[27] Redis 通讯协议及事件处理机制
1. 通信协议
Redis 是单进程单线程的。 应用系统和 Redis 通过 Redis 序列化协议(REdis Serialization Protocol,简称 RESP)进行交互。
1.1 请求响应模式
Redis 协议位于 TCP 层之上,即客户端和 Redis 实例保持双工的连接。
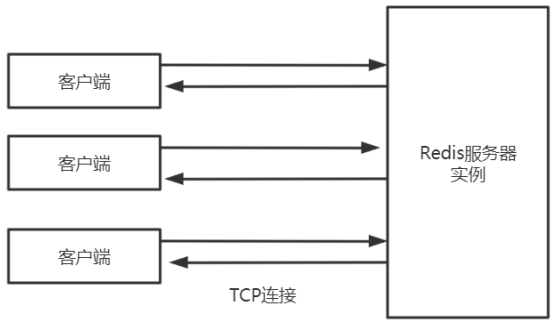
a. 串行的请求响应模式(pingpong)
- 串行化是最简单模式,客户端与服务器端建立长连接;连接通过心跳机制检测(ping-pong);
- 客户端发送请求,服务端响应,客户端收到响应后,再发起第二个请求,服务器端再响应;
- telnet 和 redis-cli 发出的命令,都属于该种模式;
- 特点: 有问有答;耗时在网络传输命令;性能较低
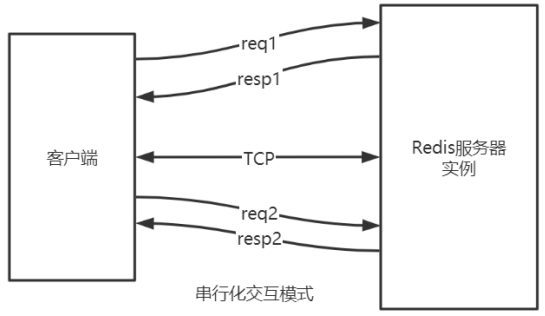
b. 双工的请求响应模式(pipeline)
- 批量请求,批量响应;
- 请求响应交叉进行,不会混淆(TCP 双工)
- pipeline 的作用是将一批命令进行打包,然后发送给服务器,服务器执行完按顺序打包返回。
- 通过 pipeline,一次 pipeline(n 条命令)= 1 次网络时间 + n 次命令时间
c. 原子化的批量请求响应模式(事务)
Redis 可以利用事务机制批量执行命令。详见《Redis 事务》。
d. 发布订阅模式(pub/sub)
一个客户端触发,多个客户端被动接收,通过服务器中转。
e. 脚本化的批量执行(Lua)
客户端向服务器端提交一个 Lua 脚本,服务器端执行该脚本。
1.2 请求数据格式
简要说明:
- Redis 客户端与服务器交互采用序列化协议(RESP);
- 请求以字符串数组的形式来表示要执行命令的参数;
- Redis 使用命令特有(command-specific)数据类型作为回复;
Redis 通信协议的主要特点有:
- 客户端和服务器通过 TCP 连接来进行数据交互,服务器默认的端口号为 6379。
- 客户端和服务器发送的命令或数据一律以
\r\n(CRLF)结尾; - 在这个协议中,所有发送至 Redis 服务器的参数都是二进制安全(binary safe)的。
- 简单,高效,易读。
a. 内联格式
如果你需要给 Redis 服务器发命令,但是手头只有 telnet 工具怎么办呢?尽管 Redis 协议是很容易实现的,但是用这种交互型的工具实现 Redis 协议也不是理想的工具。
因此 Redis 也可以用一种特殊的方式接受人类可读的命令,称为内联格式(inline command)。如下是客户端服务器用内联格式的例子:

b. 规范格式
- 间隔符号在Linux下是
\r\n,在Windows下是\n; - 简单字符串 Simple Strings 以
+开头; - 错误 Errors 以
-开头; - 整数型 Integer 以
:开头; - 大字符串类型 Bulk Strings 以
$开头,长度限制 512M; - 数组类型 Arrays 以
*开头。
用 SET 命令来举例说明 RESP 协议的格式:
redis> SET mykey Hello
"OK"
# ------ 实际发送的请求数据 ------
*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$5\r\nHello\r\n
*3
$3
SET
$5
mykey
$5
Hello
# ------ 实际收到的响应数据 ------
+OK\r\n
1.3 命令处理流程
整个流程包括:服务器启动监听、接收命令请求并解析、执行命令请求、返回命令回复等。
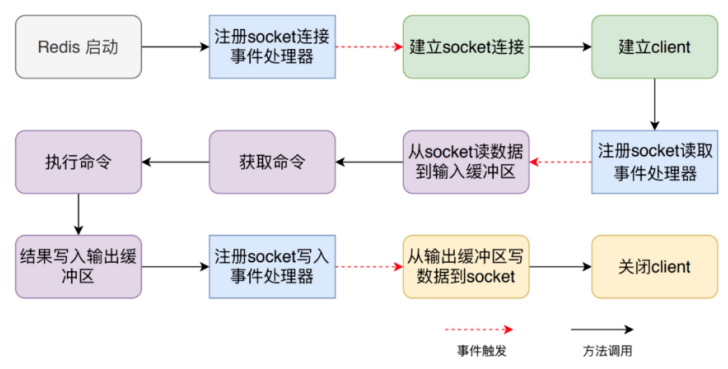
a. Server启动时监听socket
启动调用 initServer 方法:
- 创建 EventLoop(事件机制)
- 注册时间事件处理器
- 注册文件事件(socket)处理器
- 监听 socket 建立连接
b. 建立Client
- redis-cli 建立socket
- redis-server 为每个连接(socket)创建一个 Client 对象
- 创建文件事件监听socket
- 指定事件处理函数
c. 读取socket数据到输入缓冲区
从client中读取客户端的查询缓冲区内容。
d. 解析获取命令
将输入缓冲区中的数据解析成对应的命令。
判断是单条命令还是多条命令并调用相应的解析器解析。
e. 执行命令
解析成功后调用 processCommand 方法执行命令:
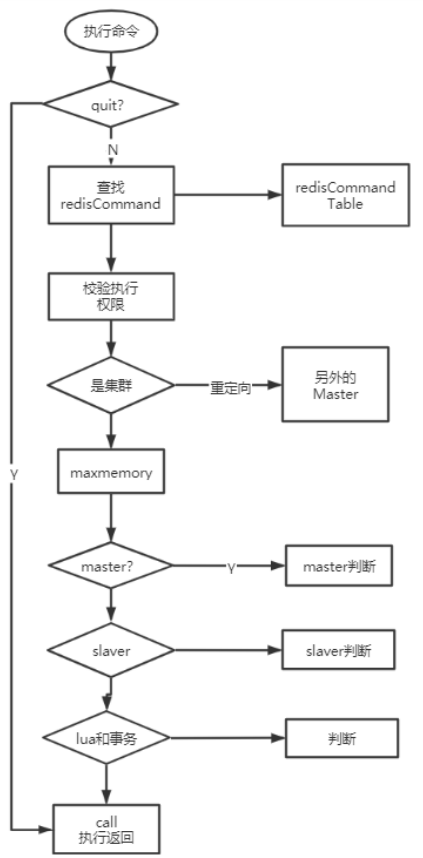
大致分 3 个部分:
- 调用 lookupCommand 方法获得对应的 redisCommand;
- 检测当前 Redis 是否可以执行该命令
- 调用 call 方法真正执行命令
1.4 协议响应格式
a. 状态回复
对于状态,回复的第一个字节是“+”。
"+OK"
b. 错误回复
对于错误,回复的第一个字节是“ - ”。
-ERR unknown command 'foobar'
-WRONGTYPE Operation against a key holding the wrong kind of value
c. 整数回复
对于整数,回复的第一个字节是”:“。
":6"
d. 批量回复
对于批量字符串,回复的第一个字节是“$”。
"$6 foobar"
e. 多条批量回复
对于多条批量回复(数组),回复的第一个字节是“*”。
"*3"
1.5 协议解析及处理
包括协议解析、调用命令、返回结果。
a. 协议解析
用户在 Redis 客户端键入命令后,redis-cli 会把命令转化为 RESP 协议格式,然后发送给服务器。
(1)解析命令请求参数数量
命令请求参数数量的协议格式为 *N\r\n ,其中 N 就是数量,比如:
127.0.0.1:6379> set name:1 tree6x7
我们打开 AOF 文件可以看到协议内容:
*3(/r/n)
$3(/r/n)
set(/r/n)
$7(/r/n)
name:10(/r/n)
$7(/r/n)
tree6x7(/r/n)
首字符必须是 *,使用 \r 定位到行尾,之间的数就是参数数量了。
(2)循环解析请求参数
首字符必须是 $,使用 /r 定位到行尾,之间的数是参数的长度,从 /n 后到下一个 $ 之间就是参数的值了。循环解析直到没有 $。
b. 协议执行
协议的执行包括命令的调用和返回结果。
判断参数个数和取出的参数是否一致;RedisServer 解析完命令后,会调用函数 processCommand 处理该命令请求。
- quit 校验,如果是
quit命令,直接返回并关闭客户端l; - 命令语法校验,执行 lookupCommand 查找命令,如果不存在则返回“unknown command”错误。;
- 参数数目校验,参数数目和解析出来的参数个数要匹配,如果不匹配则返回“wrong number of arguments”错误;
- 此外还有权限校验、最大内存校验、集群校验、持久化校验等等。
校验成功后,会调用 call 函数执行命令,并记录命令执行时间和调用次数。如果执行命令时间过长还要记录慢查询日志。
执行命令后返回结果的类型不同则协议格式也不同,分为 5 类:状态回复、错误回复、整数回复、批量 回复、多条批量回复。
2. 事件处理机制
Redis 服务器是一个事件驱动程序,服务器需要处理以下两类事件:
- 文件事件(File Event):Redis 服务器通过套接字与客户端(或其他 Redis 服务器)进行连接,而文件事件就是服务器对套接字操作的抽象。服务器与客户端(或者其他服务器)的通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列网络通信操作;
- 时间事件(Time Event):Redis 服务器中的一些操作(比如 serverCron 函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。
2.1 文件事件
Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为〈文件事件处理器 File Event Handler〉。
- 文件事件处理器使用 IO 多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器;
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行,但通过使用 IO 多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
a. 文件事件处理器构成
有四个组成部分,分别是套接字、IO多路复用程序、文件事件分派器(dispatcher)以及事件处理器。
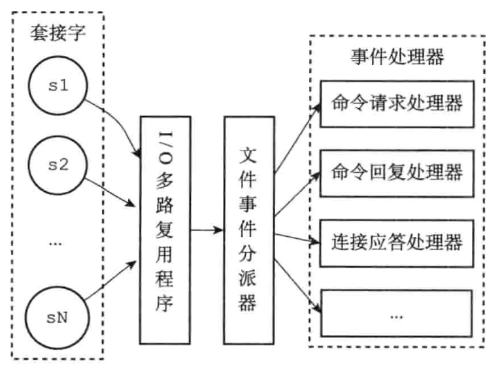
文件事件是对套接字操作的抽象,每当一个套接字准备好执行连接应答、写入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。
IO 多路复用程序负责监听多个套接字,并向文件事件分配器传送那些产生了事件的套接字。
尽管多个文件事件可能会并发地出现,但 IO 多路复用程序总是会将所有产生事件的套接字都放到一个队列里面,然后通过这个队列,以有序、同步、每次一个套接字的方式向文件事件分派器传送套接字。当上一个套接字产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕),IO 多路复用程序才会继续向文件事件分派器传送下一个套接字。

文件事件分配器接收 IO 多路复用程序传来的套接字,并根据套接字产生的事件的类型,调用相应的事件处理器。
服务器会为执行不同任务的套接字关联不同的事件处理器,这些处理器是一个个函数,他们定义了某种事件发生时,服务器应该执行的动作。
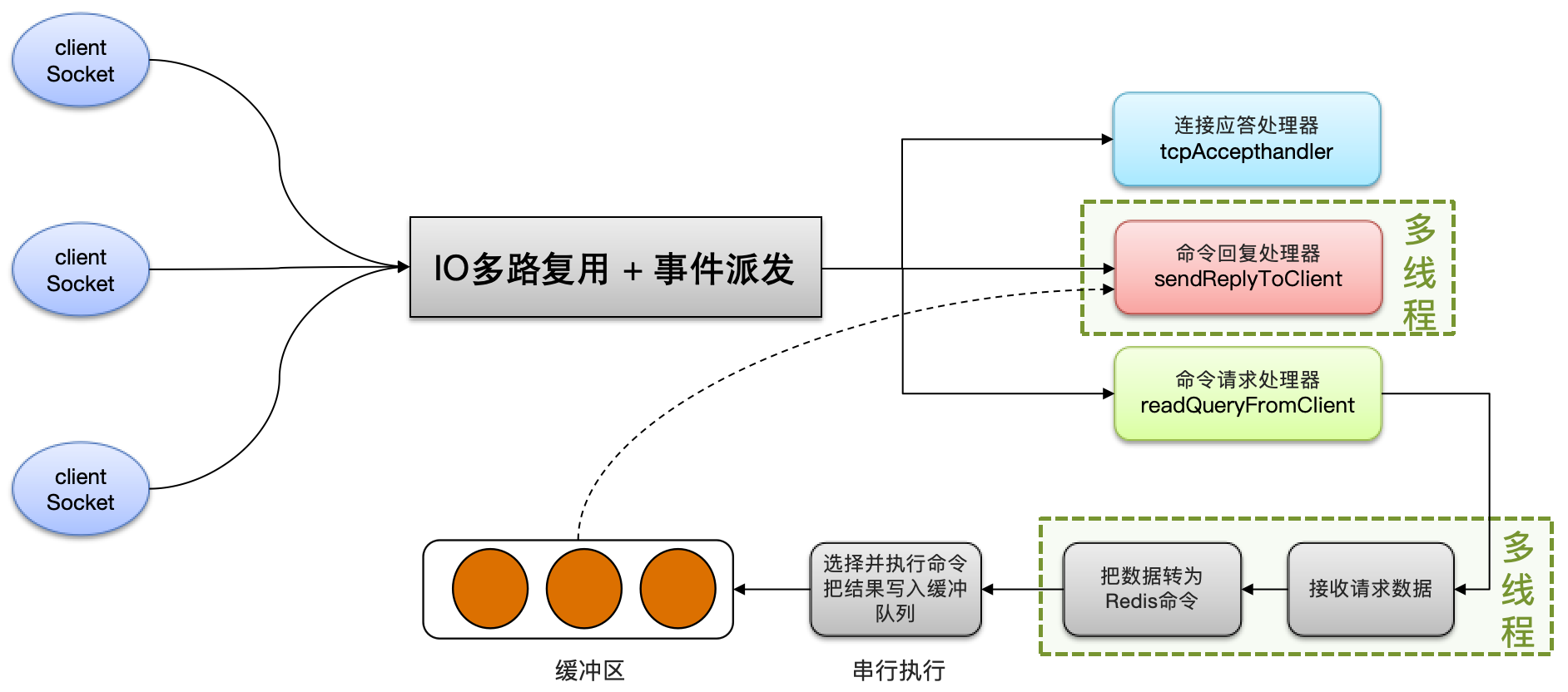
- 命令回复处理器,在 Redis6.0 之后,为了提升更好的性能,使用多线程来处理回复事件;
- 命令请求处理器,在 Redis6.0 之后,将命令的转换使用了多线程,以增加命令转换速度。但在命令执行的时候,依然是单线程。
b. IO多路复用程序实现
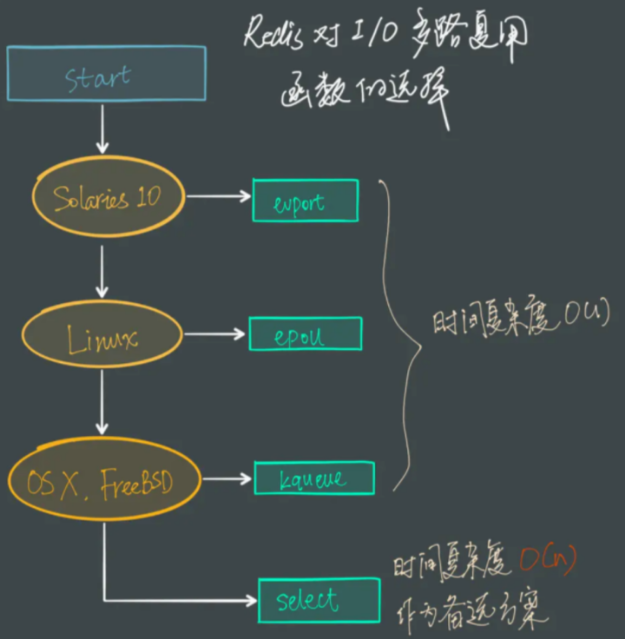
I/O 多路复用是指利用单个线程来同时监听多个 Socket ,并在某个 Socket 可读、可写时得到通知,从而避免无效的等待,充分利用 CPU 资源。目前的 I/O 多路复用都是采用的 epoll 模式实现,它会在通知用户进程 Socket 就绪的同时,把已就绪的 Socket 写入用户空间,不需要挨个遍历 Socket 来判断是否就绪,提升了性能。
- select 和 poll 只会通知用户进程有 Socket 就绪,但不确定具体是哪个 Socket ,需要用户进程逐个遍历 Socket 来确认;
- epoll 则会在通知用户进程 Socket 就绪的同时,把已就绪的 Socket 写入用户空间。
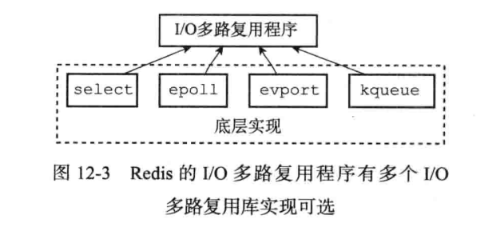
Redis 的 IO 多路复用程序的所有功能都是通过包装常见的 select、epoll、evport 和 kqueue 这些 IO 多路复用函数库来实现的,每个 IO 多路复用函数库在 Redis 源码中都对应一个单独的文件,比如 ae_select.c、ae_epoll、ae_kqueue.c,诸如此类。
因为 Redis 为每个 IO 多路复用函数库都实现了相同的 API,所以 IO 多路复用程序的底层实现是可以互换的。
为什么都保留?
c. 事件的类型
IO 多路复用程序可以监听多个套接字的 ae.h/AE_READABLE 事件和 ae.h/AE_WRITABLE 事件,这两类事件和套接字操作之间的对应关系如下:
- 当套接字变得可读时(客户端对套接字执行 write 操作,或者执行 close 操作),或者有新的可应答(acceptable)套接字出现时(客户端对服务器的监听套接字执行 connect 操作),套接字产生
AE_READABLE事件; - 当套接字变得可写时(客户端对套接字执行 read 操作),套接字产生
AE_WRITEABLE事件。
IO 多路复用程序允许服务器同时监听套接字的 AE_READABLE 事件和 AE_WRITABLE 事件,如果一个套接字同时产生了这两种事件,那么文件事件分派器会优先处理 AE_READABLE 事件,等到 AE_READABLE 事件处理完毕后,才处理 AE_WRITABLE 事件。
这也就是说,如果一个套接字又可读又可写,那么服务器将先读套接字,后写套接字。
d. 文件事件的处理器
Redis 为文件事件编写了多个处理器,这些事件处理器分别用于实现不同的网络通信需求,比如说:
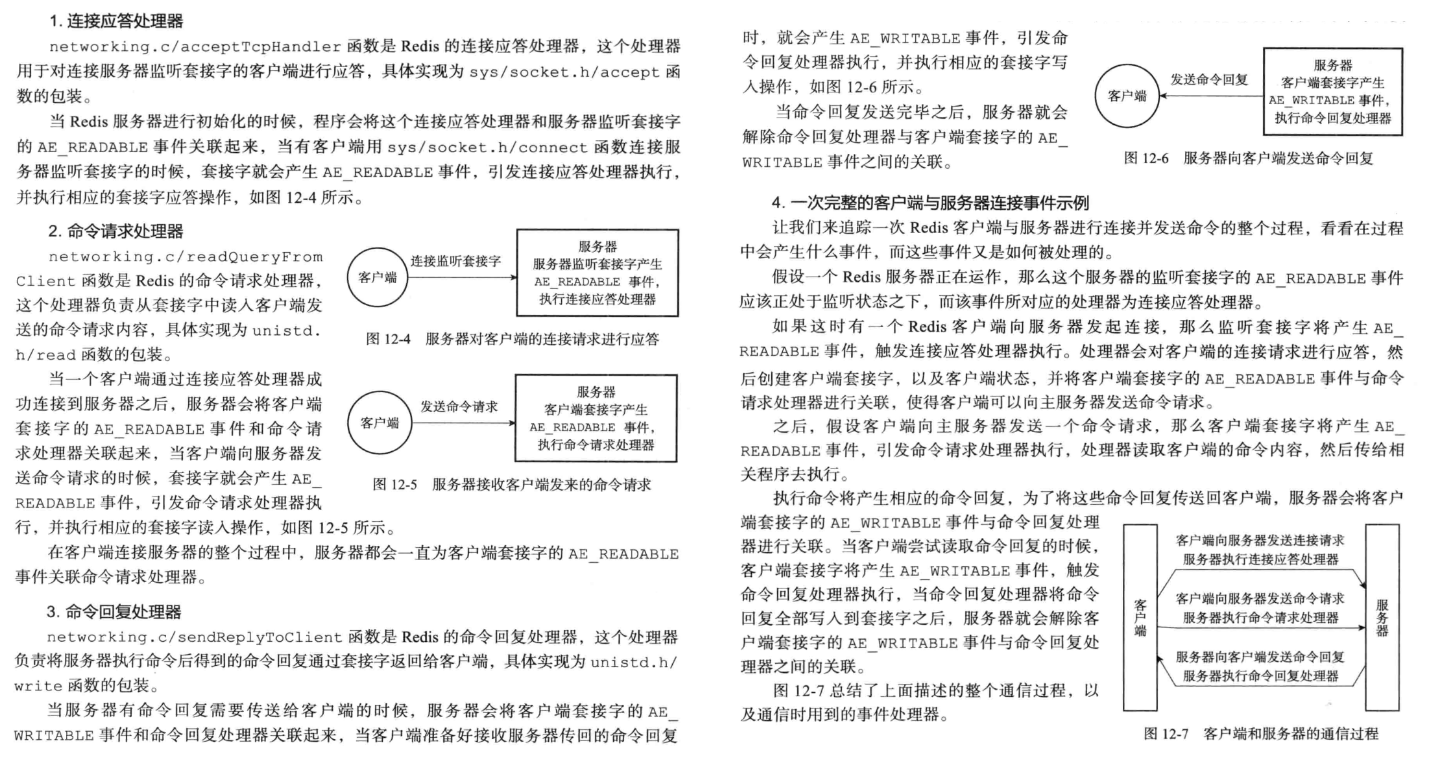
- 为了对连接服务器的各个客户端进行应答,服务器要为〈客户端套接字〉关联〈连接应答处理器〉;
- 为了接收客户端传来的命令请求,服务器要为〈客户端套接字〉关联〈命令请求处理器〉;
- 为了向客户端返回命令的执行结果,服务器要为〈客户端套接字〉关联〈命令回复处理器〉;
- 当主服务器和从服务器进行复制操作时,主从服务器都需要关联特别为复制功能编写的〈复制处理器〉;
在这些事件处理器里面,服务器最常用的要数与客户端进行通信的连接应答处理器、命令请求处理器和命令回复处理器。
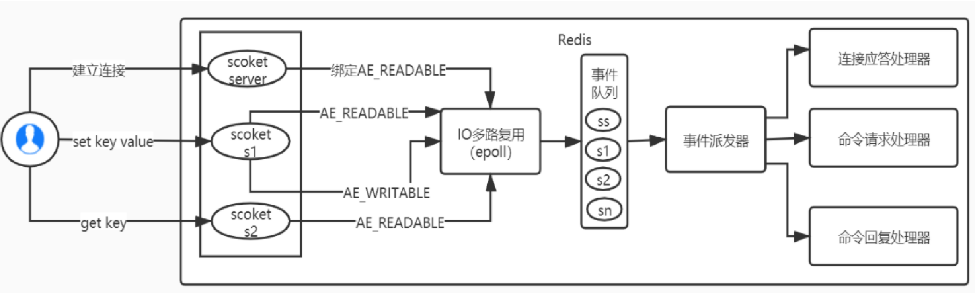
来看客户端与 Redis 的一次通信过程:
要明白,通信是通过 socket 来完成的,不懂的同学可以先去看一看 socket 网络编程。
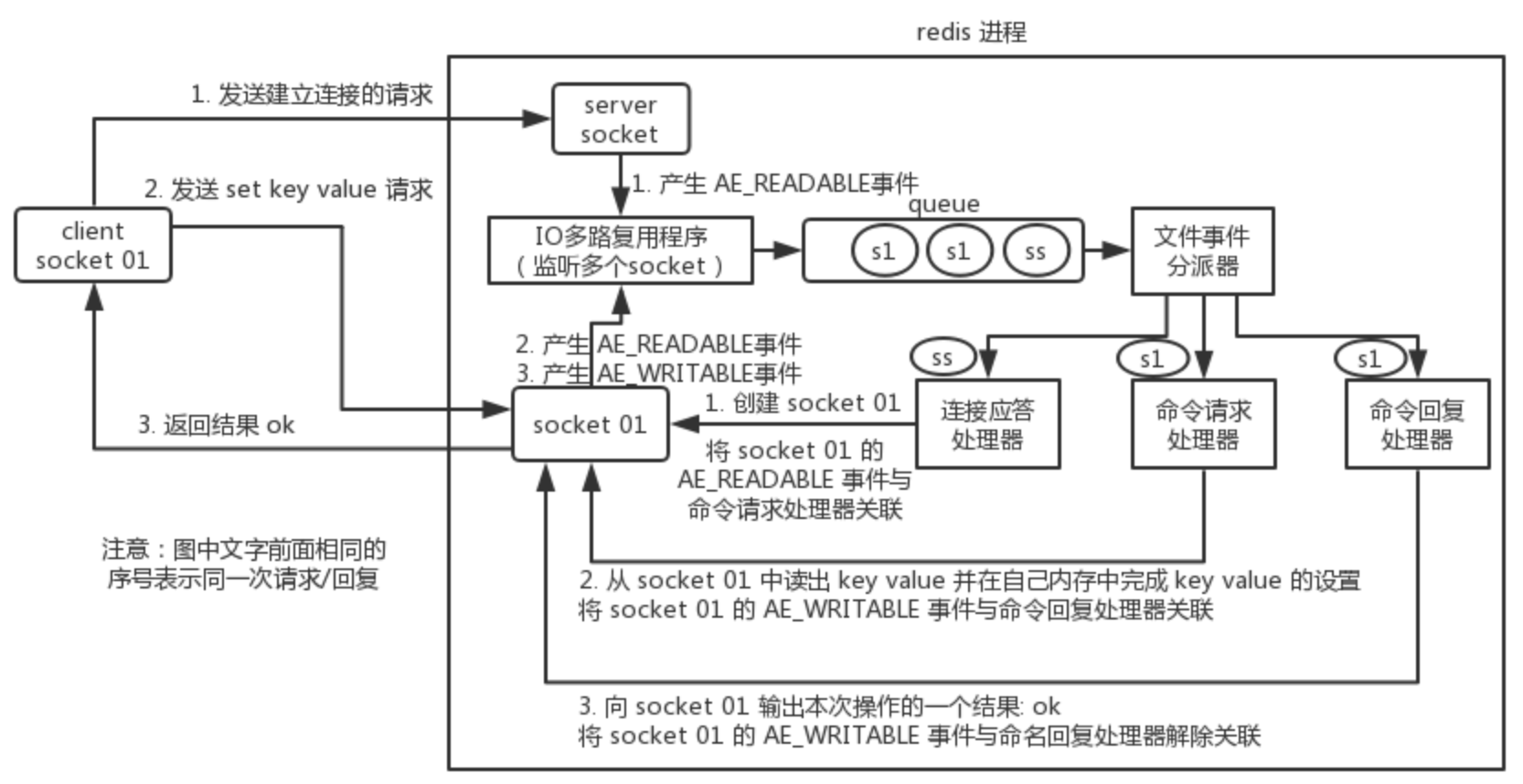
首先,redis 服务端进程初始化的时候,会将 server socket 的 AE_READABLE 事件与连接应答处理器关联。
客户端 socket01 向 redis 进程的 server socket 请求建立连接,此时 server socket 会产生一个 AE_READABLE 事件,IO 多路复用程序监听到 server socket 产生的事件后,将该 socket 压入队列中。文件事件分派器从队列中获取 socket,交给连接应答处理器。连接应答处理器会创建一个能与客户端通信的 socket01,并将该 socket01 的 AE_READABLE 事件与命令请求处理器关联。
假设此时客户端发送了一个 set key value 请求,此时 redis 中的 socket01 会产生 AE_READABLE 事件,IO 多路复用程序将 socket01 压入队列,此时事件分派器从队列中获取到 socket01 产生的 AE_READABLE 事件,由于前面 socket01 的 AE_READABLE 事件已经与命令请求处理器关联,因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取 socket01 的 key value 并在自己内存中完成 key value 的设置。操作完成后,它会将 socket01 的 AE_WRITABLE 事件与命令回复处理器关联。
如果此时客户端准备好接收返回结果了,那么 redis 中的 socket01 会产生一个 AE_WRITABLE 事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对 socket01 输入本次操作的一个结果,比如 ok,之后解除 socket01 的 AE_WRITABLE 事件与命令回复处理器的关联。
服务器会为执行不同任务的套接字关联不同的事件处理器,这些处理器是一个个函数,他们定义了某种事件发生时,服务器应该执行的动作。
(1)连接处理函数 acceptTCPHandler
当客户端向 Redis 建立 socket 时,aeEventLoop 会调用 acceptTcpHandler 处理函数,服务器会为每个连接创建一个 Client 对象,并创建相应文件事件来监听 socket 的可读事件,并指定事件处理函数。

(2)请求处理函数 readQueryFromClient
当客户端通过 socket 发送来数据后,Redis 会调用 readQueryFromClient 方法,readQueryFromClient 方法会调用 read 方法从 socket 中读取数据到输入缓冲区中,然后判断其大小是否大于系统设置的 client_max_querybuf_len,如果大于,则向 Redis返回错误信息,并关闭 Client。

(3)命令回复处理器 sendReplyToClient
sendReplyToClient 函数是 Redis 的命令回复处理器,这个处理器负责将服务器执行命令后得到的结果通过套接字返回给客户端。
- 将 OutBuf 内容写入到套接字描述符并传输到客户端;
- aeDeleteFileEvent 用于删除文件写事件
2.2 时间事件
时间事件分为定时事件与周期事件。
a. 时间事件结构
- id(全局唯一 id)
- when(毫秒时间戳,记录了时间事件的到达时间)
- timeProc(时间事件处理器,当时间到达时,Redis 就会调用相应的处理器来处理事件)

b. serverCron函数
时间事件的最主要的应用是在 Redis 服务器需要对自身的资源与配置进行定期的调整,从而确保服务器的长久运行,这些操作由 redis.c 中的 serverCron 函数实现,其主要进行以下操作:
- 更新 Redis 服务器各类统计信息,包括时间、内存占用、数据库占用等情况;
- 清理数据库中的过期键值对;
- 关闭和清理连接失败的客户端;
- 尝试进行 AOF 和 RDB 持久化操作;
- 如果服务器是主服务器,会定期将数据向从服务器做同步操作;
- 如果处于集群模式,对集群定期进行同步与连接测试操作。
// 使用一个宏定义:run_with_period(milliseconds) { .... },实现一部分代码有次数限制的被执行
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
int j;
UNUSED(eventLoop);
UNUSED(id);
UNUSED(clientData);
// 如果设置了看门狗,则在过期时间内,递达一个 SIGALRM 信号
if (server.watchdog_period) watchdogScheduleSignal(server.watchdog_period);
// 设置服务器的时间缓存
updateCachedTime();
// 更新服务器的一些统计值
run_with_period(100) {
// 命令执行的次数
trackInstantaneousMetric(STATS_METRIC_COMMAND,server.stat_numcommands);
// 从网络读到的字节数
trackInstantaneousMetric(STATS_METRIC_NET_INPUT,
server.stat_net_input_bytes);
// 已经写到网络的字节数
trackInstantaneousMetric(STATS_METRIC_NET_OUTPUT,
server.stat_net_output_bytes);
}
// 服务器的LRU时间表示位数为24位,因此最长表示2^24秒,大约1.5年
// 只要在1.5年内,该对象被访问,那么就不会出现对象的LRU时间比服务器的时钟还要年轻的现象
// LRU_CLOCK_RESOLUTION 可以改变LRU时间的精度
// 获取服务器的LRU时钟
server.lruclock = getLRUClock();
// 更新服务器的最大内存使用量峰值
if (zmalloc_used_memory() > server.stat_peak_memory)
server.stat_peak_memory = zmalloc_used_memory();
// 更新常驻内存的大小
server.resident_set_size = zmalloc_get_rss();
// 安全的关闭服务器
if (server.shutdown_asap) {
// 关闭服务器前的准备动作,成功则关闭服务器
if (prepareForShutdown(SHUTDOWN_NOFLAGS) == C_OK) exit(0);
// 失败则打印日志
serverLog(LL_WARNING,"SIGTERM received but errors trying to shut down the server, check the logs for more information");
// 撤销关闭服务器标志
server.shutdown_asap = 0;
}
// 打印数据库的信息到日志中
run_with_period(5000) {
// 遍历数据库
for (j = 0; j < server.dbnum; j++) {
long long size, used, vkeys;
// 获取当前数据库的键值对字典的槽位数,键值对字典已使用的数量,过期键字典已使用的数量
size = dictSlots(server.db[j].dict);
used = dictSize(server.db[j].dict);
vkeys = dictSize(server.db[j].expires);
// 打印到日志中
if (used || vkeys) {
serverLog(LL_VERBOSE,"DB %d: %lld keys (%lld volatile) in %lld slots HT.",j,used,vkeys,size);
/* dictPrintStats(server.dict); */
}
}
}
// 如果服务器不在哨兵模式下,那么周期性打印一些连接client的信息到日志中
if (!server.sentinel_mode) {
run_with_period(5000) {
serverLog(LL_VERBOSE,
"%lu clients connected (%lu slaves), %zu bytes in use",
listLength(server.clients)-listLength(server.slaves),
listLength(server.slaves),
zmalloc_used_memory());
}
}
// 执行client的周期性任务
clientsCron();
// 执行数据库的周期性任务
databasesCron();
// 如果当前没有正在进行RDB和AOF持久化操作,且AOF重写操作被提上了日程,那么在后台执行AOF的重写操作
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 &&
server.aof_rewrite_scheduled)
{
rewriteAppendOnlyFileBackground();
}
// 如果正在进行RDB或AOF重写等操作,那么等待接收子进程发来的信息
if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 ||
ldbPendingChildren())
{
int statloc;
pid_t pid;
// 接收所有子进程发送的信号,非阻塞
if ((pid = wait3(&statloc,WNOHANG,NULL)) != 0) {
// 获取退出码
int exitcode = WEXITSTATUS(statloc);
int bysignal = 0;
// 判断子进程是否因为信号而终止,是的话,取得子进程因信号而中止的信号码
if (WIFSIGNALED(statloc)) bysignal = WTERMSIG(statloc);
// 子进程没有退出,还在进行RDB或AOF重写等操作
if (pid == -1) {
// 打印日志
serverLog(LL_WARNING,"wait3() returned an error: %s. "
"rdb_child_pid = %d, aof_child_pid = %d",
strerror(errno),
(int) server.rdb_child_pid,
(int) server.aof_child_pid);
// RDB持久化完成
} else if (pid == server.rdb_child_pid) {
// 将RDB文件写入磁盘或网络中
backgroundSaveDoneHandler(exitcode,bysignal);
// AOF持久化完成
} else if (pid == server.aof_child_pid) {
// 将重写缓冲区的命令追加AOF文件中,且进行同步操作
backgroundRewriteDoneHandler(exitcode,bysignal);
// 其他子进程,打印日志
} else {
if (!ldbRemoveChild(pid)) {
serverLog(LL_WARNING,
"Warning, detected child with unmatched pid: %ld",
(long)pid);
}
}
// 更新能否resize哈希的策略
updateDictResizePolicy();
}
// 没有正在进行RDB或AOF重写等操作,那么检查是否需要执行
} else {
// 遍历save命令的参数数组
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
// 数据库的键被修改的次数大于SAVE命令参数指定的修改次数,且已经过了SAVE命令参数指定的秒数
if (server.dirty >= sp->changes &&
server.unixtime-server.lastsave > sp->seconds &&
(server.unixtime-server.lastbgsave_try >
CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...",
sp->changes, (int)sp->seconds);
// 进行 BGSAVE 操作
rdbSaveBackground(server.rdb_filename);
break;
}
}
// 是否触发AOF重写操作
if (server.rdb_child_pid == -1 &&
server.aof_child_pid == -1 &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
// 上一次重写后的大小
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
// AOF文件增长的百分比
long long growth = (server.aof_current_size*100/base) - 100;
// 大于设置的百分比100则进行AOF后台重写
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
// 将AOF缓存冲洗到磁盘中
if (server.aof_flush_postponed_start) flushAppendOnlyFile(0);
// 当AOF重写操作,同样将重写缓冲区的数据刷新到AOF文件中
run_with_period(1000) {
if (server.aof_last_write_status == C_ERR)
flushAppendOnlyFile(0);
}
// 释放被设置为异步释放的client
freeClientsInAsyncFreeQueue();
// 解除client的暂停状态
clientsArePaused(); /* Don't check return value, just use the side effect. */
// 周期性执行复制的任务
run_with_period(1000) replicationCron();
/* Run the Redis Cluster cron. */
// 周期性执行集群任务
run_with_period(100) {
if (server.cluster_enabled) clusterCron();
}
//周期性执行哨兵任务
run_with_period(100) {
if (server.sentinel_mode) sentinelTimer();
}
// 清理过期的被缓存的sockets连接
run_with_period(1000) {
migrateCloseTimedoutSockets();
}
// 如果 BGSAVE 被提上过日程,那么进行BGSAVE操作,因为AOF重写操作在更新
// 注意:此代码必须在上面的replicationCron()调用之后,确保在重构此文件以保持此顺序时。
// 这是有用的,因为我们希望优先考虑RDB节省的复制
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1 &&
server.rdb_bgsave_scheduled &&
(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY ||
server.lastbgsave_status == C_OK))
{
// 更新执行BGSAVE,成功则清除rdb_bgsave_scheduled标志
if (rdbSaveBackground(server.rdb_filename) == C_OK)
server.rdb_bgsave_scheduled = 0;
}
// 周期loop计数器加1
server.cronloops++;
// 返回周期,默认为100ms
return 1000/server.hz;
}
Redis 服务器开启后,就会周期性执行此函数,直到 Redis 服务器关闭为止。默认每秒执行 10 次,平均 100ms 执行一次,可以在 Redis 配置文件的 hz 选项,调整该函数每秒执行的次数。
(1)server.hz
(2)run_with_period
# define run_with_period(_ms_) \
if ((_ms_ <= 1000/server.hz) || !(server.cronloops%((_ms_)/(1000/server.hz))))
定时任务执行都是在 10ms 的基础上定时处理自己的任务 run_with_period(ms),即调用 run_with_period(ms) 来确定自己是否需要执行。
返回 1 表示执行。 假如有一些任务需要每 500ms 执行一次,就可以在 serverCron 中用 run_with_period(500) 把每 500ms 需要执行一次的工作控制起来。
2.3 aeEventLoop
aeEventLoop 是整个事件驱动的核心,管理着文件事件表和时间事件列表,不断地循环处理着就绪的文件事件和到期的时间事件。
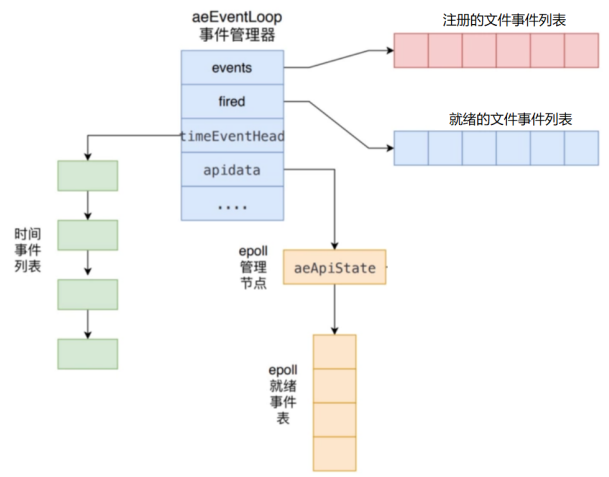
Redis 事件驱动框架对应的数据结构,在 ae.h 中定义,记录了运行过程信息,有 2 个记录事件的变量:
- IO 事件:aeFileEvent 类型的指针 *events;
- 时间事件:aeTimeEvent 类型的指针 *timeEventHead,按照一定时间周期触发的事件;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号