07-HDFS(5)
1. HDFS Trash
1.1 功能概述
回收站(垃圾桶)是当前主流操作系统里的一个系统文件夹,主要用来存放用户临时删除的文档资料,存放在回收站的文件可以恢复。
回收站的功能给了我们一剂“后悔药”。回收站保存了删除的文件、文件夹、图片、快捷方式等。这些项目将一直保留在回收站中,直到您清空回收站。我们许多误删除的文件就是从它里面找到的。
HDFS 本身也是一个文件系统,那么就会涉及到文件数据的删除操作。默认情况下,HDFS 中是没有回收站垃圾桶概念的,删除操作的数据将会被直接删除,没有后悔药。
Trash 机制,叫做回收站或者垃圾桶。Trash 就像操作系统中的回收站一样。它的目的是防止你无意中删除某些东西。默认情况下是不开启的。启用 Trash 功能后,从 HDFS 中删除某些内容时,文件或目录不会立即被清除,它们将被移动到回收站 Current 目录中 /user/${username}/.Trash/current。
.Trash 中的文件在用户可配置的时间延迟后被永久删除,也可以简单地将回收站里的文件移动到 .Trash 目录之外的位置来恢复回收站中的文件和目录。
1.2 Checkpoint
检查点仅仅是用户回收站下的一个目录,用于存储在创建检查点之前删除的所有文件或目录。
如果你想查看回收站目录,可以在 /user/${username}/.Trash/{timestamp_of_checkpoint_creation} 处看到。
最近删除的文件被移动到回收站 Current 目录,并且在可配置的时间间隔内,HDFS 会为在 Current 回收站目录下的文件创建检查点 /user/${username}/.Trash/<日期>,并在过期时删除旧的检查点。

1.3 功能开启
(1)关闭 HDFS 集群:stop-dfs.sh
(2)修改 core-site.xml 文件
<!-- 回收站中的文件多少分钟后会被系统永久删除。如果为0,Trash功能将被禁用。 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<!--
前后两次检查点的创建时间间隔(单位也是分钟),新的检查点被创建后,随之旧的检查点就会被系统永久删除。
如果为0,则将该值设置为 fs.trash.interval 的值。
要求 fs.trash.checkpoint.interval <= fs.trash.interval,不然有何意义。
-->
<property>
<name>fs.trash.checkpoint.interval</name>
<value>0</value>
</property>
(3)同步集群配置文件到其他节点
(4)启动 HDFS 集群:start-dfs.sh
1.4 功能使用
(1)删除文件到 Trash
开启 Trash 功能后,正常执行删除操作,文件实际并不会被直接删除,而是被移动到了垃圾回收站。

通过程序删除的文件不会经过回收站,需要调用 moveToTrash() 才进入回收站:
Trash trash = New Trash(conf);
trash.moveToTrash(path);
(2)删除文件跳过 Trash
有的时候我们希望直接把文件删除,不需要再经过 Trash 回收站了,可以在执行删除操作的时候添加一个参数:-skipTrash。
hadoop fs -rm -skipTrash /hello.txt
(3)从 Trash 中恢复文件
回收站里面的文件,在到期被自动删除之前,都可以通过命令恢复出来。使用 mv、cp 命令把数据文件从 Trash 目录下复制移动出来就可以了。
hadoop fs -mv /user/root/.Trash/Current/testdir/* /testdir/
(4)清空 Trash
除了 fs.trash.interval 参数控制到期自动删除之外,用户还可以通过命令手动清空回收站,释放 HDFS 磁盘存储空间。首先想到的是删除整个回收站目录,将会清空回收站,这是一个选择。
此外,HDFS 提供了一个命令行工具来完成这个工作:hadoop fs -expunge,该命令立即从文件系统中删除过期的检查点。
2. HDFS Snapshot
2.1 功能概述
HDFS Snapshot 是 HDFS 整个文件系统,或者某个目录在某个时刻的镜像。该镜像并不会随着源目录的改变而进行动态的更新。可以将快照理解为拍照片时的那一瞬间的投影,过了那个时间之后,又会有新的一个投影。
HDFS 快照的核心功能包括:数据恢复、数据备份、数据测试。
(1)数据恢复
可以通过滚动的方式来对重要的目录进行创建 snapshot 的操作,这样在系统中就存在针对某个目录的多个快照版本。当用户误删除掉某个文件时,可以通过最新的 snapshot 来进行相关的恢复操作。
(2)数据备份
可以使用 snapshot 来进行整个集群,或者某些目录、文件的备份。管理员以某个时刻的 snapshot 作为备份的起始结点,然后通过比较不同备份之间差异性,来进行增量备份。
(3)数据测试
在某些重要数据上进行测试或者实验,可能会直接将原始的数据破坏掉。可以临时的为用户针对要操作的数据来创建一个 snapshot,然后让用户在对应的 snapshot 上进行相关的实验和测试,从而避免对原始数据的破坏。
2.2 底层实现
在了解 HDFS 快照功能如何实现之前,首先有一个根本的原则需要记住:快照不是数据的简单拷贝,快照只做差异的记录。这一原则在其他很多系统的快照概念中都是适用的,比如磁盘快照,也是不保存真实数据的。因为不保存实际的数据,所以快照的生成往往非常迅速。
在 HDFS 中,如果在其中一个目录比如 /A 下创建一个快照,则快照文件中将会存在与 /A 目录下完全一致的子目录文件结构以及相应的属性信息,通过命令也能看到快照里面具体的文件内容,但是这并不意味着快照已经对此数据进行完全的拷贝。
这里遵循一个原则:对于大多不变的数据,你所看到的数据其实是当前物理路径所指的内容,而发生变更的 inode 数据才会被快照额外拷贝,也就是所说的「差异拷贝」。inode 译成中文就是索引节点,它用来存放文件及目录的基本信息,包含时间、名称、拥有者、所在组等信息。
HDFS 快照不会复制 DataNode 中的块,只记录了块列表和文件大小。
HDFS 快照不会对常规 HDFS 操作产生不利影响,修改记录按逆时针顺序进行,因此可以直接访问当前数据。通过从当前数据中减去修改来计算快照数据。
2.3 快照命令
(1)快照功能启停命令
[root@node1 ~]# hdfs dfsadmin
Usage: hdfs dfsadmin
Note: Administrative commands can only be run as the HDFS superuser.
[-allowSnapshot <snapshotDir>]
[-disallowSnapshot <snapshotDir>]
HDFS 中可以针对整个文件系统或者文件系统中某个目录创建快照,但是创建快照的前提是相应的目录开启快照的功能。如果针对没有启动快照功能的目录创建快照则会报错:

HDFS 中可以针对已经开启快照功能的目录进行禁用快照功能的设置,禁用的前提是该目录的所有快照已经被删除。

- 启用快照功能:
hdfs dfsadmin -allowSnapshot /allenwoon - 禁用快照功能:
hdfs dfsadmin -disallowSnapshot /allenwoon
(2)快照操作相关命令
$ hdfs dfs
Usage: hadoop fs [generic options]
[-createSnapshot <snapshotDir> [<snapshotName>]] # 创建快照
[-deleteSnapshot <snapshotDir> <snapshotName>] # 删除快照
[-renameSnapshot <snapshotDir> <oldName> <newName>] # 重命名快照
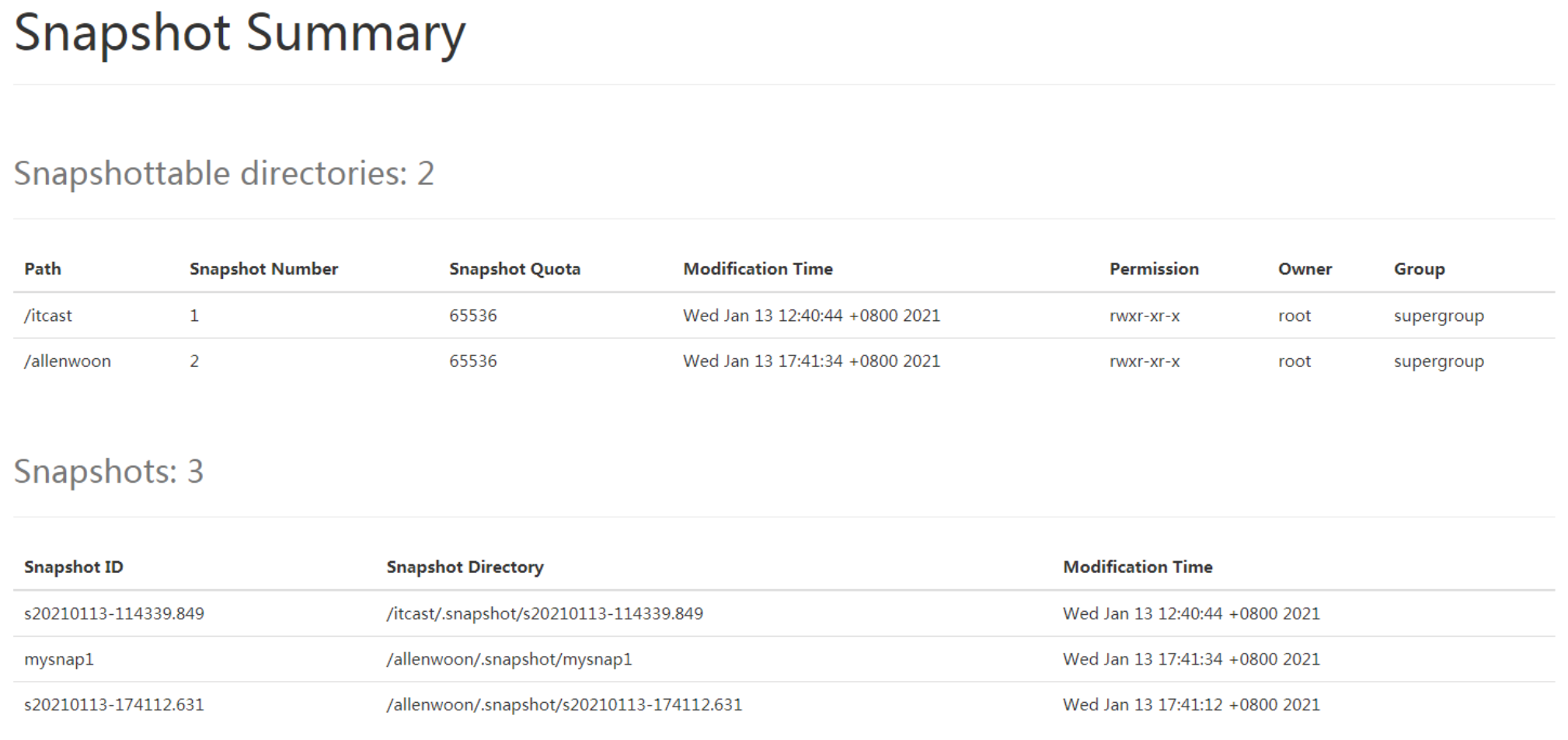
$ hdfs lsSnapshottableDir # 列出所有开启快照功能的目录
$ hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot> # 获取快照差异报告
2.4 使用示例
(1)开启指定目录的快照
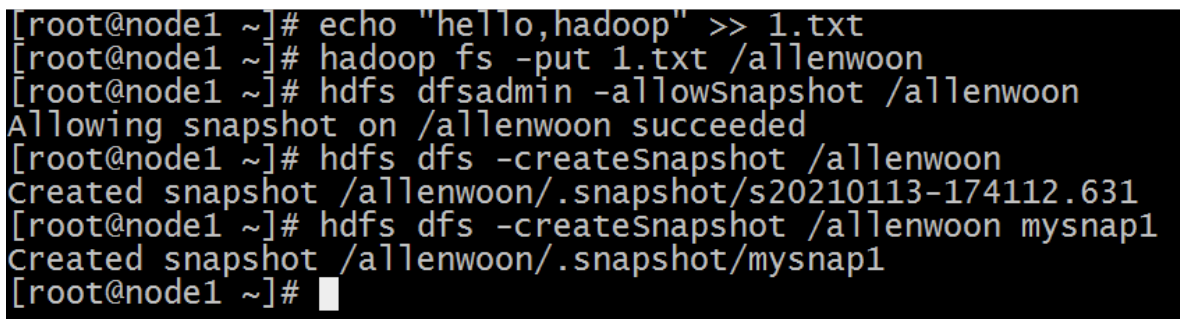
$ hdfs dfsadmin -allowSnapshot /allenwoon
(2)对指定目录创建快照
$ hdfs dfs -createSnapshot /allenwoon # 系统自动生成快照名称
$ hdfs dfs -createSnapshot /allenwoon mysnap1 # 指定名称创建快照
通过浏览器访问快照:http://node1:9870/explorer.html#/allenwoon/.snapshot
(4)重命名快照
$ hdfs dfs -renameSnapshot /allenwoon mysnap1 mysnap2
(5)列出当前用户所有可以快照的目录
$ hdfs lsSnapshottableDir
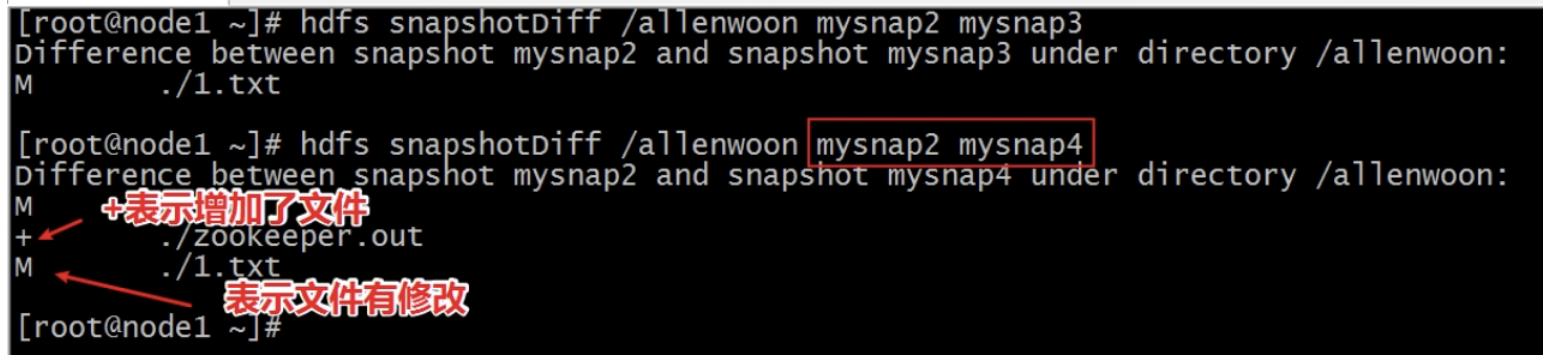
(6)比较两个快照不同之处
$ echo 222 > 2.txt
$ hadoop fs -appendToFile 2.txt /allenwoon/1.txt
$ hadoop fs -cat /allenwoon/1.txt
1
222
$ hdfs dfs -createSnapshot /allenwoon mysnap3
Created snapshot /allenwoon/.snapshot/mysnap3
$ hadoop fs -put zookeeper.out /allenwoon
$ hdfs dfs -createSnapshot /allenwoon mysnap4
Created snapshot /allenwoon/.snapshot/mysnap4
##################################################
$ hdfs snapshotDiff /allenwoon mysnap2 mysnap3
$ hdfs snapshotDiff /allenwoon mysnap2 mysnap4
##################################################
# + The file/directory has been created.
# - The file/directory has been deleted.
# M The file/directory has been modified.
# R The file/directory has been renamed.
(7)删除快照
$ hdfs dfs -deleteSnapshot /allenwoon mysnap4
(8)删除有快照的目录
$ hadoop fs -rm -r /allenwoon
拥有快照的目录不允许被删除,某种程度上也保护了文件安全。

3. HDFS 权限管理
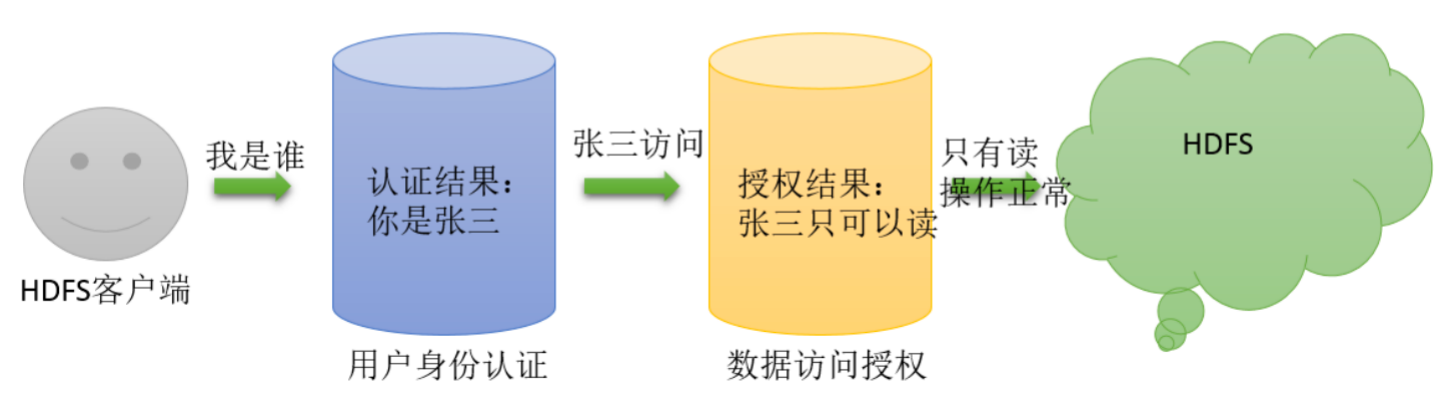
作为分布式文件系统,HDFS 也集成了一套兼容 POSIX 的权限管理系统。客户端在进行每次文件操时,系统会从用户身份认证和数据访问授权两个环节进行验证: 客户端的操作请求会首先通过本地的用户身份验证机制来获得“凭证”(类似于身份证书),然后系统根据此“凭证”分辨出合法的用户名,再据此查看该用户所访问的数据是否已经授权。一旦这个流程中的某个环节出现异常,客户端的操作请求便会失败。
3.1 UGO 权限管理
a. 概念
HDFS的文件权限与Linux/Unix系统的UGO模型类型类似,可以简单描述为:每个文件和目录都与一个所有者和一个组相关联。该文件或目录对作为所有者(USER)的用户,作为该组成员的其他用户(GROUP)以及对所有其他用户(OTHER)具有单独的权限。
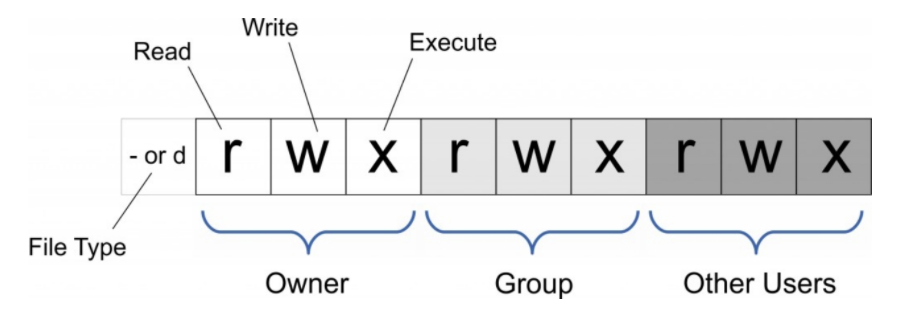
HDFS 文件权限也细分为:读权限(r)、写权限(w)、执行权限(x)。
在 HDFS 中,对于文件,需要 r 权限才能读取文件,而 w 权限才能写入或追加到文件。没有 x 可执行文件的概念。
在 HDFS 中,对于目录,需要 r 权限才能列出目录的内容,需要 w 权限才能创建或删除文件或目录,并且需要 x 权限才能访问目录的子级。
b. 权限掩码
Linux 中 umask 可用来设定权限掩码。权限掩码是由 3 个八进制的数字所组成,将现有的存取权限减掉权限掩码后,即可产生建立文件时预设的权限。
与 Linux/Unix 系统类似,HDFS 也提供了 umask 掩码,用于设置在 HDFS 中默认新建的文件和目录权限位。默认 umask 值有属性 fs.permissions.umask-mode 指定,默认值 022。
创建文件和目录时使用的 umask,默认的权限就是:
- 目录:777-022=755,也就是 drwxr-xr-x
- 文件:777-022=755,因为 HDFS 中文件没有 x 执行权限的概念,所以是 -rw-r--r--
c. 相关命令
# 变更目录或文件的权限(可以使用数字,也可以使用字母)
$ hadoop fs -chmod [-R] 777 /user/tree/foo
$ hadoop fs -chmod [-R] u+x,o-x /user/tree/foo
# 变更目录或文件的属主或用户组
$ hadoop fs -chown [-R] tree /user/tree/foo
$ hadoop fs -chown [-R] tree:ogroup /user/tree/foo
# 变更用户组
$ hadoop fs -chgrp [-R] group1 /user/tree/foo
需要注意的是,使用这个命令的用户必须是超级用户或者是该文件的属主,同时也是该用户组的成员。
粘滞位(Sticky bit)用法在目录上设置,如此以来,只有目录内文件的所有者或者 root 才可以删除或移动该文件。如果不为目录设置粘滞位,任何具有该目录写和执行权限的用户都可以删除和移动其中的文件。实际应用中,粘滞位一般用于 /tmp 目录,以防止普通用户删除或移动其他用户的文件。
3.2 用户身份认证
用户身份认证独立于 HDFS 之外,也就说 HDFS 并不负责用户身份合法性检查,但 HDFS 会通过相关接口来获取相关的用户身份,然后用于后续的权限管理。用户是否合法,完全取决于集群使用认证体系。目前社区支持两种身份认证,即简单认证(Simple)和 Kerberos。模式由 hadoop.security.authentication 属性指定,默认 simple。
a. Simple 认证
基于客户端所在的 Linux/Unix 系统的登录用户名来进行认证。只要用户能正常登录就认证成功。客户端与 NameNode 交互时,会将用户的登录账号(通过类似 whoami 的命令来获取)作为合法用户名传递至 Namenode。
这意味着使用不同的账号登录到同一个客户端,会产生不同的用户名,故在多租户条件这种认证会导致权限混淆;同时恶意用户也可以伪造其他人的用户名非法获得相应的权限,对数据安全造成极大的隐患。线上生产环境一般不会使用。
Simple 认证时,HDFS 想法是:防止好人误做坏事,不防止坏人做坏事。
b. Kerberos 认证
在神话里,Kerberos 是 Cerberus 的希腊语,是一只守护地狱入口的三头巨犬,它确保没有人能在进入地狱后离开。
从技术角度来说,Kerberos 是麻省理工学院(MIT)开发的一种网络身份认证协议。它旨在通过使用密钥加密技术为客户端/服务器应用程序提供强身份验证。
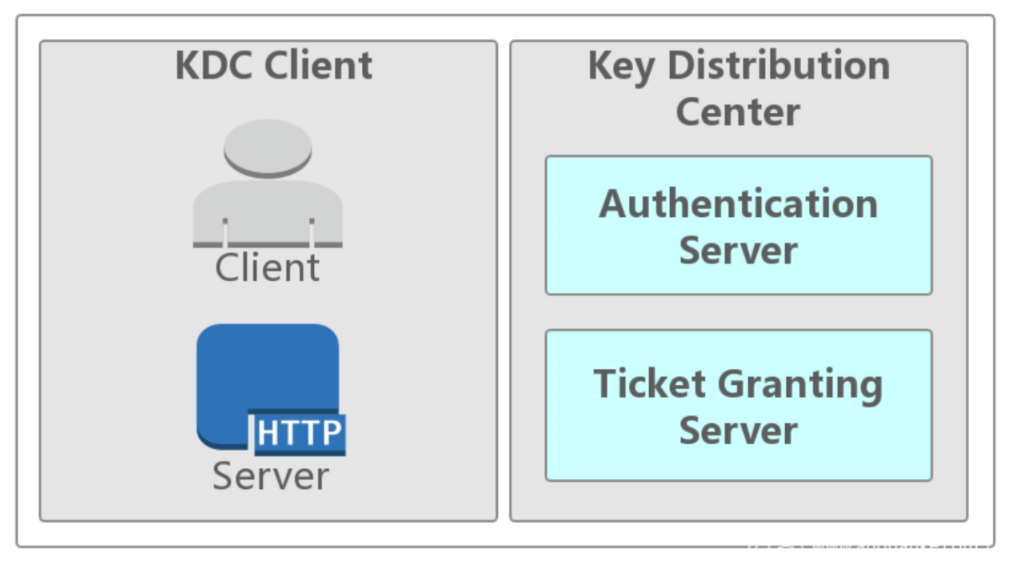
(1)Kerberos 角色
- 访问服务的 Client
- 提供服务的 Server
- KDC(Key Distribution Center)密钥分发中心
(2)Kerberos 域
其中 KDC 服务默认会安装在一个域的域控中,而 Client 和 Server 为域内的用户或者是服务,如 HTTP 服务、SQL 服务。在 Kerberos 中 Client 是否有权限访问 Server 端的服务由 KDC 发放的「票据」来决定。
什么是「域」?
域的产生是为了解决企业内部的资源管理问题,比如一个公司就可以在网络中建立一个域环境,更方便内部的资源管理。在一个域中有域控、域管理员、普通用户、主机等等各种资源。
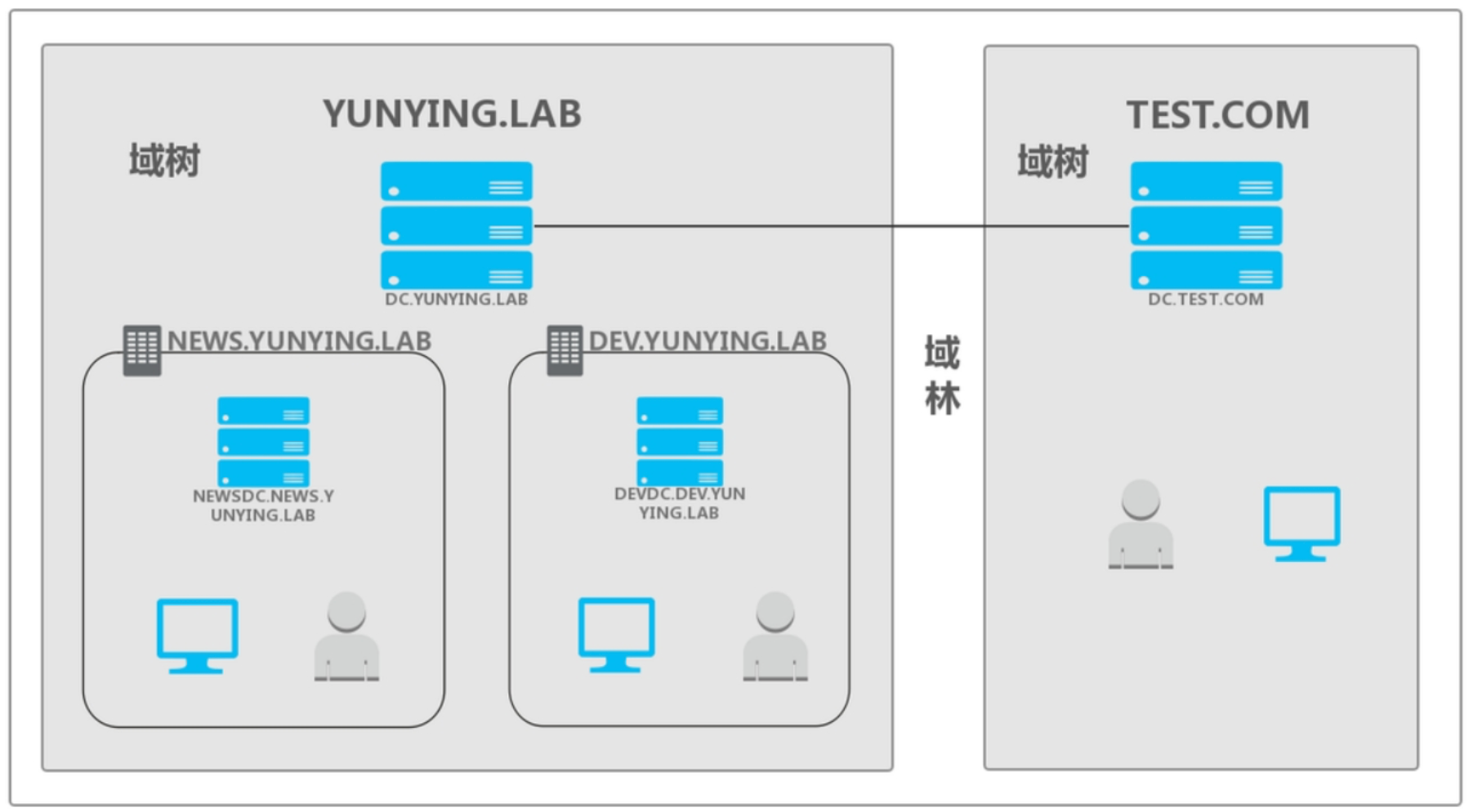
YUNYING.LAB 为其他两个域的「根域」,NEWS.YUNYING.LAB 和 DEV.YUNYING.LAB 均为 YUNYING.LAB 的「子域」,这三个域组成了一个「域树」。子域的概念可以理解为一个集团在不同业务上分公司,他们有业务重合的点并且都属于 YUNYING.LAB 这个根域,但又独立运作。同样 TEST.COM 也是一个单独的域树,两个域树 YUNYING.LAB 和 TEST.COM 组合起来被称为一个「域林」。
(3)Kerberos 票据
如果把 Kerberos 中的票据类比为一张火车票,那么 Client 端就是乘客,Server 端就是火车,而 KDC 就是就是车站的认证系统。如果 Client 端的票据是合法的(由你本人身份证购买并由你本人持有)同时有访问 Server 端服务的权限(车票对应车次正确)那么你才能上车。当然和火车票不一样的是 Kerberos 中有存在两张票,而火车票从头到尾只有一张。
(4)Kerberos KDC
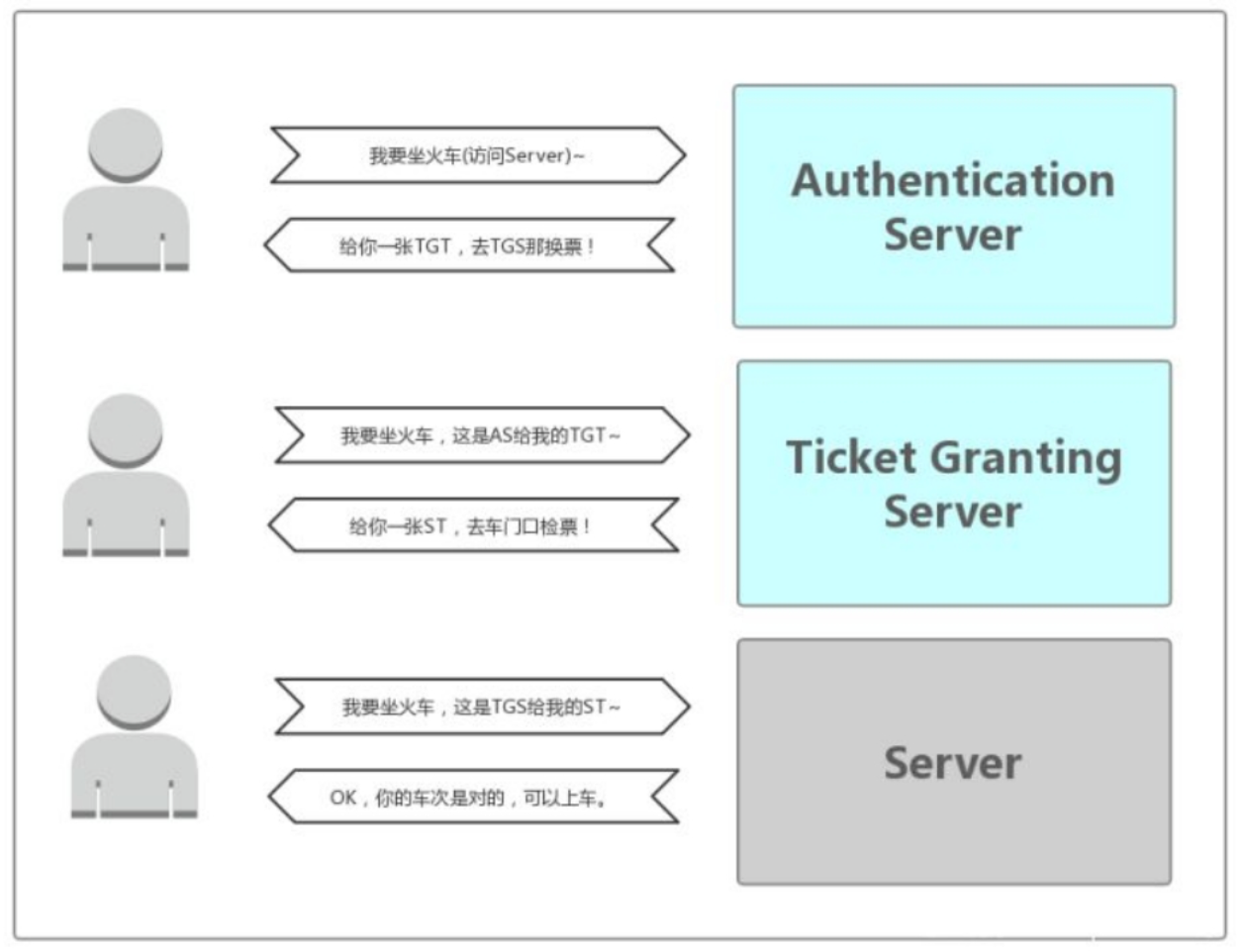
- 【Authentication Server】AS 的作用就是验证 Client 端的身份(确定你是身份证上的本人),验证通过就会给一张 TGT(Ticket Granting Ticket)票给 Client。
- 【Ticket Granting Server】TGS 的作用是通过 AS 发送给 Client 的票(TGT)换取访问 Server 端的票(上车的票 ST)。ST(Service Ticket)也有资料称为 TGS Ticket,为了和 TGS 区分,在这里就用 ST 来说明。
(5)Kerberos 认证流程
3.3 组映射
在通过用户身份认证拿到用户名后之后,NameNode 还需要通过「用户组映射服务」获取该用户所对应的用户组列表,用于后期的用户组权限校验。
在用户身份验证成功之后,接下来会检查该用户所拥有的权限。HDFS 的文件权限也是采用 UGO 模型,分成用户、组和其他权限。但与 Linux/Unix 系统不同,HDFS 的用户和组都是使用字符串存储的,在 Linux/Unix 上通用的 UID 和 GID 是无法在 HDFS 使用的。
此外,HDFS 的组需要通过外部的「用户组关联(Group Mapping)服务」来获取。用户到组的映射可以使用系统自带的方案(使用 NameNode 服务器上的用户组系统),也可以通过其他实现类似功能的插件(LDAP、Ranger等)方式来代替。在拿到用户名后,NameNode 会通过用户组关联服务获取该用户所对应的用户组列表,并用于后期的用户组权限校验。
下面是两种主要的实现方式。
a. 基于 Linux 系统的用户/用户组
Linux/Unix 系统上的用户和用户组信息存储在 /etc/passwd 和 /etc/group 文件中。默认情况下,HDFS 会通过调用外部的 Shell 命令来获取用户的所有用户组列表。
(1)/etc/passwd
一行记录对应着一个用户,每行记录又被冒号(:)分隔为 7 个字段,其格式和具体含义如下:
用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell
其中组标识号字段记录的是用户所属的用户组。它对应着 /etc/group 文件中的一条记录。
(2)/etc/group
文件中每一行各代表一个用户组,每行记录又被冒号(:)分隔为 4 个字段,其格式和具体含义如下:
组名:密码:GID:该用户组中的用户列表
其中最后一个字段列出每个群组包含的所有用户。
需要注意的是,如果该用户组是这个用户的初始组,则该用户不会写入这个字段,可以这么理解,该字段显示的用户都是这个用户组的附加用户。
此方案的优点在于组映射服务十分稳定,不易受外部服务的影响。但是用户和用户组管理涉及到 root 权限等,同时会在服务器上生成大量的用户组,后续管理,特别是自动化运维方面会有较大影响。
b. 基于使用 LDAP 协议的数据库
OpenLDAP 是一个开源 LDAP 的数据库,通过 phpLDAPadmin 等管理工具或相关接口可以方便地添加用户和修改用户组。
略。
3.4 ACL 权限管理
a. 背景介绍
在 UGO 权限中,用户对文件只有三种身份,就是属主(user)、属组(group)和其他人(other):每种用户身份拥有读(read)、写(write)和执行(execute)三种权限。但是在实际工作中,使用 UGO 来控制权限可以满足大部分场景下的数据安全性要求,但是对于一些复杂的权限需求则无能为力。
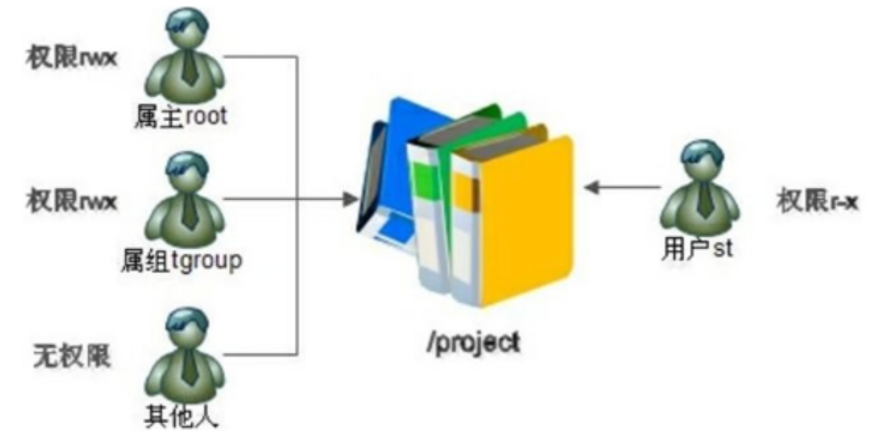
文件系统根目录中有一个 /project 目录,这是班级的项目目录。班级中的每个学员都可以访问和修改这个目录,老师也需要对这个目录拥有访问和修改权限,其他班级的学员当然不能访问这个目录。需要怎么规划这个目录的权限呢?
应该这样:老师使用 root 用户,作为这个目录的属主,权限为 rwx;班级所有的学员都加入 tgroup 组,使 tgroup 组作为 /project目录的属组,权限是 rwx;其他人的权限设定为 0。这样这个目录的权限就可以符合我们的项目开发要求了。
有一天,班里来了一位试听的学员 st,她必须能够访问/project 目录,所以必须对这个目录拥有 r 和 x 权限;但是她又没有学习过以前的课程,所以不能赋予她 w 权限,怕她改错了目录中的内容,所以学员 st 的权限就是 r-x。可是如何分配她的身份呢?变为属主?当然不行,要不 root 该放哪里?加入 tgroup 组?也不行,因为 tgroup 组的权限是 rwx,而我们要求学员 st 的权限是 r-x。如果把其他人的权限改为 r-x 呢?这样一来,其他班级的所有学员都可以访问 /project 目录了。
当出现这种情况时,普通权限中的三种身份就不够用了。ACL 权限就是为了解决这个问题的。在使用 ACL 权限给用户 st 陚予权限时,st 既不是 /project 目录的属主,也不是属组,仅仅赋予用户 st 针对此目录的 r-x 权限。
ACL 是 Access Control List(访问控制列表)的缩写,ACL 提供了一种方法,可以为特定的用户或组设置不同的权限,而不仅仅是文件的所有者和文件的组。
b. Shell 命令
# 显示文件和目录的访问控制列表(ACL)。如果目录具有默认 ACL,则 getfacl 还将显示默认 ACL
$ hadoop fs -getfacl [-R] <path>
# 设置文件和目录的访问控制列表(ACL)
$ hadoop fs [generic options] -setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]
# ls 的输出将在带有 ACL 的任何文件或目录的权限字符串后附加一个'+'字符
$ hadoop fs -ls <args>
操作示例:
# root用户创建文件夹: hadoop fs -mkdir /itheima
# 此时使用普通用户 allenwoon 去操作 /itheima 发现没有 w 权限
$ echo 1 >> 1.txt
$ hadoop fs -put 1.txt /itheima
put: Permission denied: user=allenwoon, access=WRITE, inode="/itheima":root:supergroup:drwxr-xr-x
# 接下来使用 ACL 给 allenwoon 用户单独添加 rwx 权限
$ hadoop fs -setfacl -m user:allenwoon:rwx /itheima
setfacl: The ACL operation has been rejected. Support for ACLs has been disabled by setting dfs.namenode.acls.enabled to false.
# 发现报错,原因是 ACL 功能默认是关闭的。
# 在 hdfs-site.xml 中设置 dfs.namenode.acls.enabled=true,然后重启HDFS集群
# 再次设置 ACL 权限
$ hadoop fs -setfacl -m user:allenwoon:rwx /itheima
# 设置成功之后查看 ACL 权限,发现 allenwoon 权限配置成功
$ hadoop fs -getfacl /itheima
# file: /itheima
# owner: root
# group: supergroup
user::rwx
user:allenwoon:rwx
group::r-x
mask::rwx
other::r-x
# 再使用普通用户allenwoon去操作,发现可以成功了。
# 如果切换其他普通用户,发现还是无法操作
$ echo 2 >> 2.txt
$ hadoop fs -put 2.txt /itheima
put: Permission denied: user=itcast, access=WRITE, inode="/itheima":root:supergroup:drwxrwxr-x
# --------------- ACL其他操作命令 ---------------
# 1、带有ACL的任何文件或目录的权限字符串后附加一个'+'字符
[root@node1 ~]# hadoop fs -ls /
Found 5 items
drwxr-xr-x - root supergroup 0 2021-01-06 20:59 /data
drwxr-xr-x - root supergroup 0 2020-12-31 11:59 /itcast
drwxrwxr-x+ - root supergroup 0 2021-01-07 19:38 /itheima
drwx------ - root supergroup 0 2020-12-31 11:56 /tmp
drwxr-xr-x - root supergroup 0 2020-12-31 11:56 /user
# 2、删除指定的ACL条目
hadoop fs -setfacl -x user:allenwoon /itheima
# 3、删除基本ACL条目以外的所有条目。保留用户,组和其他条目以与权限位兼容。
hadoop fs -setfacl -b /itheima
# 4、设置默认的ACL权限,以后在该目录中新建文件或者子目录时,新建的文件/目录的ACL权限都是之前设置的defaultACLs
$ hadoop fs -setfacl -m default:user:allenwoon:rwx /itheima
$ hadoop fs -getfacl /itheima
# file: /itheima
# owner: root
# group: supergroup
user::rwx
group::r-x
other::r-x
default:user::rwx
default:user:allenwoon:rwx
default:group::r-x
default:mask::rwx
default:other::r-x
# 5、删除默认ACL权限
$ hadoop fs -setfacl -k /itheima
# 6、--set: 完全替换ACL,丢弃所有现有条目。acl_spec必须包含用户,组和其他条目,以便与权限位兼容。
$ hadoop fs -setfacl --set user::rw-,user:hadoop:rw-,group::r--,other::r-- /file
4. HDFS 代理用户
4.1 背景介绍
Proxy 中文称之为代理、委托。用来进行事物不想或不能进行的其他操作。HDFS Proxy user(代理用户)描述的是一个用户(比如超级用户)如何代表另一个用户提交作业或访问 HDFS。
比如:用户名为“Admin”的超级用户代表用户“Allen”提交作业并访问 HDFS。
因为超级用户 Admin 具有 kerberos 凭证,但 Allen 用户没有任何凭证。这些任务需要以用户 Allen 的身份运行,而对 NameNode 的任何文件访问都必须以用户 Allen 的身份进行。要求用户 Allen 可以在通过 Admin 的 kerberos 凭据进行身份验证的连接上连接到 NameNode。换句话说, Admin 正在冒充用户 Allen 。
4.2 使用示例
Admin 的身份凭据用于登录,并为 Allen 创建了代理用户 ugi 对象。在代理用户 ugi 对象的 doAs() 方法内执行操作。
// 为 Allen 创建 ugi,登录用户为 Admin。
UserGroupInformation ugi = UserGroupInformation.createProxyUser("Allen",UserGroupInformation.getLoginUser());
ugi.doAs(new PrivilegedExceptionAction <Void>(){
public Void run() {
// 提交工作
JobClient jc = new JobClient(conf);
jc.submitJob(conf);
// 访问HDFS
FileSystem fs = FileSystem.get(conf);
fs.mkdir(someFilePath);
}
});
4.3 配置参数
可以通过在 core-site.xml 中使用下面属性来配置代理用户:
hadoop.proxyuser.$superuser.hosts
hadoop.proxyuser.$superuser.groups
hadoop.proxyuser.$superuser.users
例:名为 super 的超级用户只能从 host1 和 host2 连接来模拟属于 group1 和 group2 的用户。
<property>
<name>hadoop.proxyuser.super.hosts</name>
<value>host1,host2</value>
</property>
<property>
<name>hadoop.proxyuser.super.groups</name>
<value>group1,group2</value>
</property>
如果不存在这些配置,则将无法进行模拟并且连接将失败。
还有更加宽松的配置,通配符 * 可用于允许来自任何主机或任何用户的模拟。例如,通过在 core-site.xml 中进行如下指定,从任何主机访问的名为 oozie 的用户都可以假冒属于任何组的任何用户。
<property>
<name>hadoop.proxyuser.oozie.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.oozie.groups</name>
<value>*</value>
</property>
注意事项:
如果集群以安全模式运行,则超级用户必须具有 kerberos 凭据才能模拟其他用户。它不能为此功能使用委托令牌。如果超级用户将自己的委派令牌添加到代理用户 ugi,那将是错误的,因为它将允许代理用户使用超级用户的特权连接到服务。
但是,如果超级用户确实希望将委派令牌授予 joe,则它必须首先模拟 joe 并获得 joe 的委派令牌,与上面的代码示例相同,然后将其添加到 joe 的 ugi 中。这样,委派令牌将拥有者为 joe。
5. HDFS 透明加密
5.1 背景&加密层级
HDFS 明文存储弊端
HDFS 中的数据会以 block 的形式保存在各台数据节点的本地磁盘中,但这些 block 都是明文的,如果在操作系统下直接访问 block 所在的目录,通过 Linux 的 cat 命令是可以直接查看里面的内容的,而且是明文。
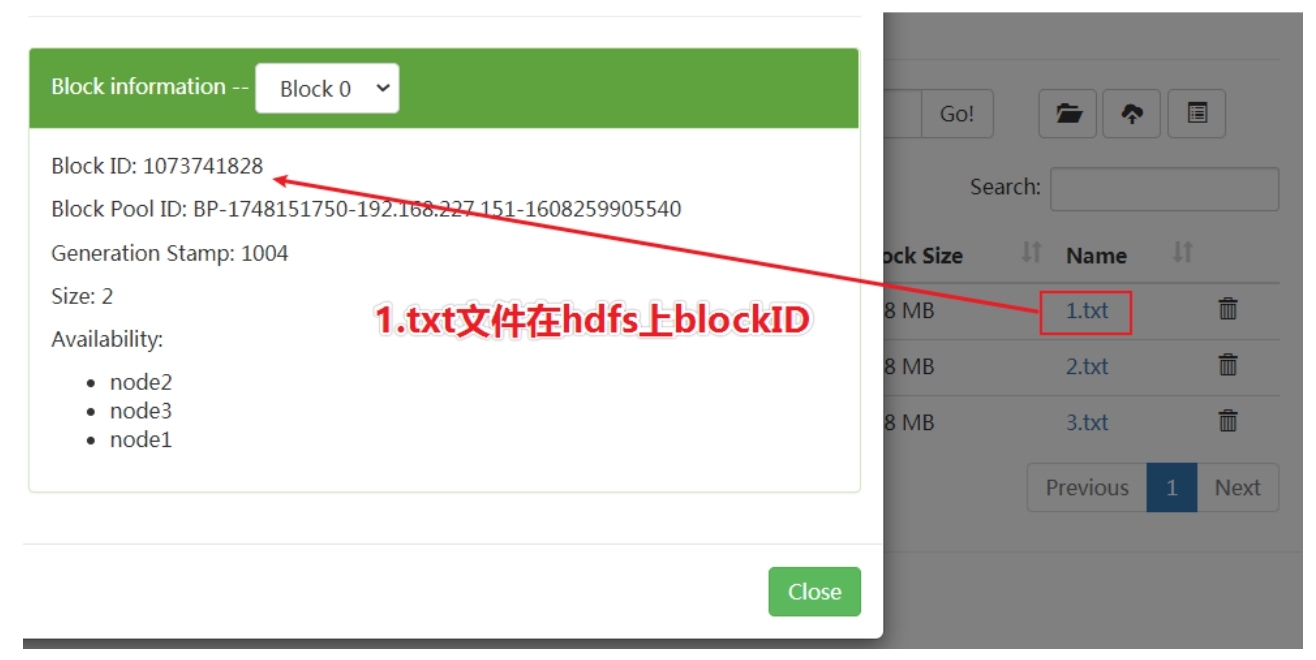
下面我们直接去 DataNode 本地存储 block 的目录,直接查看 block 内容:/export/data/hadoop-3.1.4/dfs/data/current/BP-1748151750-192.168.227.151-1608259905540/current/finalized/subdir0/subdir0/。

数据加密是计算机系统对信息进行保护的一种最可靠的办法。它利用密码技术对信息进行加密,实现信息隐蔽,从而起到保护信息的安全的作用。数据加密通常采用通过加密算法和加密密钥将明文转变为密文,而解密则是通过解密算法和解密密钥将密文恢复为明文。它的核心是密码学。
常见的加密层级
(1)应用层加密
这是最安全也是最灵活的方式。加密内容最终由应用程序来控制,并且可以精确的反映用户的需求。但是,编写应用程序来实现加密一般都比较困难。
(2)数据库层加密
类似于应用程序加密。大多数数据库厂商都提供某种形式的加密,但是可能会有性能问题,另外比如说索引没办法加密。
(3)文件系统层加密
这种方式对性能影响不大,而且对应用程序是透明的,一般也比较容易实施。但是应用程序细粒度的要求策略,可能无法完全满足。比如加密文件系统 (EFS) 用于在 NTFS 文件系统卷上存储已加密的文件。
(4)磁盘层加密
易于部署和高性能,但是相当不灵活,只能防止用户从物理层面盗窃数据。常用的方式有:修改硬盘分区表信息、对硬盘启动加口令、磁盘扇区数据加密等等。
HDFS 的透明加密属于数据库层和文件系统层的加密。拥有不错的性能,且对于现有的应用程序是透明的。HDFS 加密可以防止在文件系统或之下的攻击,也叫操作系统级别的攻击(OS-level attacks)。操作系统和磁盘只能与加密的数据进行交互,因为数据已经被 HDFS 加密了。
5.2 透明加密介绍
HDFS 透明加密(Transparent Encryption)支持端到端的透明加密,启用以后,对于一些需要加密的 HDFS 目录里的文件可以实现透明的加密和解密,而不需要修改用户的业务代码。端到端是指加密和解密只能通过客户端。
对于加密区域里的文件,HDFS 保存的即是加密后的文件,文件加密的秘钥也是加密的。让非法用户即使从操作系统层面拷走文件,也是密文,没法查看。
HDFS 透明加密具有以下功能特点:
- 只有 HDFS 客户端可以加密或解密数据。操作系统和 HDFS 仅使用加密的 HDFS 数据进行交互(block 在操作系统是以加密的形式存储的),从而减轻了操作系统和文件系统级别的威胁。
- 密钥管理在 HDFS 外部。HDFS 无法访问未加密的数据或加密密钥。HDFS 的管理和密钥的管理是独立的职责,由不同的用户角色(HDFS管理员,密钥管理员)承担,从而确保没有单个用户可以不受限制地访问数据和密钥。
- HDFS 使用高级加密标准计数器模式(AES-CTR)加密算法。AES-CTR 支持 128 位加密密钥(默认),或者在安装 Java Cryptography Extension(JCE)无限强度 JCE 时支持 256 位加密密钥。
5.3 相关概念
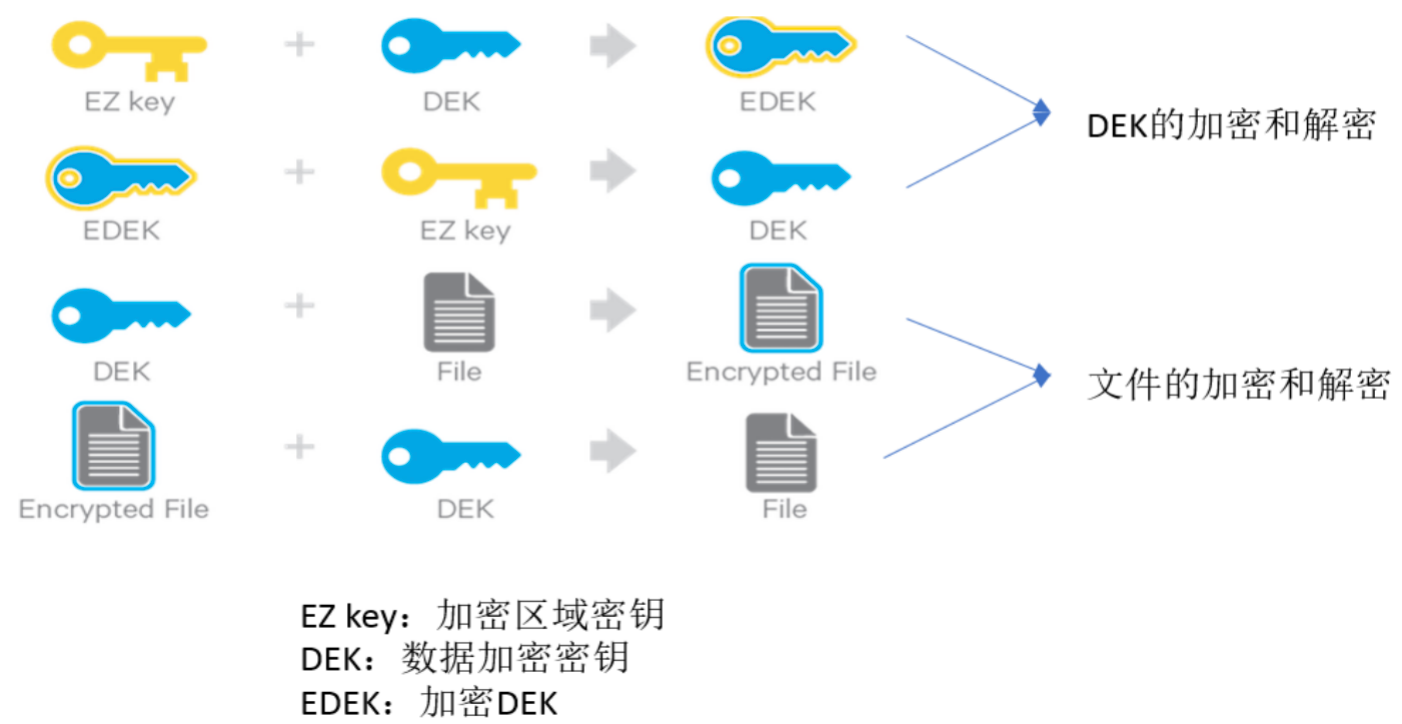
a. 加密区域&密钥
- HDFS 的透明加密有一个新的概念叫「加密区域(the encryption zone)」。加密区域是一个特殊的目录,写入文件的时候会被透明加密,读取文件的时候又会被透明解密。
- 当加密区域被创建时,都会有一个「加密区域秘钥(EZ 密钥,encryption zone key)」与之对应,EZ 密钥存储在 HDFS 外部的备份密钥库中。
- 加密区域里的每个文件都有其自己加密密钥,叫做「数据加密秘钥(DEK,data encryption key)」。
- DEK 会使用其各自的加密区域的 EZ 密钥进行加密,以形成「加密数据加密密钥(EDEK)」。客户端会解密 EDEK,然后用后续的 DEK 来读取和写入数据。
关于 EZ 密钥、DEK、EDEK 三者关系如下所示:
b. keystore&HadoopKMS
存储密钥(key)的叫做密钥库(keystore),将 HDFS 与外部企业级密钥库(keystore)集成是部署透明加密的第一步。这是因为密钥(key)管理员和 HDFS 管理员之间的职责分离是此功能的非常重要的方面。但是,大多数密钥库都不是为 Hadoop 工作负载所见的加密/解密请求速率而设计的。
为此,Hadoop 进行了一项新服务的开发,该服务称为 Hadoop 密钥管理服务器(Key Management Server,简写 KMS),该服务用作 HDFS 客户端与密钥库之间的代理。密钥库和 Hadoop KMS 相互之间以及与 HDFS 客户端之间都必须使用 Hadoop 的 KeyProvider API 进行交互。
KMS 主要有以下几个职责:
- 提供访问保存的加密区域秘钥(EZ key)
- 生成 EDEK,EDEK 存储在 NameNode 上
- 为 HDFS 客户端解密 EDEK
c. 访问加密区域内的文件
(1)写入加密文件过程
【前提】创建 HDFS 加密区时会创建一个 HDFS 加密区(目录),同时会在 KMS 服务里创建一个 key 和 EZ Key 及两者之间的关联。
- Client 向 NN 请求在 HDFS 某个加密区新建文件;
- NN 从缓存中取出一个新的 EDEK(后台不断从 KMS 拉取新的 EDEK 到缓存中,KMS 用对应的 EZ key 生成一个新的 EDEK 发送给 NN);
- 这个 EDEK 会被 NN 写入到文件的 metadata 中;
- NN 发送 EDEK 给 Client;
- Client 发送 EDEK 给 KMS 请求解密,KMS 用对应的 EZ key 将 EDEK 解密为 DEK 发送给 Client(EDEK + EZ key = DEK);
- Client 用 DEK 加密文件内容发送给 DataNode 进行存储(DEK + File = EncryptedFile)。

DEK 是加解密一个文件的密匙,而 KMS 里存储的 EZ key 是用来加解密所有文件的密匙(DEK)的密匙。所以,EZ Key 是更为重要的数据,只在 KMS 内部使用(DEK 的加解密只在 KMS 内存进行),不会被传递到外面使用,而 HDFS 服务端只能接触到 EDEK,所以 HDFS 服务端也不能解密加密区文件。
(2)读取解密文件过程
读流程与写流程类型,区别就是 NN 直接读取加密文件元数据里的 EDEK 返回给客户端,客户端一样把 EDEK 发送给 KMS 获取 DEK。再对加密内容解密读取。
EDEK 的加密和解密完全在 KMS 上进行。更重要的是,请求创建或解密 EDEK 的客户端永远不会处理 EZ 密钥。仅 KMS 可以根据要求使用 EZ key 密钥创建和解密 EDEK。
5.4 KMS 配置
(1)关闭 HDFS 集群
在 node1 上执行 stop-dfs.sh
(2)keystore 密钥库
存储密钥(key)的地方叫做密钥库(keystore)。HDFS 与 keystore 是互相独立的,两者之间通过 KMS 进行沟通。KMS 可以选择任何 KeyProvider(密钥供应者)实现作为 keystore 。此处的示例使用 JavaKeyStoreProvider 来作为 keystore。
$ keytool -genkey -alias 'itcast'
Enter keystore password:
Re-enter new password:
What is your first and last name?
[Unknown]:
What is the name of your organizational unit?
[Unknown]:
What is the name of your organization?
[Unknown]:
What is the name of your City or Locality?
[Unknown]:
What is the name of your State or Province?
[Unknown]:
What is the two-letter country code for this unit?
[Unknown]:
Is CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown correct?
[no]: yes
Enter key password for <itcast>
(RETURN if same as keystore password): <<<<< 在此输入密码 >>>>>
Re-enter new password: <<<<< 在此输入密码 >>>>>
(3)配置 kms-site.xml
<configuration>
<!-- 设置密钥库的提供者:这里设置 jceks,表示就是 java 密钥库。 -->
<property>
<name>hadoop.kms.key.provider.uri</name>
<value>jceks://file@/${user.home}/kms.jks</value>
</property>
<!-- KMS 访问 java 密钥库的密码文件(文件名就叫 kms.keystore.password)需配置在 Hadoop 的配置目录下 -->
<property>
<name>hadoop.security.keystore.java-keystore-provider.password-file</name>
<value>kms.keystore.password</value>
</property>
<property>
<name>dfs.encryption.key.provider.uri</name>
<value>kms://http@node1:16000/kms</value>
</property>
<property>
<name>hadoop.kms.authentication.type</name>
<value>simple</value>
</property>
</configuration>
(4)KMS 访问 Java 密钥库的密码文件需配置在 Hadoop 的配置目录下

(5)kms-env.sh
export KMS_HOME=/export/server/hadoop-3.1.4
export KMS_LOG=${KMS_HOME}/logs/kms
export KMS_HTTP_PORT=16000
export KMS_ADMIN_PORT=16001
(6)core/hdfs-site.xml
<!-- core-site.xml -->
<property>
<name>hadoop.security.key.provider.path</name>
<value>kms://http@node1:16000/kms</value>
</property>
<!-- hdfs-site.xml -->
<property>
<name>dfs.encryption.key.provider.uri</name>
<value>kms://http@node1:16000/kms</value>
</property>
记得同步配置文件到其他节点~
(7)服务启动
- KMS 服务启动:
hadoop --daemon start kms - HDFS 集群启动:
start-dfs.sh

5.5 透明加密使用
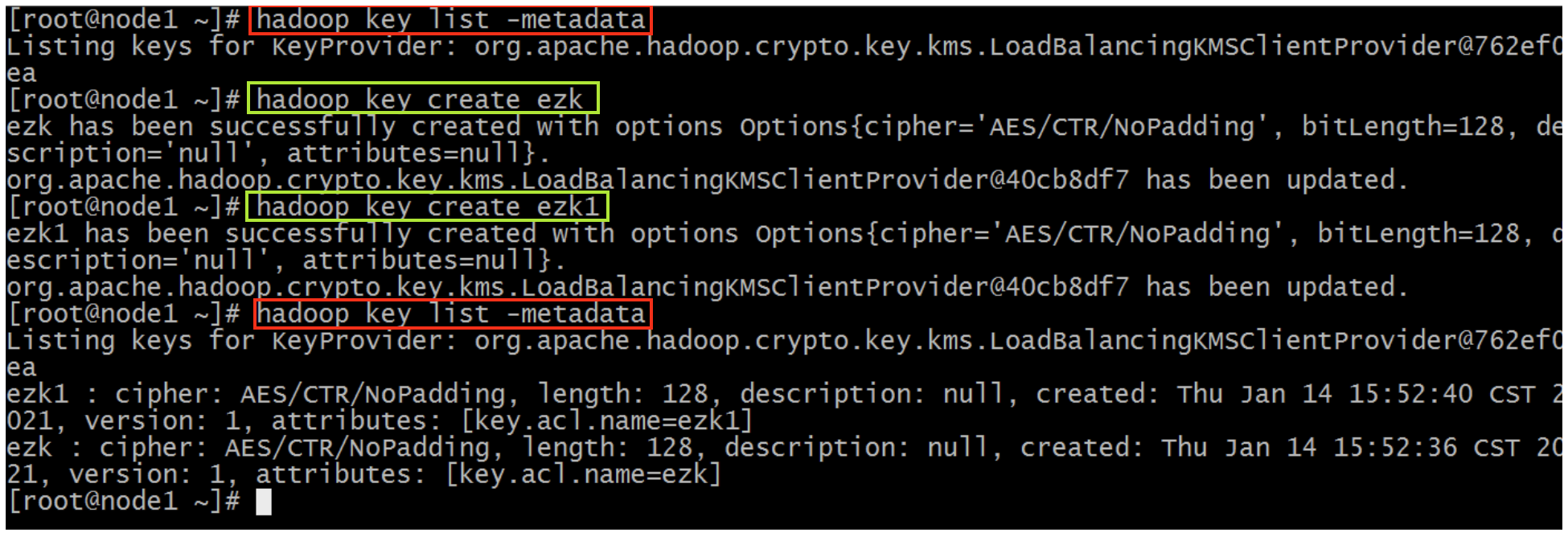
(1)创建 key
创建的 key 用于后面创建加密空间时,指定加密空间的 EZ key。
$ hadoop key create <XXX>
$ hadoop key list -metadata
(2)创建加密区
首先创建一个目录,然后把该目录设置为加密区。
hadoop fs -mkdir /zone
hdfs crypto -createZone -keyName ezk -path /zone

(3)测试加密效果
# 上传文件到加密区,然后读取文件内容
$ echo helloitcast >> helloWorld
$ hadoop fs -put helloWorld /zone
$ hadoop fs -cat /zone/helloWorld
# 获取文件加密信息
$ hdfs crypto -getFileEncryptionInfo -path /zone/helloWorld

切换不同用户进行文件读取操作只要具备 read 权限都可以读取文件的内容。也就是对客户端来说是透明的,感觉不到文件被加密。但如果直接从 DataNode 的机器的本地文件系统读取 Block 信息,发现是无法读取数据的。因为在存储数据的时候被加密了。