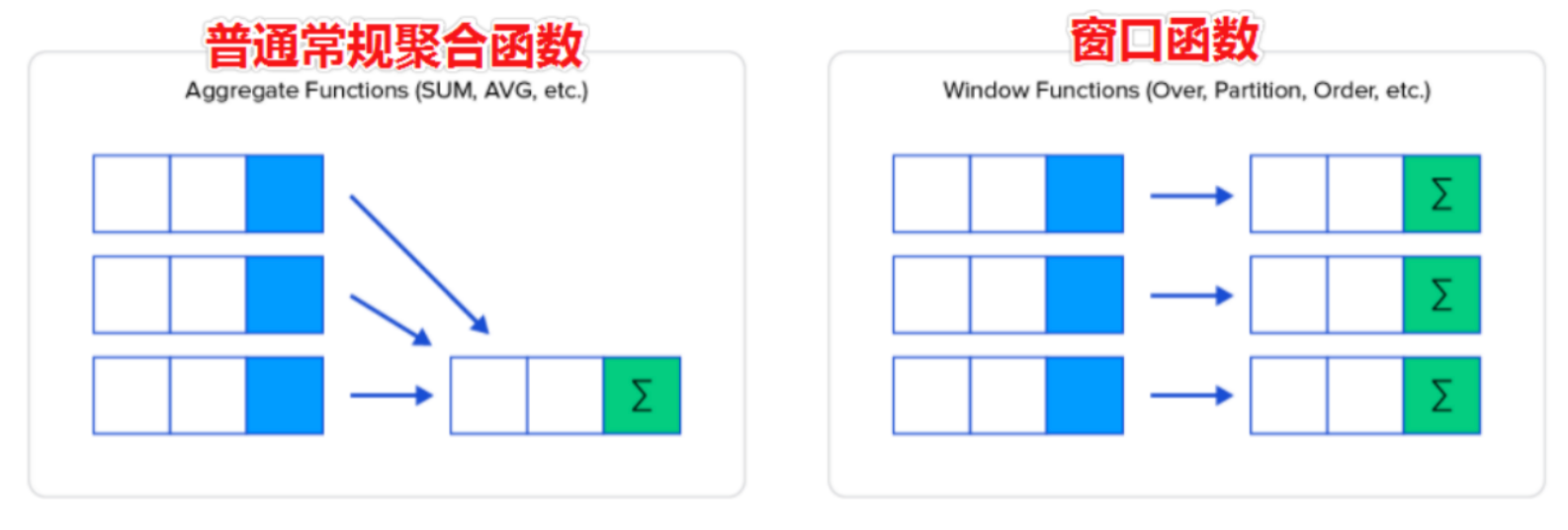
窗口函数的语法中主要包括“窗口”和“函数”两部分。其中“窗口”用于定义计算范围,“函数”用于定义计算逻辑。

通过 sum 聚合函数进行「普通常规聚合」和「窗口聚合」来直观感受窗口函数的特点:
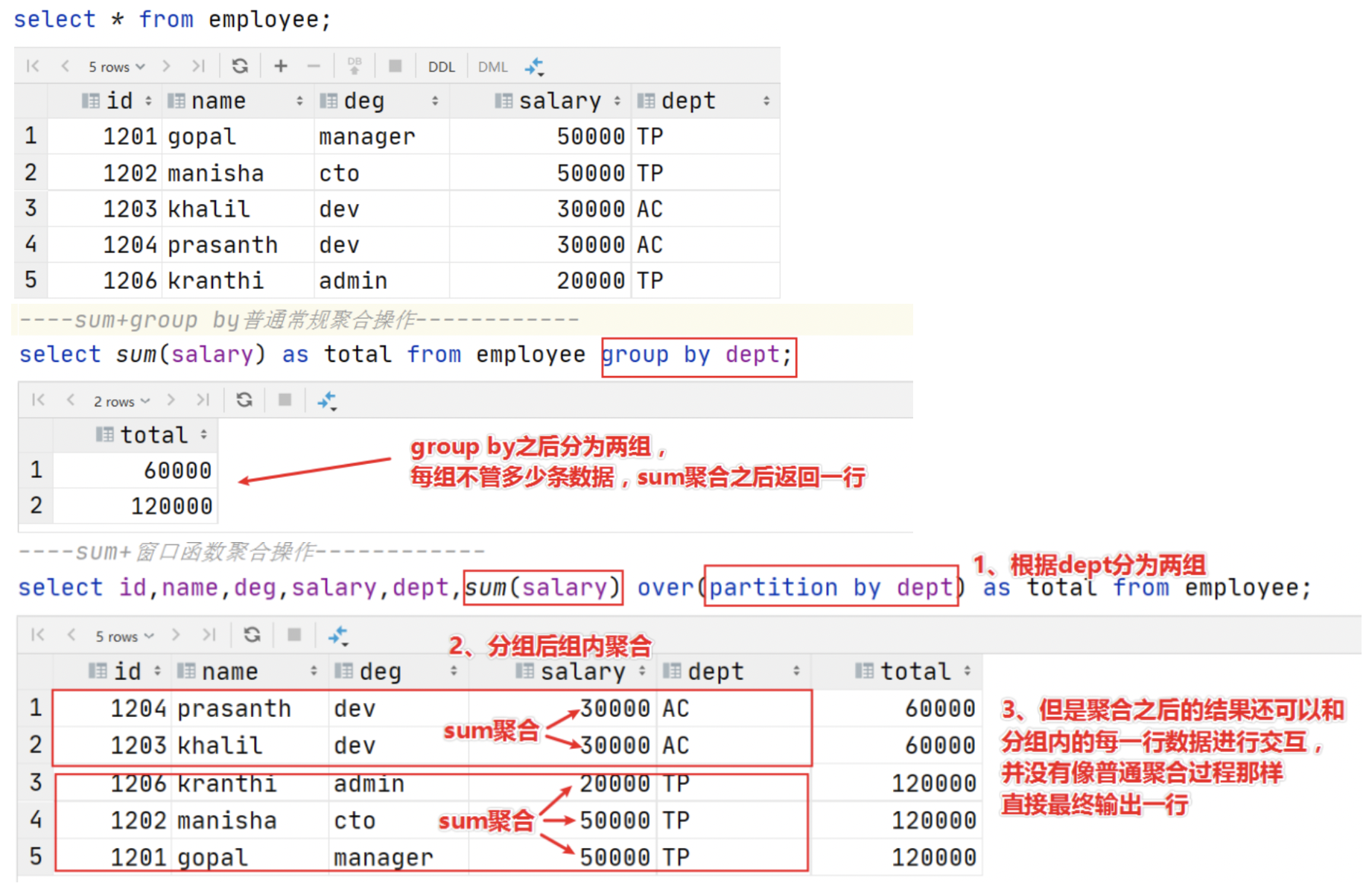
b. 窗口函数详解
(1)窗口范围的定义分为两种类型,一种是基于「行」的,一种是基于「值」的。

(2)基于行/值语法详细说明
between 包括下面这几个选项:
- preceding:往前
- following:往后
- current row:当前行
- unbounded:边界
- unbounded preceding:表示从前面的起点
- unbounded following:表示到后面的终点
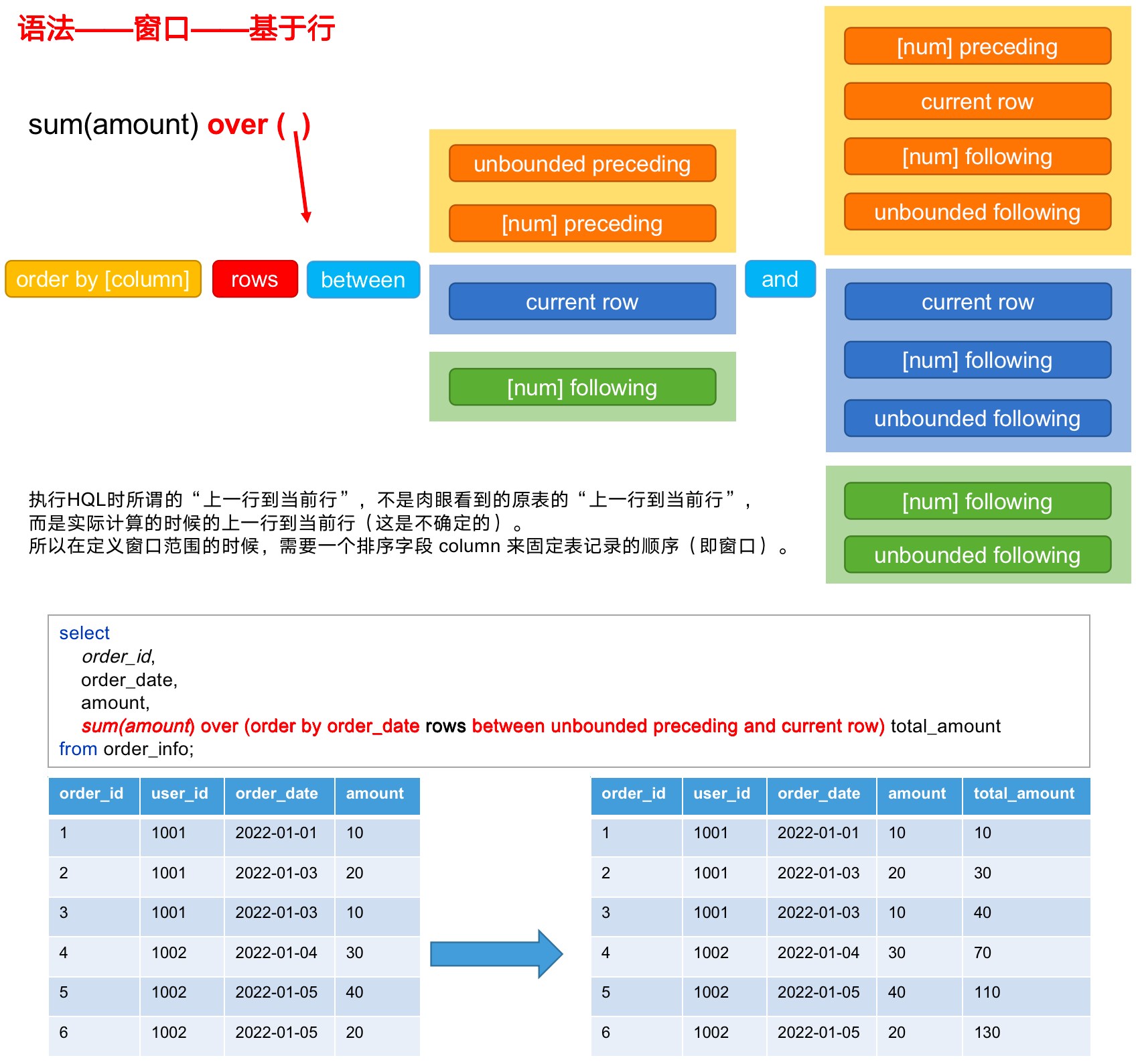
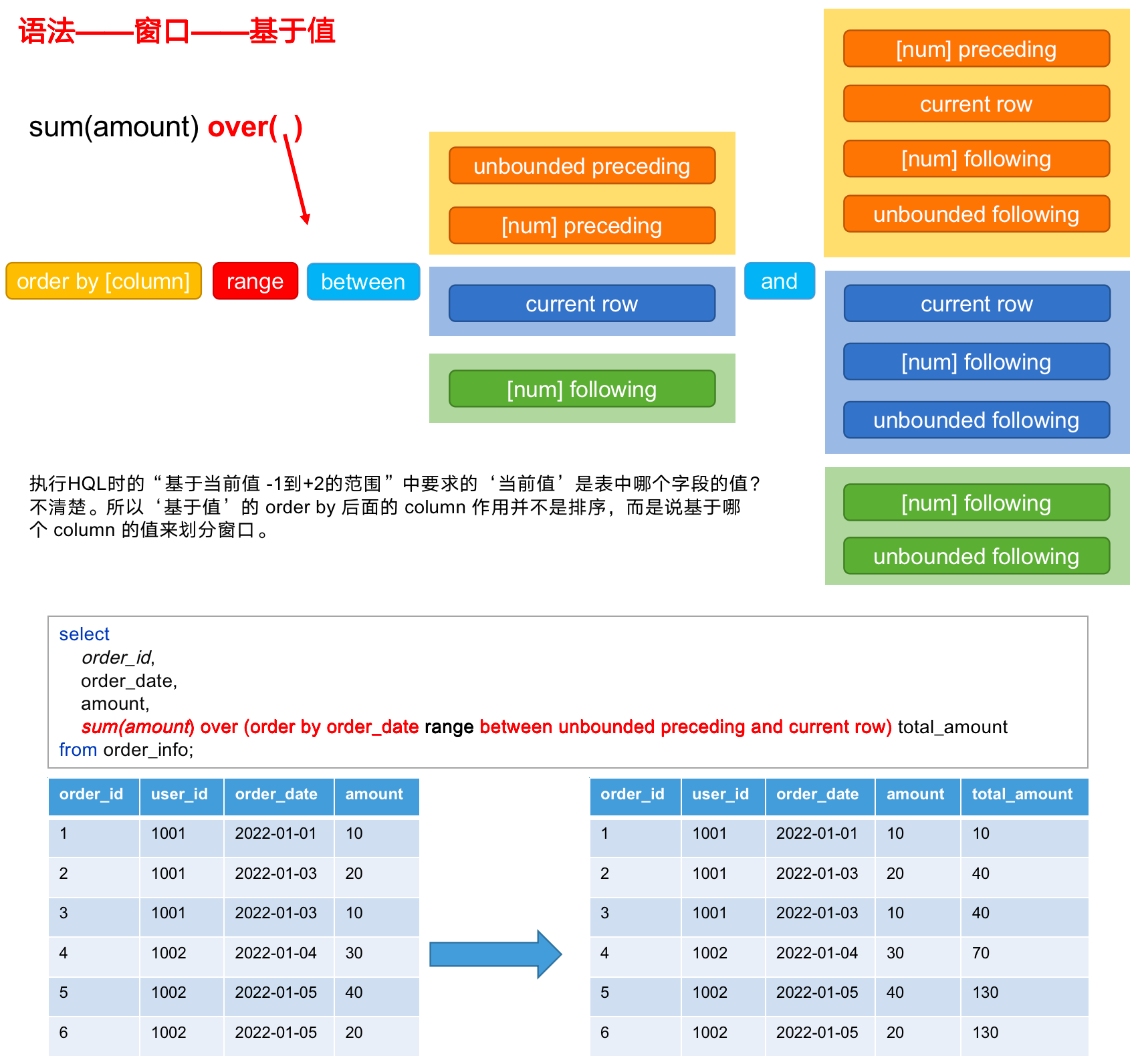
(3)分区语法示例
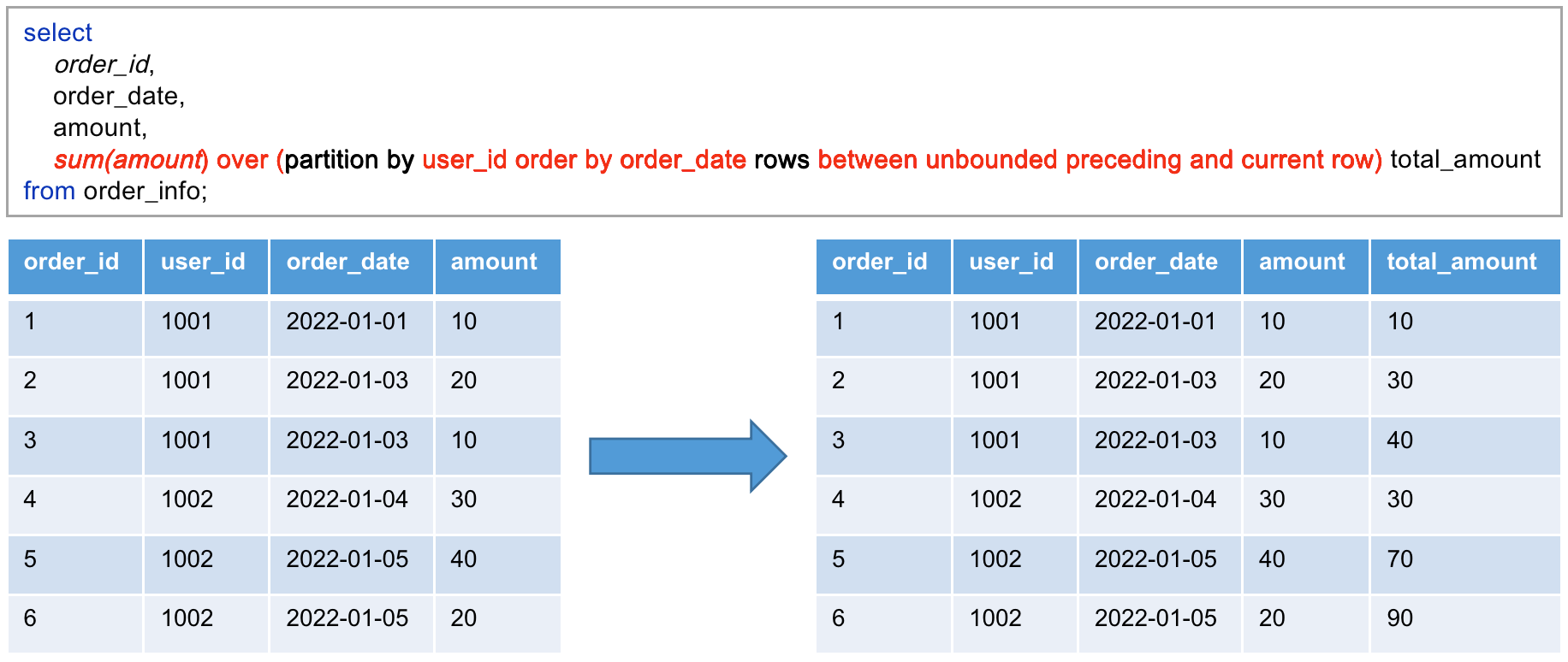
(4)缺省:over() 中的三部分内容均可省略不写
- PARTITION BY 省略不写,表示不分区;
- ORDER BY 省略不写,表示不排序;
- ( ROWS | RANGE ) BETWEEN … AND … 省略不写,则使用其默认值:
- 若 over() 中包含 ORDER BY,则默认值为 RANGE BETWEEN unbounded preceding AND current row
- 若 over() 中不包含 ORDER BY,则默认值为 ROWS BETWEEN unbounded preceding AND unbounded following
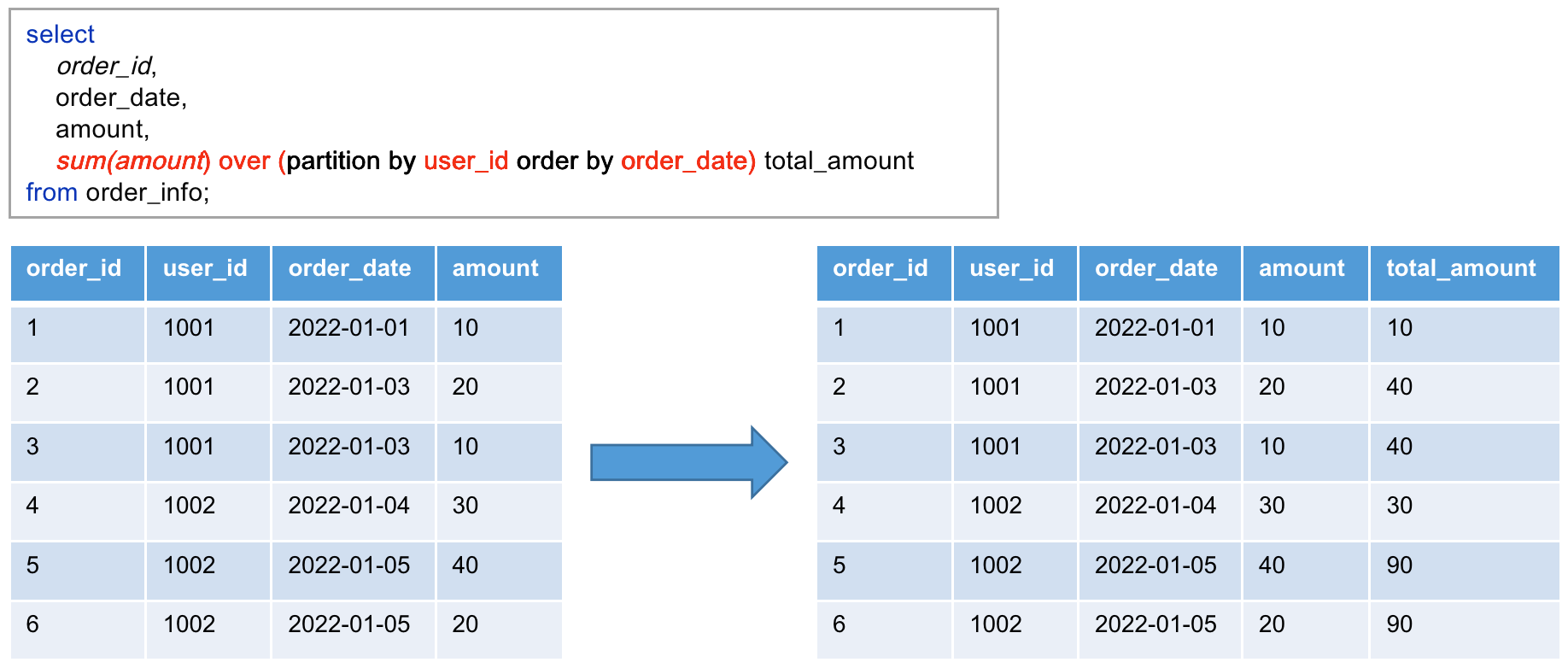
c. 窗口·跨行取值函数
- LAG(col, n, DEFAULT) 用于统计窗口内往上第 n 行值
- 第 1 个参数为列名
- 第 2 个参数为往上第 n 行(可选,默认为 1)
- 第 3 个参数为默认值(当往上第 n 行为 NULL 时候,取默认值,如不指定,则为 NULL)
- LEAD(col, n, DEFAULT) 用于统计窗口内往下第 n 行值
- 第 1 个参数为列名
- 第 2 个参数为往下第 n 行(可选,默认为 1)
- 第 3 个参数为默认值(当往下第 n 行为 NULL 时候,取默认值,如不指定,则为 NULL)
- FIRST_VALUE(col, bool) 取分组内排序后,截止到当前行,第一个值;
- LAST_VALUE(col, bool) 取分组内排序后,截止到当前行,最后一个值;
【注】lag 和 lead 函数不支持自定义窗口(设想这么一种情况,自定义窗口范围为下 5 行,然后 lag 里写要上一行的数据,这就冲突了)
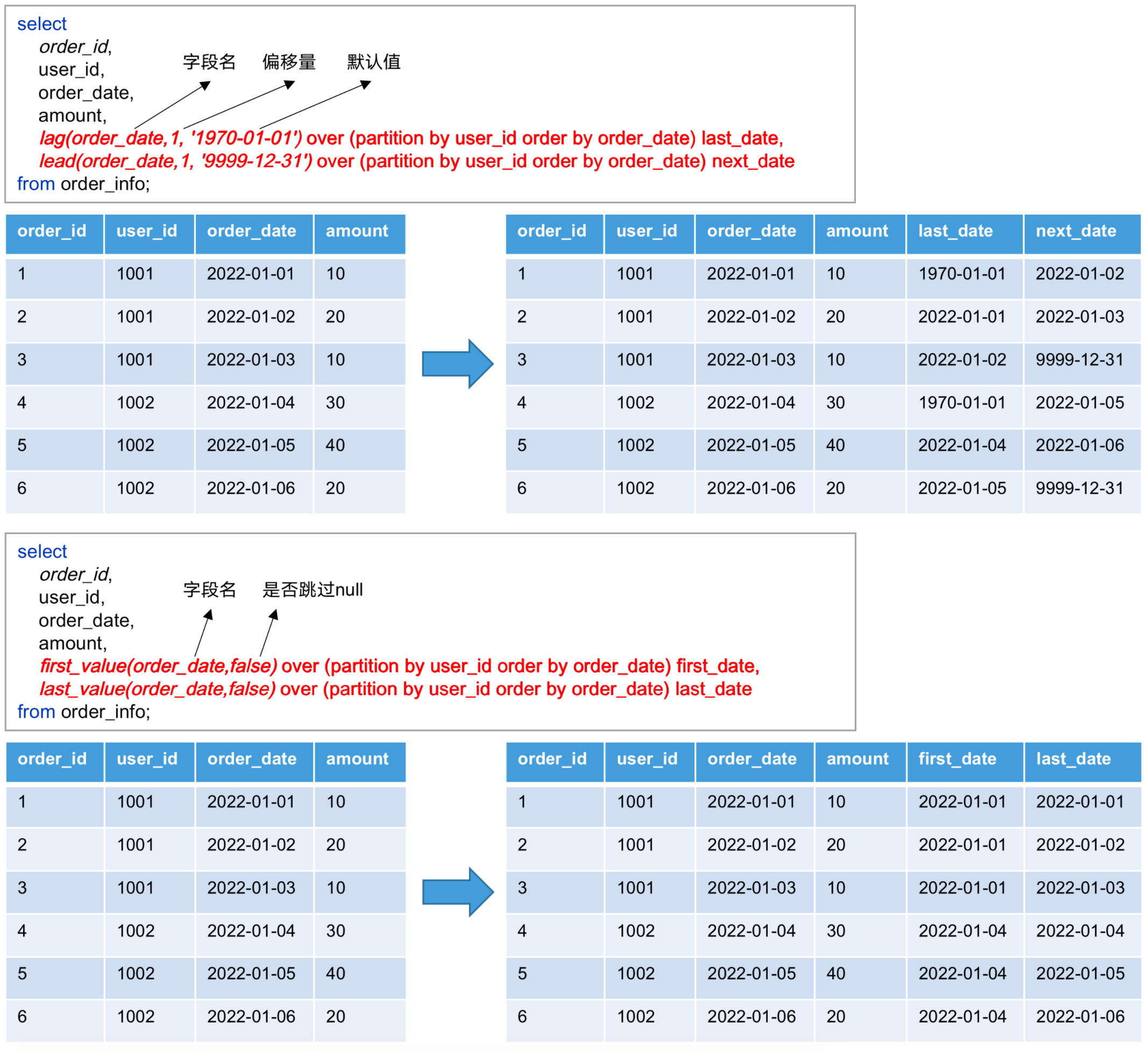
示例代码:
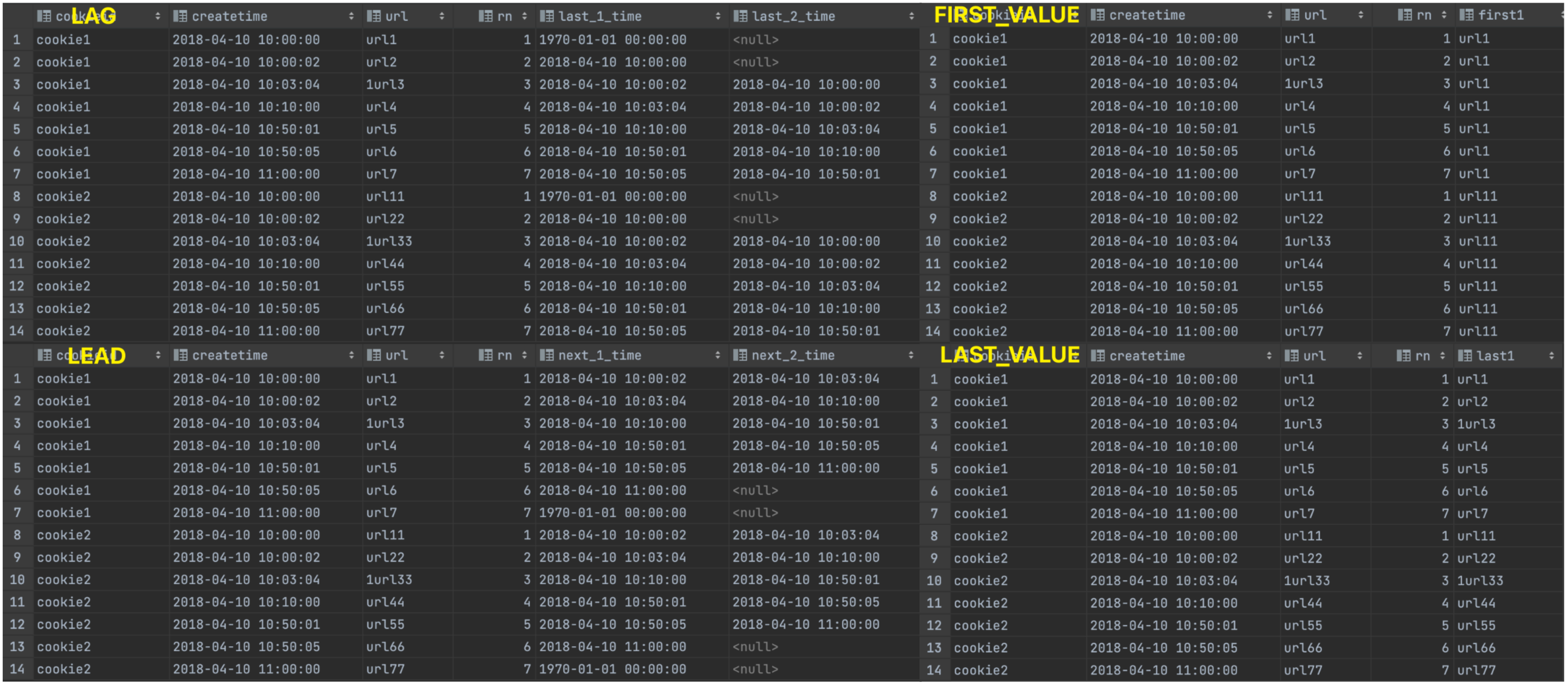
-- LAG
SELECT
cookieid,
createtime,
url,
ROW_NUMBER() OVER (PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime, 1, '1970-01-01 00:00:00') OVER (PARTITION BY cookieid ORDER BY createtime) AS last_1_time,
LAG(createtime, 2) OVER (PARTITION BY cookieid ORDER BY createtime) AS last_2_time
FROM website_url_info;
-- LEAD
SELECT
cookieid,
createtime,
url,
ROW_NUMBER() OVER (PARTITION BY cookieid ORDER BY createtime) AS rn,
LEAD(createtime, 1, '1970-01-01 00:00:00') OVER (PARTITION BY cookieid ORDER BY createtime) AS next_1_time,
LEAD(createtime, 2) OVER (PARTITION BY cookieid ORDER BY createtime) AS next_2_time
FROM website_url_info;
-- FIRST_VALUE
SELECT
cookieid,
createtime,
url,
ROW_NUMBER() OVER (PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER (PARTITION BY cookieid ORDER BY createtime) AS first1
FROM website_url_info;
-- LAST_VALUE
SELECT
cookieid,
createtime,
url,
ROW_NUMBER() OVER (PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER (PARTITION BY cookieid ORDER BY createtime) AS last1
FROM website_url_info;
执行结果:
d. 窗口·排列函数
窗口排序函数用于给每个分组内的数据打上排序的标号。注意窗口排序函数不支持窗口表达式。总共有 4 个函数需要掌握。
(1)ROW_NUMBER:在每个分组中,为每行分配一个从 1 开始的唯一序列号,递增,不考虑重复;
(2)RANK:在每个分组中,为每行分配一个从 1 开始的序列号,考虑重复,挤占后续位置;
(3)DENSE_RANK:在每个分组中,为每行分配一个从 1 开始的序列号,考虑重复,不挤占后续位置;
【注】rank 、dense_rank、row_number 不支持自定义窗口。
举例说明:
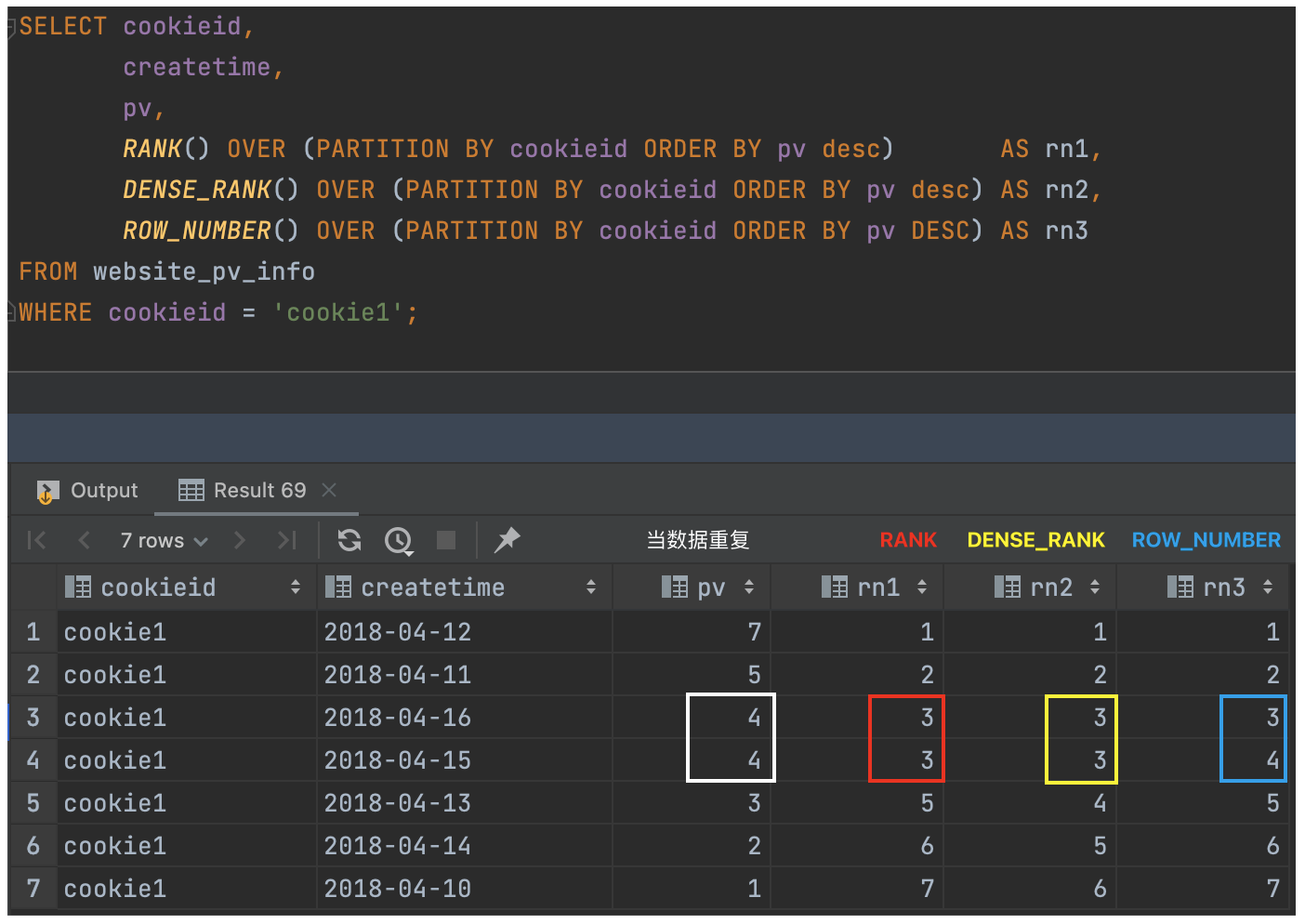
上述这三个函数用于分组 TopN 的场景非常适合。
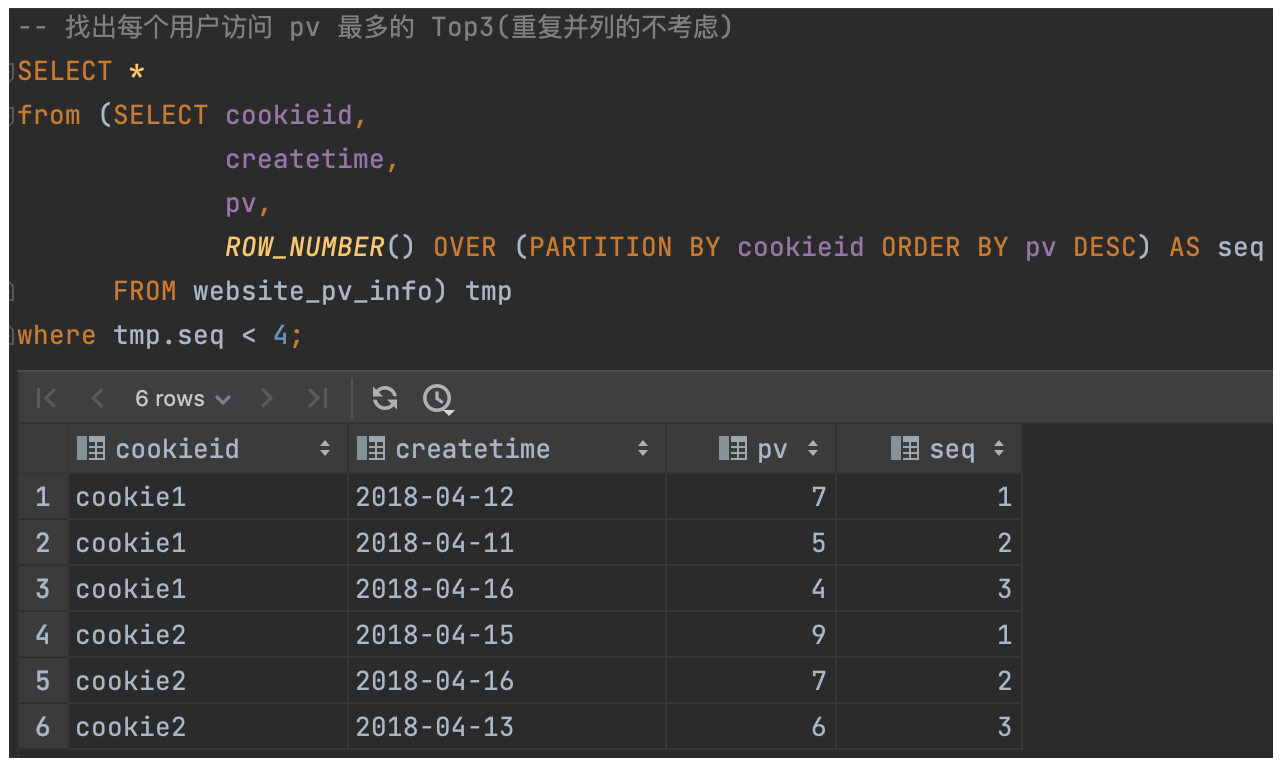
(4)NTILE:将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号。
如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差 1。
因为有时会有这样的需求:如果数据排序后分为三部分,业务人员只关心其中的一部分,如何将这中间的三分之一数据拿出来呢?
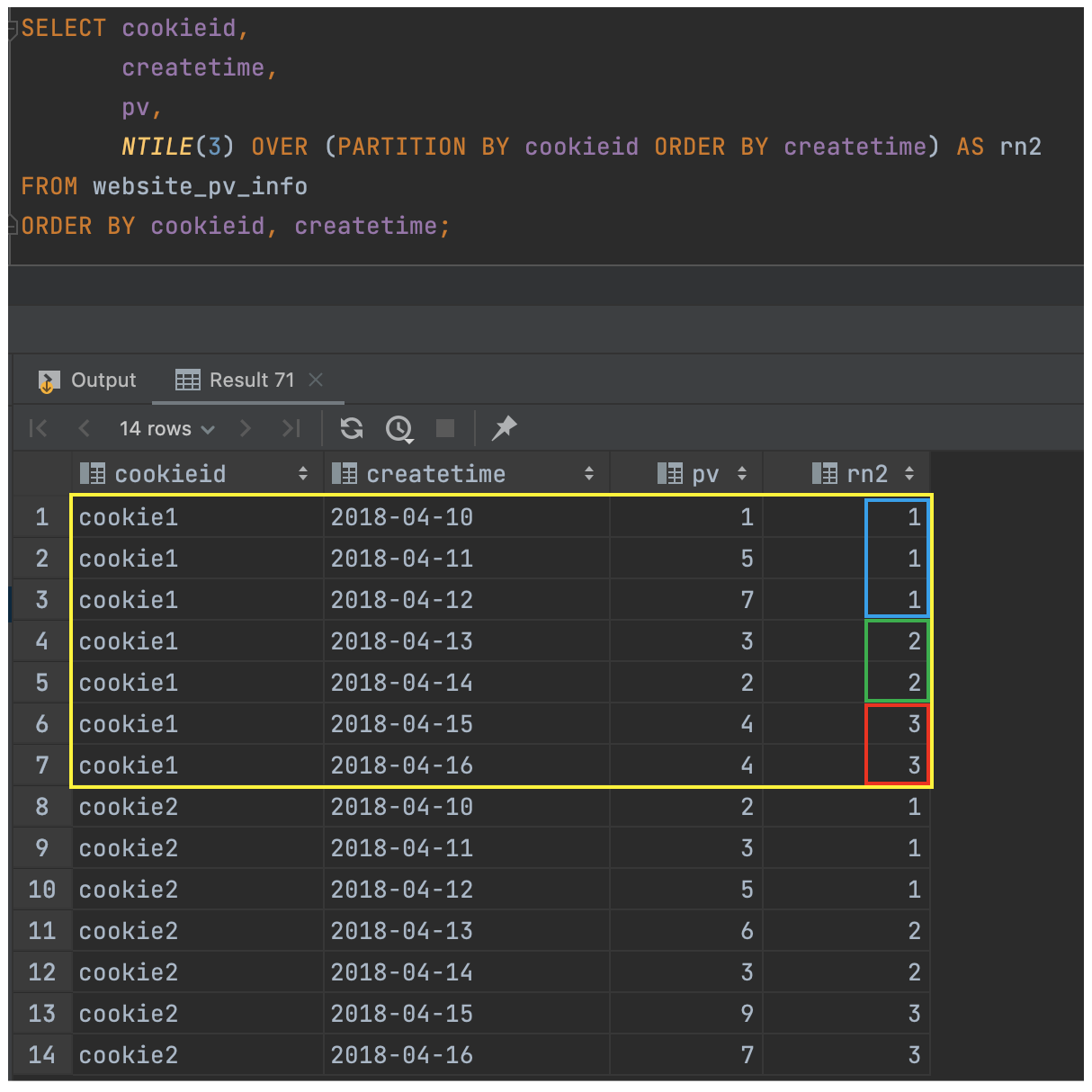
例1:把每个分组内的数据分为 3 桶
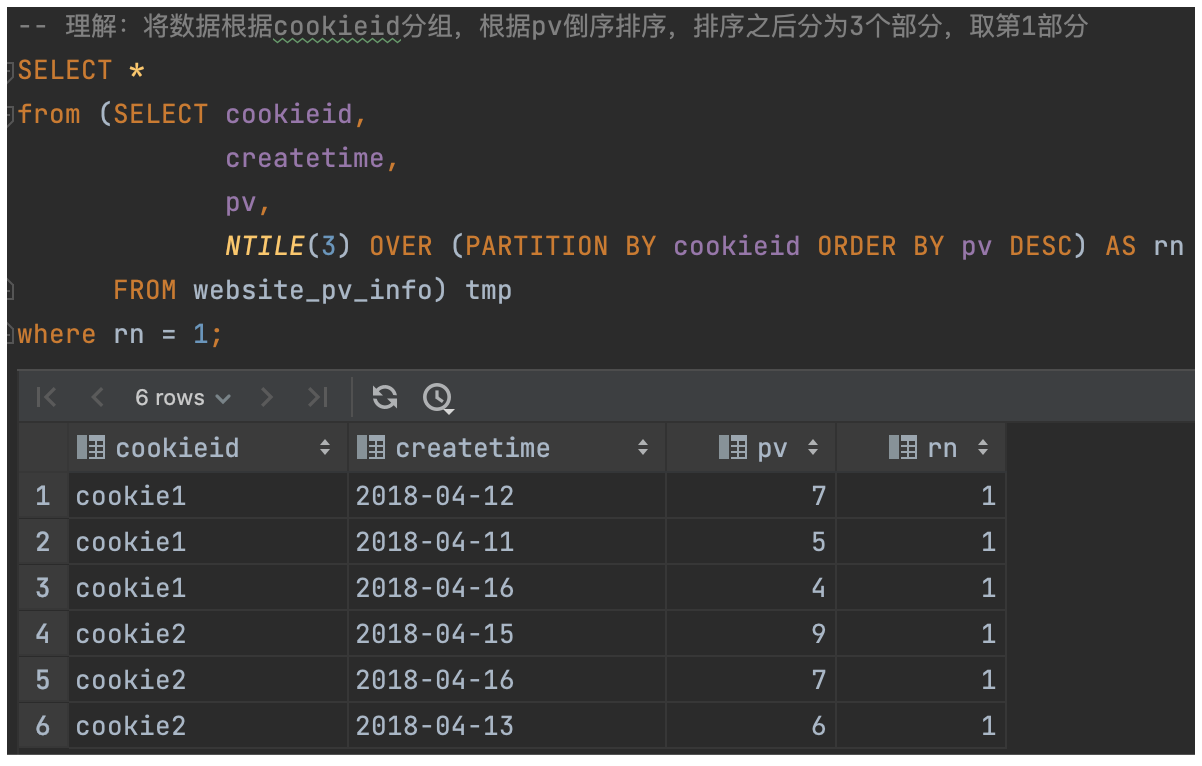
例2:统计每个用户 pv 数最多的前 1/3 天
e. 案例演示
案例1 · 网站用户页面浏览次数分析
在网站访问中,经常使用 cookie 来标识不同的用户身份,通过 cookie 可以追踪不同用户的页面访问情况,有下面两份数据:
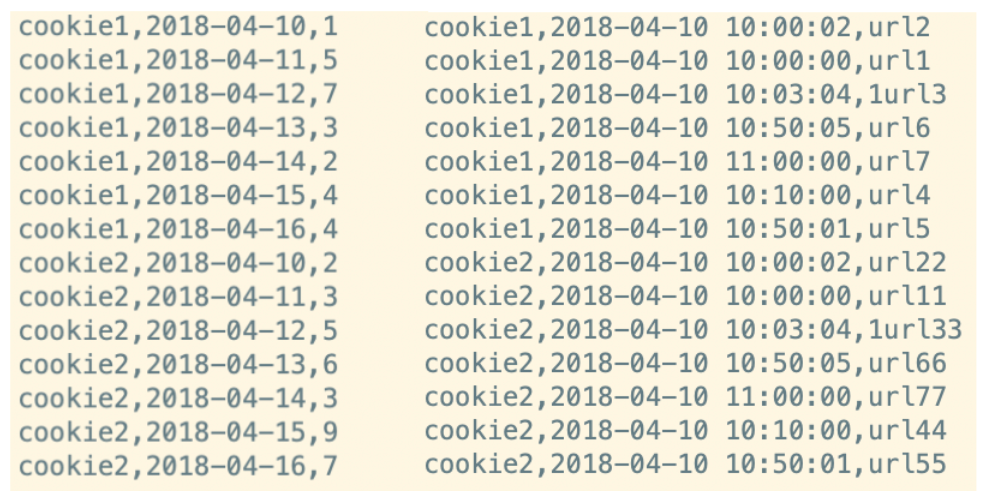
在 Hive 中创建两张表,把数据加载进去用于窗口分析:
create table website_pv_info
(
cookieid string,
createtime string,
pv int
) row format delimited fields terminated by ',';
create table website_url_info
(
cookieid string,
createtime string,
url string
) row format delimited fields terminated by ',';
load data local inpath '/home/liujiaqi/hivedata/website_pv_info.txt' into table website_pv_info;
load data local inpath '/home/liujiaqi/hivedata/website_url_info.txt' into table website_url_info;
select * from website_pv_info;
select * from website_url_info;
从 Hive v2.2.0 开始,支持 DISTINCT 与窗口函数中的聚合函数一起使用。
这里以 sum() 函数为例,其他聚合函数使用类似。
-- 1、求出每个用户总pv数 => {sum + group by} 普通常规聚合操作
select cookieid, sum(pv) as total_pv
from website_pv_info
group by cookieid;
-- 2、sum+窗口函数,注意看清楚是要'整体聚合'还是'累积聚合'
-- sum(...) over( ) 对表所有行求和
-- sum(...) over( order by ... ) 连续累积求和
-- sum(...) over( partition by ... ) 同组内所有行求和
-- sum(...) over( partition by ... order by ... ) 在每个分组内,连续累积求和
-- 需求a、求出网站总的pv数
-- sum(...) over( ) 对表所有行求和
select cookieid,
createtime,
pv,
sum(pv) over () as total_pv
from website_pv_info;
-- 需求b、求出每个用户总pv数
-- sum(...) over( partition by ... ) 同组内所行求和
select cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid) as total_pv
from website_pv_info;
-- 需求c、求出每个用户截止到当天,累积的总pv数
-- sum(...) over( partition by ... order by ... ) 在每个分组内,连续累积求和
select cookieid,
createtime,
pv,
sum(pv) over (partition by cookieid order by createtime) as current_total_pv
from website_pv_info;
聚合结果:

案例2 · 订单分析
-- 建表
create table order_info
(
order_id string, -- 订单id
user_id string, -- 用户id
user_name string, -- 用户姓名
order_date string, -- 下单日期
order_amount int -- 订单金额
);
-- 插入数据
insert overwrite table order_info
values ('1', '1001', '小元', '2022-01-01', '10'),
('2', '1002', '小海', '2022-01-02', '15'),
('3', '1001', '小元', '2022-02-03', '23'),
('4', '1002', '小海', '2022-01-04', '29'),
('5', '1001', '小元', '2022-01-05', '46'),
('6', '1001', '小元', '2022-04-06', '42'),
('7', '1002', '小海', '2022-01-07', '50'),
('8', '1001', '小元', '2022-01-08', '50'),
('9', '1003', '小辉', '2022-04-08', '62'),
('10', '1003', '小辉', '2022-04-09', '62'),
('11', '1004', '小猛', '2022-05-10', '12'),
('12', '1003', '小辉', '2022-04-11', '75'),
('13', '1004', '小猛', '2022-06-12', '80'),
('14', '1003', '小辉', '2022-04-13', '94'),
('15', '1001', '小元', '2022-02-03', '23');
表数据如下:
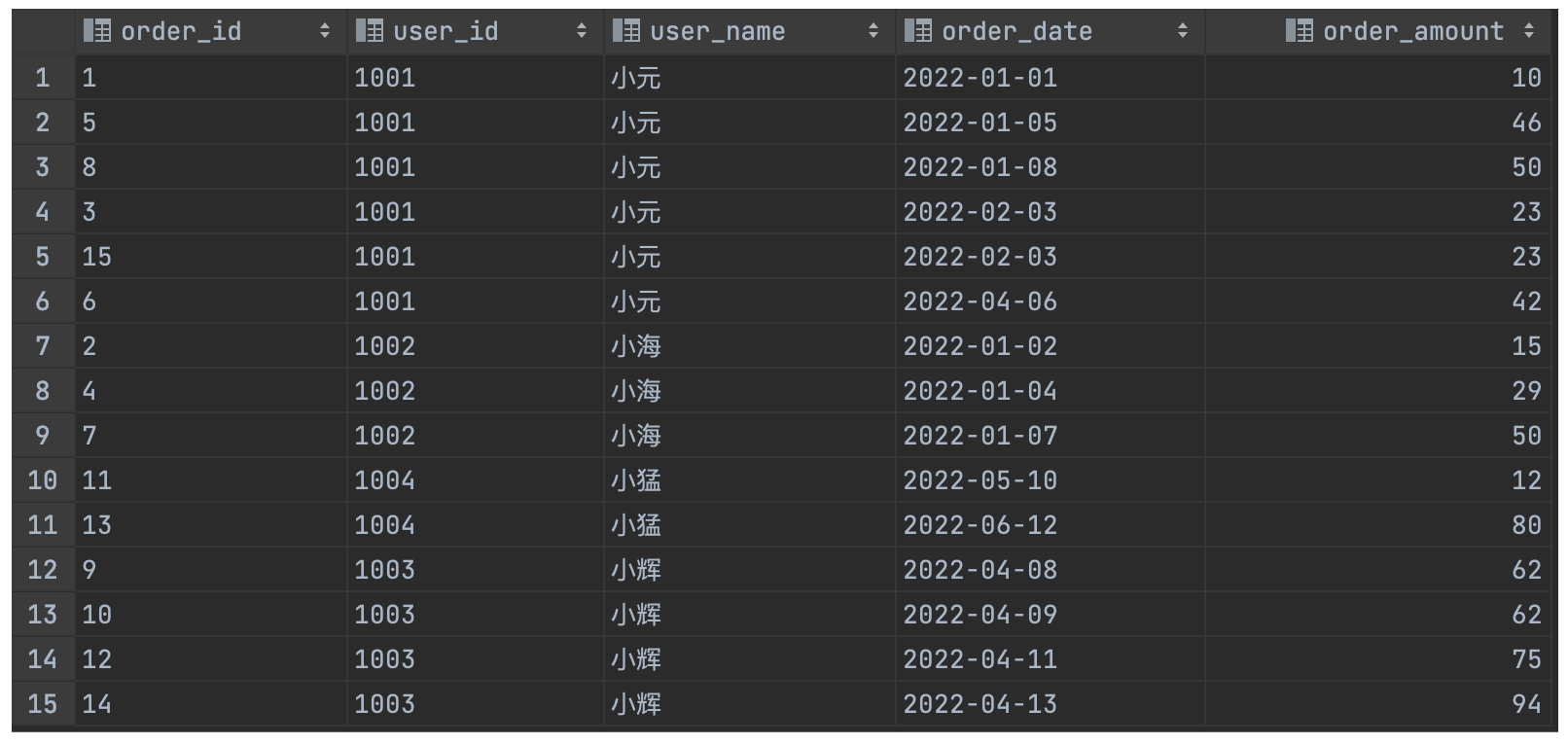
(1)统计每个用户截至每次下单的累积下单总额
SELECT order_id,
user_id,
user_name,
order_date,
order_amount,
SUM(order_amount) OVER (PARTITION BY user_id ORDER BY order_date)
FROM order_info;
SELECT order_id,
user_id,
user_name,
order_date,
order_amount,
SUM(order_amount) OVER (PARTITION BY user_id ORDER BY order_date ROWS BETWEEN unbounded preceding AND current row)
FROM order_info
若 over() 中包含 ORDER BY,不写 BETWEEN...AND... 则默认值为 RANGE BETWEEN unbounded preceding AND current row,与题意不符。
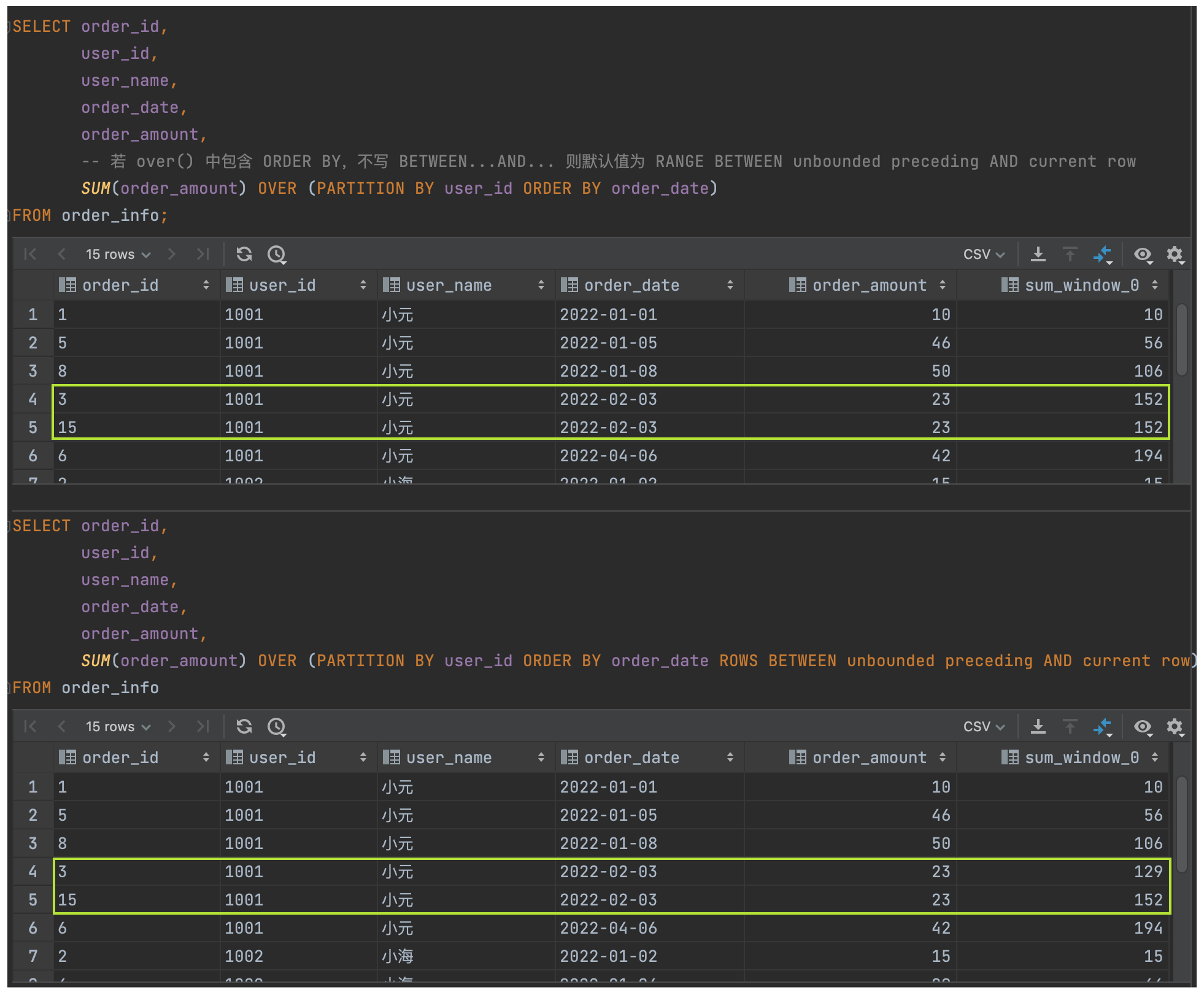
(2)统计每个用户截至每次下单的当月累积下单总额
SELECT order_id,
user_id,
user_name,
order_date,
order_amount,
SUM(order_amount)
OVER (PARTITION BY user_id,substring(order_date, 1, 7)
ORDER BY order_date
ROWS BETWEEN unbounded preceding AND current row)
FROM order_info;
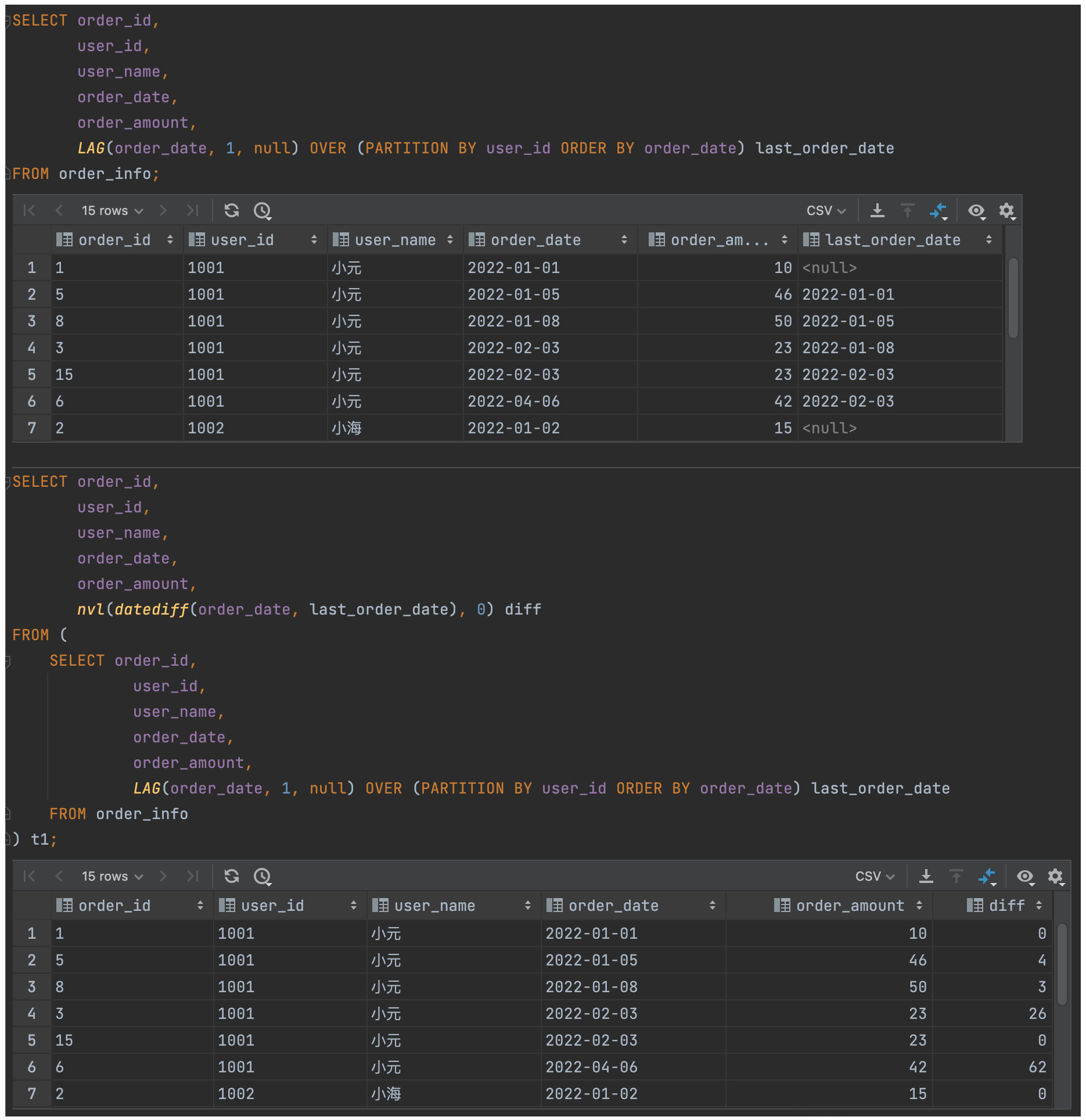
(3)统计每个用户每次下单距离上次下单相隔的天数(首次下单按 0 天算)
-- PLAN A
SELECT order_id,
user_id,
user_name,
order_date,
order_amount,
nvl(datediff(order_date, last_order_date), 0) diff
FROM (SELECT order_id,
user_id,
user_name,
order_date,
order_amount,
LAG(order_date, 1, null) OVER (PARTITION BY user_id ORDER BY order_date) last_order_date
FROM order_info) t1;
-- PLAN B
SELECT order_id,
user_id,
user_name,
order_date,
order_amount,
datediff(order_date, last_order_date) diff
FROM (SELECT order_id,
user_id,
user_name,
order_date,
order_amount,
LAG(order_date, 1, order_date) OVER (PARTITION BY user_id ORDER BY order_date) last_order_date
FROM order_info) t1;
(4)查询所有下单记录以及每个用户的每个下单记录所在月份的首/末次下单日期
SELECT order_id,
user_id,
user_name,
order_date,
order_amount,
FIRST_VALUE(order_date)
OVER (PARTITION BY user_id, substring(order_date, 1, 7)
ORDER BY order_date
ROWS BETWEEN unbounded preceding AND current row) month_first_date,
LAST_VALUE(order_date)
OVER (PARTITION BY user_id, substring(order_date, 1, 7)
ORDER BY order_date
ROWS BETWEEN current row AND unbounded following) month_last_date
FROM order_info;
(5)为每个用户的所有下单记录按照订单金额进行排名
SELECT order_id,
user_id,
user_name,
order_date,
order_amount,
RANK() OVER (PARTITION BY user_id ORDER BY order_amount DESC) rk,
DENSE_RANK() OVER (PARTITION BY user_id ORDER BY order_amount DESC) drk,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY order_amount DESC) rn
FROM order_info;
3.5 Sampling 抽样函数
当数据量过大时,我们可能需要查找数据子集以加快数据处理速度分析。 这就是抽样、采样,一种用于识别和分析数据中的子集的技术,以发现整个数据集中的模式和趋势。

在 HQL 中,可以通过三种方式采样数据:随机采样、分桶表采样、块采样。
a. 随机采样
Random 随机抽样使用 rand() 函数和 LIMIT 关键字来获取数据。 使用了 DISTRIBUTE 和 SORT 关键字,可以确保数据也随机分布在 Mapper 和 Reducer 之间,使得底层执行有效率。
ORDER BY 和 rand() 语句也可以达到相同的目的,但是表现不好。因为 ORDER BY 是全局排序,只会启动运行一个 Reducer。
-- 随机抽取 2 个学生的情况进行查看
SELECT *
FROM student
DISTRIBUTE BY rand() SORT BY rand()
LIMIT 2;
-- 使用 order by + rand 也可以实现同样的效果,但是效率不高
SELECT *
FROM student
ORDER BY rand()
LIMIT 2;
b. 块抽样
Block 块采样允许 select 随机获取 n 行数据,即数据大小或 n 个字节的数据。
采样粒度是 HDFS 块大小。优点是速度快,缺点是不随机。
-- 根据行数抽样
SELECT *
FROM student TABLESAMPLE (1 ROWS);
-- 根据数据大小百分比抽样
SELECT *
FROM student TABLESAMPLE (50 PERCENT);
-- 根据数据大小抽样(支持数据单位 b/B, k/K, m/M, g/G)
SELECT *
FROM student TABLESAMPLE (1k);
c. 分桶表抽样
Bucket Table 是一种特殊的采样方法,针对分桶表进行了优化。优点是既随机速度也很快。

-- 根据整行数据进行抽样
SELECT *
FROM t_usa_covid19_bucket TABLESAMPLE (BUCKET 1 OUT OF 2 ON rand());
-- 根据分桶字段进行抽样
SELECT *
FROM t_usa_covid19_bucket TABLESAMPLE (BUCKET 1 OUT OF 2 ON state);
